重温《JavaScript高级程序设计》—27-“新兴”的API
Nov 16, 2018前端js本篇内容
- requestAnimationFrame()
- Page Visibility API
- Geolocation(geographical location) API
- File API
- Web计时
- Web Workers
大家应该能够注意到,其中很多API都带有特定于浏览器的前缀,比如微软是ms,Firefox是moz,而Chrome和Safari是webkit。通过添加这些前缀,不同的浏览器可以测试还在开发中的新API,不过请记住,去掉前缀之后的部分在所有浏览器中都是一致的。
1 requestAnimationFrame()
很长时间以来,计时器和循环间隔一直都是JavaScript动画的最核心技术。虽然css变换及动画为Web开发人员提供了实现动画的简单手段,但JavaScript动面开发领域的状况这些年来并没有大的变化。Firefox4最早为JavaScript动画添加了一个新API,即mozRequestAnimationFrame()。这个方法会告诉浏览器:有一个动画开始了。进而浏览器就可以确定重绘的最佳方式。
1.1 早期动画循环
在JavaScript中创建动画的典型方式.就是使用setInterval()方法来控制所有动画。以下是一个使用setInterval()的基本动画循环:1
2
3
4
5
6function updateAnimation() {
doAnimation1();
doAnimation2();
}
setInterval(updateAnimation, 100);
为了创建一个小型动画库,updateAnimations()方法就得不断循环地运行每个动画,并相应地改变不同元素的状态(例如,同时显示一个新问跑马灯和一个进度条)。如果没有动画需要重新,这个方法可以退出,什么也不用处理,甚至可以把动画循环停下来,等待下一次需要更新的动画。
编写这种动画循环的关键是要知道延迟时间多长合适。一方面,循环间隔必须足够短,这样才能让不同的动画效果显得更平滑流畅;另一方面,循环间隔还要足够长,这样才能确保浏览器有能力渲染产生的变化。大多数电脑显示器的刷新频率是60Hz,大概相当于每秒钟重绘60次。大多数浏览器都会对重绘操作加以限制,不超过显示器的重绘频率,因为即使超过那个频率用户体验也不会有提升。
因此,最平滑动画的最佳循环间隔是1000ms/60,约等于17ms。以这个循环间隔重绘的动画是最平滑的,因为这个速度最接近浏览器的最高限速。为了适应17ms的循环间隔,多重动画可能需要加以节制,以便不会完成得太快。
虽然与使用多组setTimeout()的循环方式相比,使用setInterval()的动画循环效率更高,但后者也不是没有问题。无论是setInterval()还是setTimeout()都不十分精确。为它们传入的第二个参数,实际上只是指定了把动画代码添加到浏览器UI线程队列中以等待执行的时间。如果队列前面已经加入了其他任务,那动画代码就要等前面的任务完成后再执行。简言之,以毫秒表示的延迟时间并不代表到时候一定会执行动画代码,而仅代表到时候会把代码添加到任务队列中。如果UI线程繁忙,比如忙于处理用户操作,那么即使把代码加入队列也不会立即执行。
1.2 循环间隔的问题
知道什么时候绘制下一帧是保证动画平滑的关键。然而,直至最近,开发人员都没有办法确保浏览器按时绘制下一帧。随着<canvas>元素越来越流行,新的基于浏览器的游戏也开始崭露头脚,面对不十分精确的setInterval()和setTimeout(),开发人员一筹莫展。
浏览苦苦使用的计时器的精度进一步恶化了问题。具体地说,浏览器使用的计时器并非精确到毫秒级别。以下是几个浏览器的计时器精度。
- IE8及更早版本的计时器精度为15.625ms。
- IE9及更晚版本的计时器精度为4ms。
- Firefox和Safari的计时器精度大约为10ms。
- Chrome的计时器精度为4ms。
IE9之前版本的计时器精度为15.625ms,因此介于0和15之间的任何值只能是0和15。IE9把计时器精度提高到了4ms,但这个精度对于动画来说仍然不够明确。Chrome的计时器精度为4ms,而Firefox和Safari的精度是10ms。更为复杂的是,浏览器都开始限制后台标签页或不活动标签页的计时器。因此,即使你优化了循环间隔,结果仍然只能接近你想要的效果。
1.3 mozRequestAnimationFrame
Mozilla的Robert O’Callahan认识到了这个问题,提出了一个非常独特的方案。他指出,css变换和动画的优势在于浏览器知道动画什么时候开始,因此会计算出正确的循环间隔,在恰当的时候刷新UI。而对于JavaScript动画,浏览器无从知晓什么时候开始。因此他的方案就是创造一个新方法mozRequestAnimationFrame(),通过它告诉浏览器某些JavaScript代码将要执行动画。这样浏览器可以在运行某些代码后进行适当的优化。
mozRequestAnimationFrame()方法接收一个参数,即在重绘屏幕前调用的一个函数。这个函数负责改变下一次重绘时的DOM样式。为了创建动画循环,可以像以前使用setTimeout()一样,把多个对mozReguestAnimationFrame()的调用连缀起来。比如:1
2
3
4
5
6
7
8
9
10function updateProgress () {
var div = document.getElementById('status');
div.style.width = (parseInt(div.style.width, 10) + 5) + '%';
if (div.style.left != '100%') {
mozRequestAnimationFrame(updateProgress)
}
}
mozRequestAnimationFrame(updateProgress);
因为mozRequestAnimationFrame()只运行一次传入的函数,因此在需要再次修改UI从而生成动画时,需要再次手工调用它。同样,也需要同时考虑什么时候停止动画。这样就能得到非常平滑流畅的动画。
目前来看,mozRequestAnimationFrame()解决了浏览器不知道JavaScript动画什么时候开始、不知道最佳循环间隔时间的问题,但不知道代码到底什么时候执行的问题呢?同样的方案也可以解决这个问题。
我们传递的mozReguestAnimationFrame()函数也会接收一个参数,它是一个时间码(从1970年1月1日起至今的毫秒数),表示下一次重绘的实际发生时间。注意,这一点很重要:mozRequestAnimationFrame()会根据这个时间码设定将来的某个时刻进行重绘,而根据这个时间码,你也能知道那个时刻是什么时间。然后,再优化动画效果就有了依据。
要知道距离上一次重绘已经过去了多长时间,可以查询mozAnimationStartTime,其中包含上-次重绘的时间码。用传入回调函数的时间码减去这个时间码,就能计算出在屏幕上重绘下一组变化之前要经过多长时间。使用这个值的典型方式如下:1
