【笔记】nodejs随手记(持续)
Apr 1, 2019笔记jsnodejsnodejs 随手记(持续)
- start date: 2018-08-27 13:00:45
基本
结构
nodejs 是一个基于 Chrome V8 引擎的 js 运行环境。nodejs 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量级又高效。
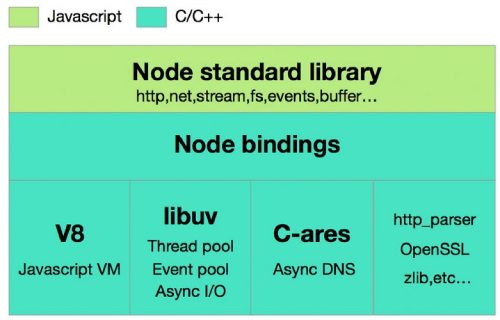
Node.js 标准库,这部分是由 Javascript 编写的,即我们使用过程中直接能调用的 API。在源码中的 lib 目录下可以看到。Node bindings,这一层是 Javascript 与底层 C/C++ 能够沟通的关键,前者通过 bindings 调用后者,相互交换数据。实现在 http://node.cc,这一层是支撑 Node.js 运行的关键,由 C/C++ 实现。V8:Google 推出的 Javascript VM,也是 Node.js 为什么使用的是 Javascript 的关键,它为 Javascript 提供了在非浏览器端运行的环境,它的高效是 Node.js 之所以高效的原因之一。Libuv:跨平台,是自行开发的,拓展了 js 的能力,使得 js 既可以在前端进行 DOM 操作又可以在后端调用操作系统资源(线程池,事件池,异步 I/O 等),是 Node.js 如此强大的关键。C-ares:提供了异步处理 DNS 相关的能力。http_parser、OpenSSL、zlib 等:提供包括 http 解析、SSL、数据压缩等其他的能力。
特点
- 事件驱动
- 非阻塞 IO 模型(异步)
- 轻量和高效
npm
镜像及切换
常用镜像:
- 官方:https://registry.npmjs.org/
- 淘宝:https://registry.npmmirror.com (原:http://registry.npm.taobao.org/,2022年起废弃)
- cnpm:http://r.cnpmjs.org/
切换
临时切换镜像安装
1 | npm --registry 镜像源 install 安装包 |
如
1 | npm --registry https://registry.npm.taobao.org install webpack |
永久切换
1 | npm config set registry 镜像源 |
如
1 | npm config set registry http://r.cnpmjs.org/ |
linux 部署环境
- 1.下载包,如:
node-v8.2.1-linux-x64.tar.xz - 2.解压包,
1 | tar -xvf node-v8.2.1-linux-x64.tar.xz |
检查node-v8.2.1-linux-x64目录下是否包含 bin 目录。
- 3.建立软连接,(如目录地址为/var/www/html/node-v8.2.1-linux-x64)
1 | ln -s /var/www/html/node-v8.2.1-linux-x64/bin/npm /usr/loacl/bin/ |
检查:
1 | node -v |
- 4.添加全局变量,以确保 npm 全局安装,如
1 | export PATH=NODE_HOME=/var/www/html/node-v8.2.1-linux-x64/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:$PATH |
或修改/etc/profile 文件,末尾输入上述命令。
检查:
1 | npm i -g cnpm |
1 文件系统
文件读取
普通读取 fs.readFileSync()(同步)/fs.readFile()(异步)
通过文件流读取
适合大文件读取
1 | const fs = require('fs'); |
文件写入
普通写入 fs.writeFileSync()(同步)/fs.writeFile()(异步)
通过文件流写入
1 | const fs = require('fs'); |
文件是否存在/文件或目录的用户权限
fs.access()(异步)
1 | const file = 'package.json'; |
fs.accessSync()(同步)
1 | try { |
创建目录 fs.mkdirSync()(同步)/fs.msdir()(异步)
删除文件
fs.unlinkSync()(同步)
1 | const fs = require('fs'); |