2
3
4
5
6
7
8
9
10
11
12
13function draw(timestamp) {
var diff = timestamp - startTime; // 计算两次重绘的时间间隔
// 使用diff确定下一步的绘制时间
startTime = timestamp; // 把startTime重写为这一次的绘制时间
// 重绘UI
mozRequestAnimationFrame(draw);
}
var startTime = mozAnimationStartTime;
mozRequestAnimationFrame(draw);
这里的关键是第一次读取mozAnimationStartTime的值,必须在传递给mozRequestAnimationFrame()的回调函数外面进行。如果是在回调函数内部读取mozAnimationStartTime,得到的值与传入的时间码是相等的。
1.4 webkitRequestAnimationFrame与msRequestAnimationFrame
基于mozRequestAnimationFrame(),Chrome和IE10+也都给出了自己的实现,分别叫webkitRequestAnimationFrame()和msRequestAnimationFrame()。这两个版本与Mozilla的版本有两个方面的微小差异。首先,不会给回调函数传递时间码,因此你无法知道下一次重绘将发生在什么时间。 其次,Chrome又增加了第二个可选的参数,即将要发生变化的DOM元素。知道了重绘将发生在页面中哪个特定元素的区域内,就可以将重绘限定在该区域中。
既然没有下一次重绘的时间码,那Chrome和IE没有提供mozAnimationStartTime的实现也就很容易理解了——没有那个时间码,实现这个属性也没有什么用。不过,Chrome倒是又提供了另一个方法webkitCancelAnimationFrame(),用于取消之前计划执行的重绘操作。
假如你不需要知道精确的时间差,那么可以在Firefox4+、IE10+和Chrome中可以参考以下模式创建动画循环。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18function draw (timestamp) {
var drawStart = (timestamp || Date.now()),
diff = drawStart - startTime; // 计算两次重绘的时间间隔
// 使用diff确定下一步的绘制时间
startTime = timestamp; // 把startTime重写为这一次的绘制时间
// 重绘UI
requestAnimationFrame(draw);
}
var requestAnimationFrame = window.requestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.msRequestAnimationFrame;
var startTime = window.mozAnimationStartTime || Date.now();
requestAnimationFrame(draw);
以上模式利用已有的功能创建了一个动画循环,大致计算出了两次重绘的时间间隔。在Firefox中,计算时间间隔使用的是既有的时间码,而在Chrome和IE中,则使用不十分精确的Date对象。这个模式可以大致体现出两次重绘的时间间隔,但不会告诉你在Chrome和IE中的时间间隔到底是多少。不过,大致知道时间间隔总比一点儿概念也没有好些。
目前(2018-11-16)requestAnimationFrame()的兼容情况
可以看出移动端几乎无兼容性问题,PC兼容情况也很好,可以放肆使用。如果要保险起见,可以用如下兼容方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23let requestAnimationFrame;
if (typeof window !== 'undefined') {
requestAnimationFrame = window.requestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.msRequestAnimationFrame;
}
let createAnimationFrame = function () {
if (typeof requestAnimationFrame !== 'undefined') {
createAnimationFrame = function () {
return requestAnimationFrame;
};
return requestAnimationFrame;
} else {
return function (step, delay) {
setTimeout(function () {
let timeStamp = +new Date();
step(timeStamp);
}, delay);
}
}
};
2 Page Visibility API
不知道用户是不是正在与页面交互,这是困扰广大Web开发人员的一个主要问题。如果页面最小化了或者隐藏在了其他标签页后面,那么有些功能是可以停下来的,比如轮询服务器或者某些动画效果。而PageVisibility API(页面可见性API)就是为了让开发人员知道页面是否对用户可见而推出的。
这个API本身非常简单,由以下三部分组成。
document.hidden:表示页面是否隐藏的布尔值。页面隐藏包括页面在后台标签页中或者浏览器最小化。
document.visibilityState:表示下列4个可能状态的值。
- 页面在后台标签页中或浏览器最小化。
- 页面在前台标签页中。
- 实际的页面已经隐藏,但用户可以看到页面的预览(就像在Windows 7中用户把鼠标移动到任务栏的图标上,就可以显示浏览器中当前页面的预览)。
- 页面在屏幕外执行预渲染处理。
visibilitychange事件:当文档从可见变为不可见或从不可见变为可见时,触发该事件。IE的版本是在每个属性或事件前面加上ms前缀,而Chrome则是加上webkit前缀。因此document.hidden在IE的实现中就是document.msHidden,而在Chrome的实现中则是document.webkitHidden。检查浏览器是否支持这个API的最佳方式如下:1
2
3
4
5function isHiddenSupported () {
return typeof document.hidden ||
document.msHidden ||
document.webkitHidden != 'undefined'
}
类似地,使用同样的模式可以检测页面是否隐藏:1
2
3
4
5if (document.hidden || document.msHidden || document.webkitHidden) {
// 页面隐藏了
} else {
// 页面未隐藏
}
注意,以上代码在不支持该API的浏览器中会提示页面未隐藏。这是PageVisibility API有意设计的结果,目的是为了向后兼容。
为了在页面从可见变为不可见或从不可见变为可见时收到通知,可以侦听visibilitychange事件。在IE中,这个事件叫msvisibilitychange,而在Chrome中这个事件叫webkitvisibilitychange。为了在两个浏览器中都能侦听到该事件,可以像下面的例子一样,为每个事件都指定相同的事件处理程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function handleVisibilityChange () {
var output = document.getElementById('output');
var msg;
if (document.hidden || document.msHidden || document.webkitHidden) {
msg = 'Page is now hidden. ' + (new Date()) + '<br>';
} else {
msg = 'Page is now visible. ' + (new Date()) + '<br>';
}
output.innerHTML += msg;
}
EventUtil.addHandler(document, 'msvisibilitychange', handleVisibilityChange);
EventUtil.addHandler(document, 'webkitvisibilitychange', handleVisibilityChange);
以上代码同时适用于IE和Chrome。而且,API的这一部分已经相对稳定,因此在实际的Web开发中也可以使用以上代码。
关于这一API的实现,差异最大的是document.visibilityState属性。IE10 PR2的document.msVisibilityState是一个表示如下4种状态的数字值。
- (1)document.MS_PAGE_HIDDEN(0)
- (2)document.MS_PAGE_VISIBLE(1)
- (3)document.MS_PAGE_PREVIEW(2)
- (4)document.MS_PAGE_PRERENDER(3)
在Chrome中,document.webkitVisibilityState可能是下列3个字符串值:
- (1)”hidden”
- (2)”visible”
- (3)”prerender”
Chrome并没有给每个状态定义对应的常量,但最终的实现很可能会使用常量。
由于存在以上差异,所以建议大家先不要完全依赖带前缀的document.visibilityState,最好只使用document.hidden属性。
目前(2018-11-16)Page Visibility的兼容情况
可以看出移动端几乎无兼容性问题,PC兼容情况也很好,可以放肆使用。
3 Geolocation(geographical location) API
地理定位(geolocation)是最令人兴奋,而且得到了广泛支持的一个新功能。通过这套API,JavaScript代码能够访问到用户的当前位置信息。当然,访问之前必须得到用户的明确许可,即同意在页面中共享其位置信息。如果页面尝试访问地理定位信息,浏览器就会显示一个对话框,请求用户许可共享其位置信息。
GeolocationAPI在浏览器中的实现是navigator.geolocation对象,这个对象包含3个方法。第一个方法是getCurrentPosition(),调用这个方法就会触发请求用户共事地理定位信息的对话框。
这个方法接收3个参数:成功回调函数、可选的失败回调函数和可选的选项对象。
其中,成功回调函数会接收到一个Position对象参数,该对象有两个属性:coords和timestamp。而coords对象中将包含下列与位置相关的信息。
- latitude:以十进制度数表示的纬度。
- longitude:以十进制度数表示的经度。
- accuracy:经、纬度坐标的精度,以米为单位。
有些浏览器还可能会在coords对象中提供如下属性。 - altitude;以米为单位的海拔高度,如果设有相关数据则值为null。
- altitudeAccuracy:海拔高度的精度,以米为单位,数值越大越不精确。
- heading:指南针的方向,0表示正北,值为NaN表示没有检测到数据。
- speed:速度,即每秒移动多少米,如果没有相关数据则值为null。
在实际开发中,latitude和longitude是大多数Web应用最常用到的属性。例如,以下代码将在地图上绘制用户的位置:1
2
3navigator.geolocation.getCurrentPosition(function (position) {
drawMapCenteredAt(position.coords.latitude, position.coords.longitude)
});
以上介绍的是成功回调函数。getCurrentPosition()的第二个参数,即失败回调函数,在被调用的时候也会接收到一个参数。这个参数是一个对象,包含两个属性:message和code。其中,message属性中保存着给人肴的文本消息,解释为什么会出错,而code属性中保存着一个数值,表示错误的类型:用户拒绝共享(1)、位置无效(2)或者超时(3)。实际开发中,大多数Web应用只会将错误消息保存到日志文件中,而不一定会因此修改用户界面。例如:1
2
3
4
5
6navigator.geolocation.getCurrentPosition(function (position) {
drawMapCenteredAt(position.coords.latitude, position.coords.longitude)
}, function (error) {
console.log('Error code: ' + error.code);
console.log('Error message: ' + error.message);
})
getCurrentPosition()的第三个参数是一个选项对象,用于设定信息的类型。可以设置的选项有三个:enableHighAccuracy是一个布尔值,表示必须尽可能使用最准确的位置信息:timeout是以毫秒数表示的等待位置信息的最长时间;maximumAge表示上一次取得的坐标信息的有效时间,以毫秒表示,如果时间到则重新取得新坐标信息。例如:1
2
3
4
5
6
7
8
9
10navigator.geolocation.getCurrentPosition(function (position) {