fs.unlink()(异步)
1 | const fs = require('fs'); |
遍历目录
fs.readdirSync()很坑。。。要读取所有子文件必须遍历
1 | const fs = require('fs'); |
文件重命名
fs.rename()(异步)
1 | const fs = require('fs'); |
fs.renameSync()(异步)
1 | const fs = require('fs'); |
监听文件修改
*fs.watch()比 fs.watchFile()高效。
fs.watchFile()
实现原理:轮询。每隔一段时间检查文件是否发生变化。所以在不同平台上表现基本是一致的。
1 | const fs = require('fs'); |
fs.watch()
1 | const fs = require('fs'); |
*修改所有者 fs.chmodSync()(同步)/fs.chmod()(异步)
获取文件状态
fs.stat()、fs.fstat()、fs.lstat()。
fs.stat()和 fs.fstat():传文件路径 vs 文件句柄。
fs.stat()和 fs.lstat():如果文件是软链接,那么 fs.stat()返回目标文件的状态,fs.lstat()返回软链接本身的状态。
追加文件内容 fs.appendFileSync()(同步)/fs.appendFile()(异步)
*文件内容截取 fs.truncate()、fs.ftruncate()
*修改文件属性(时间)fs.utimes()、fs.futimes()
*创建文件链接 fs.symlink()、fs.symlinkSync()、fs.link()、fs.linkSync()
软链接和硬链接:
- 硬链接:inode 相同,多个别名。删除一个硬链接文件,不会影响其他有相同 inode 的文件。
- 软链接:有自己的 inode,用户数据块存放指向文件的 inode。
创建临时目录
1 | const fs = require('fs'); |
删除目录 fs.rmdirSync()(同步)/fs.rmdir()(异步)
2 开启 gzip
zlib 模块(内置)
zlib 模块提供通过 Gzip 和 Deflate/Inflate 实现的压缩功能,可以通过这样使用它:
1 | const zlib = require('zlib'); |
压缩范例:
1 | const fs = require('fs'); |
解压范例:
1 | const fs = require('fs'); |
服务端 gzip 压缩
判断是否包含 accept-encoding 首部,且值为 gzip。是则返回 gzip 压缩后的文件,否将返回未压缩的文件。
1 | const fs = require('fs'); |
服务端字符串 gzip 压缩
方案:使用 zlib.gzipSync()方法对字符串进行 gzip 压缩。
如:
1 | const http = require('http'); |
3 域名解析
dns.lookup()
如
1 | const dns = require('dns'); |
获取一个域名对应的多个 ip
1 | const dns = require('dns'); |
dns.resolve4()
1 | const dns = require('dns'); |
dns.lookup()和 dns.resolve4()
当配置了本地 Host 时,dns.lookup()方法会返回 host 的 ip 地址,dns.resolve4()无影响。
4 事件循环机制
Node.js 是基于 V8 引擎的 javascript 运行环境. Node.js 具有事件驱动, 非阻塞 I/O 等特点. 结合 Node API, Node.js 具有网络编程, 文件系统等服务端的功能, Node.js 用 libuv 库进行异步事件处理。
4.1 线程
Node.js 的单线程含义, 实际上说的是执行同步代码的主线程. 一个 Node 程序的启动, 不止是分配了一个线程,而是我们只能在一个线程执行代码. 当出现 I/O 资源调用, TCP 连接等外部资源申请的时候, 不会阻塞主线程, 而是委托给 I/O 线程进行处理,并且进入等待队列。 一旦主线程执行完成,将会消费事件队列(Event Queue)。 因为只有一个主线程, 只占用 CPU 内核处理逻辑计算, 因此不适合在 CPU 密集型进行使用。
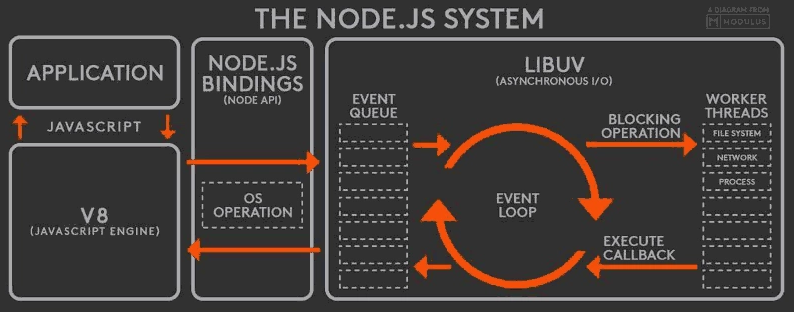
什么是事件循环(EventLoop) ?