drawMapCenteredAt(position.coords.latitude, position.coords.longitude)
}, function (error) {
console.log('Error code: ' + error.code);
console.log('Error message: ' + error.message);
}, {
enableHighAccuracy: true,
timeout: 5000,
maximumAge: 25000
});
这三个选项都是可选的,可以单独设置,也可以与其他选项一起设置。除非确实需要非常精确的信息,否则建议保持enableHighAccuracy的false值(默认值)。将这个选项设置为true需要更长的时候,而且在移动设备上还会导致消耗更多电量。类似地,如果不需要频繁更新用户的位置信息,那么可以将maximumAge设置为Infinity,从而始终都使用上一次的坐标信息。
如果你希望跟踪用户的位置,那么可以使用另一个方法watchPosition()。这个方法接收的参数与getCurrentPosition()方法完全相同。实际上,watchPosition()与定时调用getCurrentPosition()的效果相同。在第一次调用watchPosition()方法后,会取得当前位置,执行成功回调或者错误回调。然后,watchPosition()就地等待系统发出位置己改变的信号(它不会自己轮询位置)。
调用watchPosition()会返回一个数值标识符,用于跟踪监控的操作。基于这个返回值可以取消监控操作,只要将其传递给clearWatch()方法即可(与使用setTimeout()和clearTimeout()类似)。例如1
2
3
4
5
6
7
8var watchId = navigator.geolocation.watchPosition(function (position) {
drawMapCenteredAt(position.coords.latitude, position.coords.longitude)
}, function (error) {
console.log('Error code: ' + error.code);
console.log('Error message: ' + error.message);
});
clearWatch(watchId);
以上例子调用了watchPosition()方法,将返回的标识符保存在了watchId中。然后,又将watchId传给了clearWatch(),取消了监控操作。
目前(2018-11-16)Geolocation的兼容情况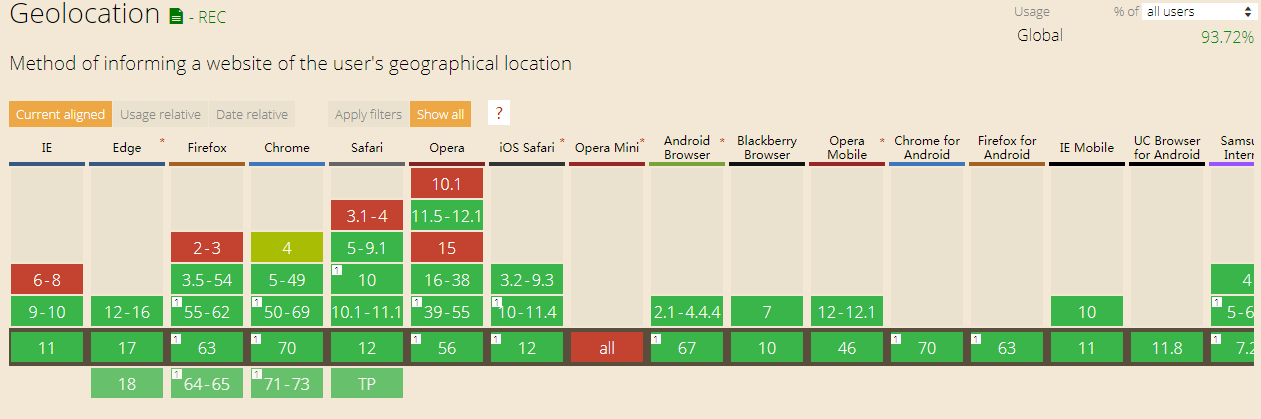
可以看出移动端几乎无兼容性问题,PC兼容情况也很好,可以放肆使用。
4 File API
不能直接访问用户讨算机中的文件,一直都是Web应用开发中的一大障碍。2000年以前,处理文件的唯一方式就是在表单中加入<input type="file"/>字段,仅此而已。File API(文件API)的宗旨是为Web开发人员提供一种安全的方式,以便在客户端访问用户计算机中的文件,并更好地对这些文件执行操作。
File API在表单中的文件输入字段的基础上,又添加了一些直接访问文件信息的接口。HTML5在DOM中为文件输入元素添加了一个files集合。在通过文件输入字段选择了一或多个文件时,files集合中将包含一组File对象,每个File对象对应着一个文件。每个File对象都有下列只读属性。
- name:本地文件系统中的文件名。
- size:文件的字节大小。
- type:字符串,文件的MIME类型。
- lastModifiedDate:字符串,文件上一次被修改的时间(只有Chrome实现了这个属性)。举个例子,通过侦听change事件并读取files集合就可以知道选择的每个文件的信息:
1
2
3
4
5
6
7
8
9
10
11var fileList = document.getElementById('files-list');
EventUtil.addHandler(fileList, 'change', function (event) {
var files = EventUtil.getTarget(event).files,
i = 0,
len = files.length;
while (i < len) {
console.log(files[i].name + ' ' + files[i].type + ' ' + files[i].size);
i++
}
})
这个例子把每个文件的信息输出到了控制台中。仅仅这一项功能。对Web应用开发来说就已经是非常大的进步了。不过,File API的功能还不止于此,通过它提供的FileReader类型甚至还可以读取文件中的数据。
4.1 FileReader类型
FileReader类型实现的是一种异步文件读取机制。可以把FileReader想象成XMLHttpRequest,区别只是它读取的是文件系统,而不是远程服务器。为了读取文件中的数据,FileReader提供了如下几个方法。
- readAsText(file, encoding):以纯文本形式读取文件,将读取到的文本保存在result属性中。第二个参数用于指定编码类型,是可选的。
- readAsDataURL(file):读取文件并将文件以Data URL的形式保存在result属性中。
- readAsBinaryString(file):读取文件并将一个字符串保存在result属性中,字符串中的每个字符表示一字节。
- readAsArrayBuffer(file) :读取文件并将一个包含文件内容的ArrayBuff er保存在result属性中。
这些读取文件的方法为灵活地处理文件数据提供了极大便利。例如,可以读取图像文件并将其保存为数据URI,以便将其显示给用户,或者为了解析方便,可以将文件读取为文本形式。
由于读取过程是异步的,因此FileReader也提供了几个事件。其中最有用的三个事件是progress、error和load,分别表示是否又读取了新数据、是否发生了错误以及是否已经读完了整个文件。
每过50ms左右,就会触发一次progress事件,通过事件对象可以获得与XHR的progress事件相同的信息(属性):lengthComputable、loaded和total。另外,尽管可能没有包含全部数据,但每次progress事件中都可以通过FileReader的result属性读取到文件内容。
由于种种原因无法读取文件,就会触发error事件。触发error事件时,相关的信息将保存到FileReader的error属性中。这个属性中将保存一个对象,该对象只有一个属性code,即错误码。这个错误码是1表示未找到文件,是2表示安全性错误,是3表示读取中断.是4表示文件不可读,是5表示编码错误。
文件成功加载后会触发load事件;如果发生了error事件,就不会发生load事件。以下是一个使用上述三个事件的例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40var filesList = document.getElementById('files-list');
EventUtil.addHandler(fileList, 'change', function (event) {
var info = '',
output = document.getElementById('output');
progress = document.getElementById('progress'),
files = EventUtil.getTarget(event).files,
type = 'default',
reader = new FileReader();
if (/image/.test(files[0].type)) {
reader.readAsDataURL(files[0]);
type = 'image';
else {
reader.readAsText(files[0]);
type = 'text';
}
reader.onerror = function () {
output.innerHTML = 'Could not read file, error code is ' + reader.error.code;
};
reader.onprogress = function (event) {
if (event.lengthComputable) {
progress.innerHTML = event.loaded + '/' + event.total;
}
};
reader.onload = function () {
var html = '';
switch (type) {
case 'image':
html = '<img src="' + reader.result + '">';
break;
case 'text':
html = reader.result;
break;
}
output.innerHTML = html;
};
})
这个例子读取了表单字段中选择的文件,并将其内容显示在了页面中。如果文件有MIMI类型,表示文件是图像,因此在load事件中就把它保存为数据URI,并在页面中将这幅图像显示出来。如果文件不是图像,则以字符串形式读取文件内容,然后如实在页面中显示读取到的内容。这里使用了progress事件来跟踪读取了多少字节的数据,而error事件则用于监控发生的错误。
如果想中断读取过程,可以调用abort()方法,这样就会触发abort事件。在触发load、error或abort事件后,会触发另一个事件loadend。loadend事件发生就意味着已经读取完整个文件,或者读取时发生了错误,或者读取过程被中断。
实现File API的所有浏览器都支持readAsText()和readAsDataURL()方法。但IE10 PR2并未实现readAsBinaryString()和readAsArrayBuffer()方法。
目前(2018-11-16)filereader的兼容情况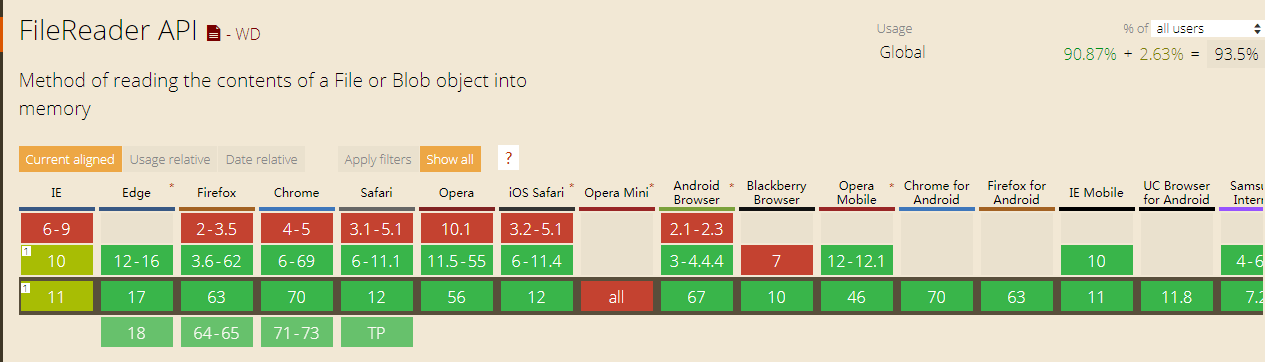
4.2 读取部分内容
有时候,我们只想读取文件的一部分而不是全部内容。为此,File对象还支持一个slice()方法,这个方法在Firefox中的实现叫mozSlice(),在Chrome中的实现叫webkitSlice(),Safari的5.1及之前版本不支持这个方法。slice()方法接收两个参数:起始字节及要读取的字节数。这个方法返回一个Blob的实例,Blob是File类型的父类型。下面是一个通用的函数,可以在不同实现中使用slice()方法:1
2
3
4
5
6function blobSlice(blob, startByte, length) {
if (blob.slice) return blob.slice(startByte, length);
if (blob.webkitSlice) return blob.webkitSlice(startByte, length);
if (blob.mozSlize) return blob.mozSlize(startByte, length);
return null
}
Blob类型有一个size属性和一个type属性,而且它也支持slice()方法,以便进一步切割数据。通过FileReader也可以从Blob中读取数据。下面这个例子只读取文件的32B内容。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23var filesList = document.getElementById('files-list');
EventUtil.addHandler(filesList, 'change', function (event) {
var info = '',
output = document.getElementById('output'),
progress = document.getElementById('progress'),
files = EventUtil.getTarget(event).files,
reader = new FileReader(),
blob = blobSlice(files[0], 0, 32);
if (blob) {
reader.readAsText(blob);
reader.onerror = function () {
output.innerHTML = 'Could not read file, error code is' + reader.error.code;
};
reader.onload = function () {
output.innerHTML = reader.result;
};
} else {
alert('Your brower doesn\'t support slice().');
}
})
只读取文件的一部分可以节省时间,非常适合只关注数据中某个特定部分(如文件头部)的情况。
4.3 对象URL
对象URL也被称为blob URL,指的是引用保存在File或Blob中数据的URL。使用对象URL的好处是可以不必把文件内容读取到JavaScript中而直接使用文件内容。为此,只要在需要文件内容的地方提供对象URL即可。要创建对象URL,可以使用window.URL.createObjectURL()方法,并传入File或Blob对象。这个方法在Chrome中的实现叫window.webkitURL.createObjectURL(),因此可以通过如下函数来消除命名的差异:1
2
3
4
5
6
7function createObjectURL (blob) {
if (window.URL) {
return window.URL.createObjectURL(blob);
} else if (window.webkitURL) {
return window.webkitURL.createObjectURL(blob);
} else return null;
}
这个函数的返回值是一个字符串,指向一块内存的地址。因为这个字符串是URL,所以在DOM中也能使用。例如,以下代码可以在页面中显示一个图像文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var filesList = document.getElementById('files-list');
EventUtil.addHandler(filesList, 'change', function (event) {
var info = '',
output = document.getElementById('output'),
progress = document.getElementById('progress'),
files = EventUtil.getTarget(event).files,
reader = new FileReader(),
url = createObjectURL(files[0]);
if (url) {
if (/image/.test(files[0].type)) {
output.innerHTML = '<img src="' + url + '">';
} else output.innerHTML = 'Not an image.';
} else {
alert('Your brower doesn\'t support URLs.');
}
})
直接把对象URL放在<img>标签中,就省去了把数据先读到JavaScript中的麻烦。另一方面,<img>标签则会找到相应的内存地址,直接读取数据并将图像显示在页面中。
如果不再需要相应的数据,最好释放它占用的内容。但只要有代码在引用对象URL,内存就不会释放。要手工释放内存,可以把对象URL传给window.URL.revokeOjbectURL()(在Chrome中是window.webkitURL.revokeObjectURL())。要兼容这两种方法的实现,可以使用以下函数:1
2
3
4
5
6
7function revokeObjectURL(url) {
if (window.URL) {
window.URL.revokeObjectURL(url);
} else if (window.webkitURL) {
window.webkitURL.revokeObjectURL(url);
}
}
页面卸载时会自动释放对象URL占用的内存。不过,为了确保尽可能少地占用内存,最好在不需要某个对象URL时,就马上手工释放其占用的内存。
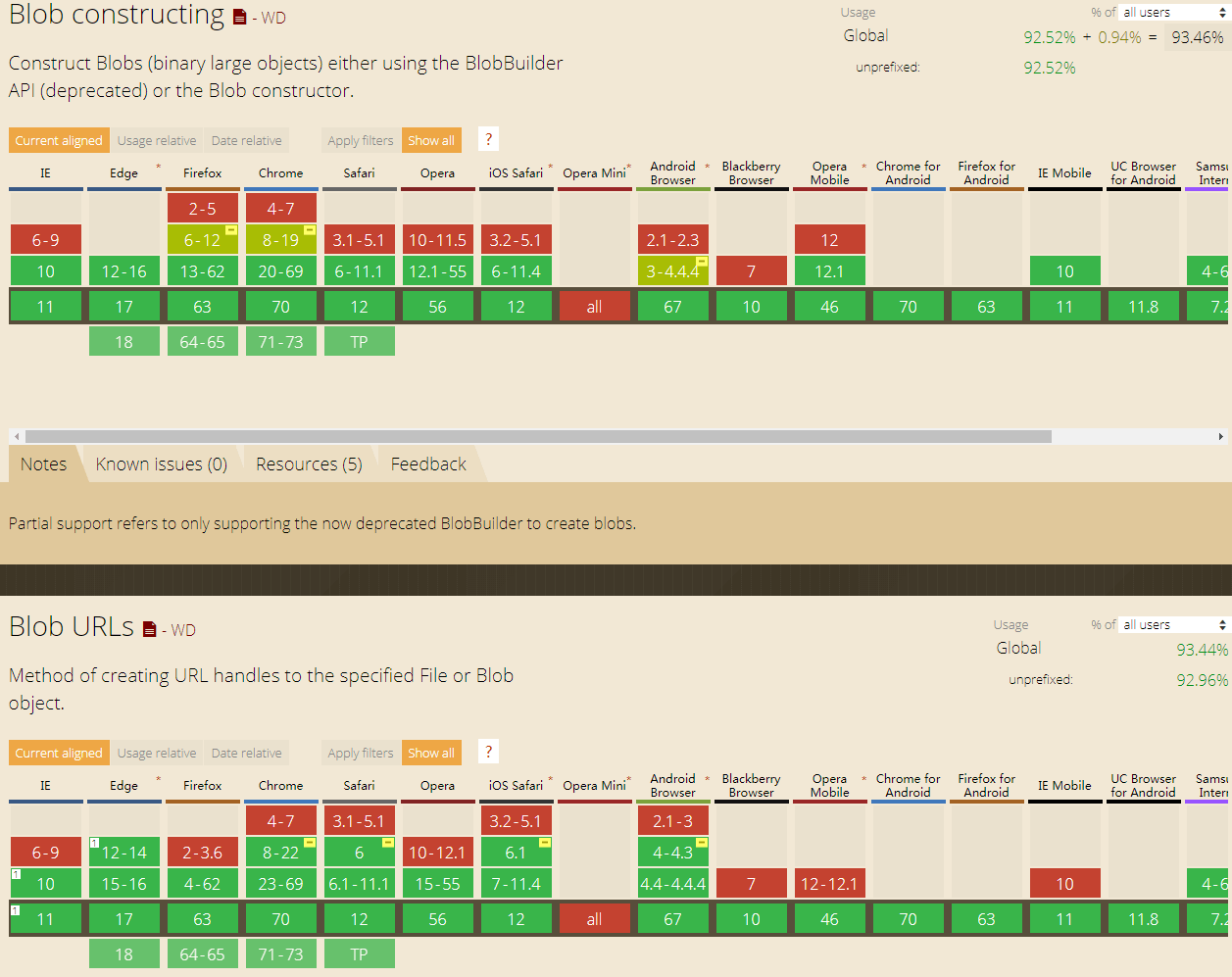
4.4 读取拖放的文件
围绕读取文件信息,结合使用HTML5拖放API和文件API,能够创造出令人瞩目的用户界面:在页面上创建了自定义的放置目标之后,你可以从桌面上把文件拖放到该目标。与拖放一张图片或者一个链接类似,从桌面上把文件拖放到浏览器中也会触发drop事件。而且可以在event.dataTransfer.files中读取到被放置的文件,当然此时它是一个File对象,与通过文件输入字段取得的File对象-样。
下面这个例子会将放置到页面中自定义的放置目标中的文件信息显示出来:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29var droptarget = document.getElementById('droptarget');
function handleEvent (event) {
var info = '',
output = document.getElementById('output'),
files,
i,
len;
EventUtil.preventDefatul(event);
if (event.type === 'drop') {
files = event.dataTransfer.files;
i = 0;
len = files.length;
while (i < len) {
info += files[i].name + ' (' + files[i].type + ', ' + files[i].size + ' bytes)<br>';
i++;
}
output.innerHTML = info;
}
}
EventUtil.addHandler(droptarget, 'dragenter', handleEvent);
EventUtil.addHandler(droptarget, 'dragover', handleEvent);
EventUtil.addHandler(droptarget, 'drop', handleEvent);
与之前展示的拖放示例-样,这里也必须取消dragenter、dragover和drop的默认行为。在drop事件中,可以通过event.dataTransfer.files读取文件信息。还有一种利用这个功能的流行做法,即结合XMLHttpRequest和拖放文件来实现上传。
4.5 使用XHR上传文件
通过FileAPI能够访问到文件内容,利用这一点就可以通过XHR直接把文件上传到服务器。当然啦,把文件内容放到send()方法中,再通过POST请求,的确很容易就能实现上传。但这样做传递的是文件内容,因而服务器端必须收集提交的内容,然后再把它们保存到另一个文件中。其实,更好的做法是以表单提交的方式来上传文件。
这样使用FormData类型就很容易做到了。首先,要创建一个FormData对象,通过它调用append()方法并传人相应的File对象作为参数。然后,再把FormData对象传递给XHR的send()方法,结果与通过表单上传一模一样。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39var droptarget = document.getElementById('droptarget');
function handleEvent (event) {
var info = '',
output = document.getElementById('output'),
files,
i,
len;
var data,
xhr;
EventUtil.preventDefatul(event);
if (event.type === 'drop') {
data = new FormData();
files = event.dataTransfer.files;
i = 0;
len = files.length;
while (i < len) {
data.append('file' + i, files[i]);
i++;
}
xhr = new XMLHttpRequest();
xhr.open('post', 'test.php'. true);
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
alert(xhr.respenseText);
}
};
xhr.send(data);
}
}
EventUtil.addHandler(droptarget, 'dragenter', handleEvent);
EventUtil.addHandler(droptarget, 'dragover', handleEvent);
EventUtil.addHandler(droptarget, 'drop', handleEvent);
这个例子创建一个FormData对象,与每个文件对应的键分别是file0、file1,file2这样的格式。注意,不用额外写任何代码,这些文件就可以作为表单的值提交。而且,也不必使用FileReader, 只要传入File对象即可。
使用FormData上传文件,在服务器端就好像是接收到了常规的表单数据一样,一切按部就班地处理即可。换句话说,如果服务器端使用的是PHP,那么$_FILES数组中就会保存着上传的文件。

5 Web计时
页面性能一直都是Web开发人员最关注的领域。但直到最近,度量页面性能指标的唯一方式,就是提高代码复杂程度和巧妙地使用JavaScript的Date对象。WebTiming API改变了这个局面,让开发人员通过JavaScript就能使用浏览器内部的度量结果,通过直接读取这些信息可以做任何想傲的分析。与本章介绍过的其他API不同,WebTiming API实际上已经成为了W3C的建议标准,只不过目前支持它的浏览器还不够多。
Web计时机制的核心是window.performance对象。对页面的所有度量信息,包括那些规范中已经定义的和将来才能确定的,都包含在这个对象里面。WebTiming规范一开始就为performance对象定义了两个属性。
其中,perfonnance.navigation属性也是一个对象,包含着与页面导航有关的多个属性,如下所示。
- redirectCount:页面加载前的重定向次数。
- type:数值常量,表示刚刚发生的导航类型。
– performance.navigation.TYPE_NAVIGATE(0):页面第一次加载。
– performance.navigation.TYPE_RELOAD(1):页面重载过。
– performance.navigation.TYPE_BACK_FORWARD(2):页面是通过“后退”或“前进”按钮打开的。
另外,performance.timing属性也是一个对象,但这个对象的属性都是时间戳(从软件纪元开始经过的毫秒数),不同的事件会产生不同的时间值。这些属性如下所示。
- navigationStart:开始导航到当前页面的时间。
- unloadEventStart:前一个页面的unload事件开始的时间。但只有在前一个页面与当前页面来自同一个域时这个属性才会有值;否则,值为0。
- unloadEventEnd:前一个页面的unload事件结束的时间。但只有在前一个页面与当前页面来自同一个域时这个属性才会有值;否则,值为0。
- redirectStart:到当前页面的重定向开始的时间。但只有在重定向的页面来自同一个域时这个属性才会有值;否则,值为0。
- redirectEnd:到当前页面的重定向结束的时间。但只有在重定向的页面来自同一个城时这个属性才会有值;否则,值为O。
- fetchStart:开始通过HTTP GET取得页面的时间。
- domainLookupstart:开始查询当前页面DNS的时间。
- domainLookupEnd:查询当前页面DNS结束的时间。
- connectStart:浏览器尝试连接服务器的时间。
- connectEnd:浏览器成功连接到服务器的时间。
- recureConnectionStart:由浏览器成功连接到服务器的时间。不适用SSL方式连接时,这个属性的值为0。
- requestStart:浏览器开始请求页面的时间。
- responseStart:浏览器接收到页面第一字节的时间。
- responseEnd:浏览器接收到页面所有内容的时间。
- domLoading: document.readyState变为”loading“的时间。
- domInteractive: document.readyState变为”interactive“的时间。
- domContentLoadedEventStart:发生DOMContentLoaded事件的时间。
- domContentLoadedEventEnd: DOMContentLoaded事件已经发生且执行完所有事件处理程序的时间。
- domComplete: docwnent.readyState变为”complete”的时间。
- loadEventStart:发生load事件的时间。
- loadEventEnd: load事件已经发生且执行完所有事件处理程序的时间。
通过这些时间值,就可以全面了解页面在被加载到浏览攒的过程中都经历了哪些阶段,而哪些阶段可能是影响性能的瓶颈。给大家推荐一个使用WebTiming API的绝好示例,地址是 http://webtimingdemo.appspot.com/。
兼容:IE10+和Chrome,移动待确认。
6 Web Workers
随着Web应用复杂性的与日俱增,越来越复杂的计算在所难免。长时间运行的JavaScript进程会导致浏览器冻结用户界面,让人感觉屏幕“冻结”了。Web Workers规范通过让JavaScript在后台运行解决了这个问题。浏览器实现Web Workers规范的方式有很多种,可以使用线程、后台进程或者运行在其他处理器核心上的进程,等等。具体的实现细节其实没有那么重要,重要的是开发人员现在可以放心地运行JavaScript,而不必担心会影响用户体验了。
6.1 使用Worker
实例化Worker对象并传入要执行的JavaScript文件名就可以创建一个新的WebWorker。例如:1
var worker = new Worker('stufftodu.js');
这行代码会导致浏览器下载stufftodo.js,但只有Worker接收到消息才会实际执行文件中的代码。要给Worker传递消息,可以使用postMessage()方法(与XDM的postMessage()方法类似):1
worker.postMessage('start!');
消息内容可以是任何能够被序列化的值,不过与XDM不同的是,在所有支持的浏览器中,postMessage()都能接收对象参数(Safari4是支持WebWorkers的浏览器中最后一个只支持字符串参函数的)。因此,可以随便传递任何形式的对象数据,如下面的例子所示:1
2
3
4worker.postMessage({
type: 'command',
message: 'start!'
});
一般来说,可以序列化为JSON结构的任何值都可以作为参数传递给postMessage()。换句话说,这就意味着传入的值是被复制到Worker中,而非直接传过去的(与XDM类似)。
Worker是通过message和error事件与页面通信的。这里的message事件与XDM中的message事件行为相同,来自Worker的数据保存在event.data中。Worker返回的数据也可以是任何能够被序列化的值:1
2
3
4
5worker.onmessage = function (event) {
var data = event.data;
// ...
};
Worker不能完成给定的任务时会触发error事件。具体来说,Worker内部的JavaScript在执行过程中只要遇到错误,就会触发error事件。发生error事件时,事件对象中包含三个属性:filename、lineno和message,分别表示发生错误的文件名、代码行号和完整的错误消息。1
2
3worker.onerror = function (event) {
console.log('ERROR: ' + event.filename + ' (' + event.lineno + ');' + event.message);
}
建议大家在使用WebWorkers时,始终都要使用onerror事件处理程序,即使这个函数(像上面例子所示的)除了把错误记录到日志中什么也不做都可以。否则,Worker就会在发生错误时,悄无声息地失败了。
任何时候,只要调用terminate()方法就可以停止Worker的工作。而且,Worker中的代码会立即停止执行,后续的所有过程都不会再发生(包括error和message事件也不会再触发)。1
worker.terminate();
6.2 Worker 全局件用域
关于WebWorker,最重要的是要知道它所执行的JavaScript代码完全在另一个作用域中,与当前网页巾的代码不共享作用域。在WebWorker中,同样有一个全局对象和其他对象以及方法。但是,Web Worker中的代码不能访问DOM,也无法通过任何方式影响页面的外观。
Web Worker中的全局对象是worker对象本身。也就是说,在这个特殊的全局作用域中,this和self引用的都是worker对象。为便于处理数据,WebWorker本身也是一个最小化的运行环境。
- 最小化的navigator对象,包括onLine、appName、appVersion、userAgent和platform属性;
- 只读的location对象;
- setTimeout()、setInterval()、clearTimeout()和clearInterval()方法;
- XMLHttpRequest构造函数。
显然,Web Worker的运行环境与页面环境相比,功能是相当有限的。
当页而在worker对象上调用postMessage()时,数据会以异步方式被传递给worker,进而触发worker中的message事件。为了处理来自页面的数据,同样也需要创建一个onmessage事件处理程序。1
2
3
4
5self.onmessage = function (event) {
var data = event.data;
// ...
}
大家看清楚,这里的self引用的是Worker全局作用域中的worker对象(与页面中的Worker对象不同一个对象)。Worker完成工作后,通过调用postMessage()可以把数据再发回页面。例如,下面的例子假设需要Worker对传入的数组进行排序,而Worker在排序之后又将数组发回了页面:1
2
3
4
5
6
7
8self.onmessage = function (event) {
var data = event.data;
data.sort(function (a, b) {
return a - b;
});
self.postMessage(data);
}
传递消息就是页面与Worker相互之间通信的方式。在Worker中调用postMessage ()会以异步方式触发页面中Worker实例的message事件。如果页面想要使用这个Worker,可以这样:1
2
3
4
5
6
7
8
9
10var data = [1, 34, 43, 43, 22, 1];
var worker = new Worker('webwork.js');
worker.onmessage = function (event) {
var data = event.data;
// ..
}
worker.postMessage(data);
排序的确是比较消括时间的操作,因此转交给Worker做就不会阻塞用户界面了。 另外,把彩色图像转换成灰阶图像以及加密解密之类的操作也是相当费时的。
在Worker内部,调用close()方法也可以停止工作。就像在页面中调用terminate ()方法一样,Worker停止工作后就不会再有事件发生了。1
self.close();
6.3 包含其他脚本
既然无法在Worker中动态创建新的<script>元素,那是不是就不能向Worker中添加其他脚本了呢?不是,Worker的全局作用域提供这个功能,即我们可以调用importScripts()方法。这个方法接收一个或多个指向JavaScript文件的URL。每个加载过程都是异步进行的,因此所有脚本加载并执行之后,importScripts()才会执行。 例如:1
2// in web worker's code
importScripts('file1.js', 'file2.js');
即使file2.js先于file1.js下载完,执行的时候仍然会按照先后顺序执行。而且,这些脚本是在Worker的全局作用域中执行,如果脚本中包含与页面有关的JavaScript代码,那么脚本可能无法正确运行。请记住,Worker中的脚本一般都具有特殊的用途,不会像页面中的脚本那么功能宽泛。
6.4 Web Workers的未来
Web Workers规范还在继续制定和改进之中。本节所讨论的 Worker目前被称为 “专用Worker” (dedicated worker),因为它们是专门为某个特定的页面服务的,不能在页面间共事。该规范的另外一个概念是 “共享Worker” (shared worker),这种Worker可以在浏览器的多个标签中打开的同一个页面间共事。 虽然Safari5、Chrome和Opera10.6都实现了共享Worker,但由于该规范尚未完稿,因此很可能还会有变动。
另外,关于在Worker内部能访问什么不能访问什么,到如今仍然争论不休。有人认为Worker应该像页面一样能够访问任意数据,不光是XHR,还有localStroage、sessionStorage、IndexedDB、Web Sockets、Server-Send Events等。好像支持这个观点的人更多一些,因此未来的Worker全局作用城很可能会有更大的空间。


温习:
- 各浏览器的requestAnimationFrame();
- document.hidden、document.visibilityState、visibilitychange事件;
- 地理位置功能,navigator.geolocation对象;
- File API、Blob、对象URL
- window.performance对象
- Web Worker及简单使用
(完)
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com