EventLoop 是一种常用的机制,通过对内部或外部的事件提供者发出请求, 如文件读写, 网络连接 等异步操作, 完成后调用事件处理程序. 整个过程都是异步阶段
Node.js 的事件循环机制指当 Node.js 启动, 就会初始化一个 event loop, 处理脚本时, 可能会发生异步 API 行为调用, 使用定时器任务或者 nexTick, 处理完成后进入事件循环处理过程。
事件循环阶段
1 | ┌───────────────────────┐ |
每一个阶段都有一个 FIFO 的 callbacks 队列, 每个阶段都有自己的事件处理方式. 当事件循环进入某个阶段时, 将会在该阶段内执行回调,直到队列耗尽或者回调的最大数量已执行, 那么将进入下一个处理阶段.
- timers 阶段: 这个阶段执行 setTimeout(callback) and setInterval(callback)预定的 callback;
- I/O callbacks 阶段: 执行除了 close 事件的 callbacks、被 timers(定时器,setTimeout、setInterval 等)设定的 callbacks、setImmediate()设定的 callbacks 之外的 callbacks; (目前这个阶段)
- idle, prepare 阶段: 仅 node 内部使用;
- poll 阶段: 获取新的 I/O 事件, 适当的条件下 node 将阻塞在这里;
- check 阶段: 执行 setImmediate() 设定的 callbacks;
- close callbacks 阶段: 比如 socket.on(‘close’, callback)的 callback 会在这个阶段执行.
5 CommonJS 和 ES6 模块的区别
- require 支持 动态导入,import 不支持,正在提案 (babel 下可支持)
- require 是 同步 导入,import 属于 异步 导入
- require 是 值拷贝,导出值变化不会影响导入值;import 指向内存地址,导入值会随导出值而变化
5.1 CommonJS
- 通过 require 引入基础数据类型时,属于复制该变量。即会被模块缓存。同时,在另一个模块可以对该模块输出的变量重新赋值。
- 通过 require 引入复杂数据类型时,数据浅拷贝该对象。由于两个模块引用的对象指向同一个内存空间,因此对该模块的值做修改时会影响另一个模块。
- 当使用 require 命令加载某个模块时,就会运行整个模块的代码。
- 当使用 require 命令加载同一个模块时,不会再执行该模块,而是取到缓存之中的值。也就是说,CommonJS 模块无论加载多少次,都只会在第一次加载时运行一次,以后再加载,就返回第一次运行的结果,除非手动清除系统缓存。
- 循环加载时,属于加载时执行。即脚本代码在 require 的时候,就会全部执行。一旦出现某个模块被”循环加载”,就只输出已经执行的部分,还未执行的部分不会输出。
5.2 ES6 模块
- ES6 模块中的值属于【动态只读引用】。
- 对于只读来说,即不允许修改引入变量的值,import 的变量是只读的,不论是基本数据类型还是复杂数据类型。当模块遇到 import 命令时,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。
- 对于动态来说,原始值发生变化,import 加载的值也会发生变化。不论是基本数据类型还是复杂数据类型。
- 循环加载时,ES6 模块是动态引用。只要两个模块之间存在某个引用,代码就能够执行。
上面说了一些重要区别。
6 Fork 与子进程
nodejs 自带的 child_process 模块有一个 fork 方法,可以用于创建子进程。
语法:
1 | child_process.fork(modulePath[, args][, options]) |
注意:
- 1、该接口专门用于衍生新的 Node.js 进程
- 2、modulePath 是要在 node 子进程中运行的模块,由于是 node.js 的进程,所以可以是 start.js 这种 js 文件
- 3、无回调,参数要以第二个参数传入
- 4、返回的子进程将内置一个额外的 ipc 通信通道,允许消息在父进程和子进程之间来回传递。
如:
1 | const fork = require('child_process').fork; |
父子通信
通过注册 message 事件。
1 | /** |
1 | /** |
7 nodejs 升级和版本切换
- 安装
n模块
1 | sudo npm install -g n |
- 升级 node.js 到最新稳定版
1 | sudo n stable |
- 升级 node.js 到最新版
1 | sudo n latest |
- 切换到指定版本
1 | sudo n 8.9.4 |
- 用指定版本执行脚本
1 | sudo n use 8.9.4 someScript.js |
- 查看已安装的所有版本
1 | sudo n |
8 os 模块
用于获取操作系统(OS)的相关信息。
1 | const os = require('os'); |
os-utils
npm:https://www.npmjs.com/package/os-utils。
可用于获取 cpu 信息,如
1 | const os = require('os-utils'); |
*9.REPL
REPL 的全称:Read、Eval、Print、Loop。进入 REPL 环境:
1 | node |
退出 REPL 环境:
1 | .exit |
或
1 | process.exit(); |
10.package.json 和 node_modules
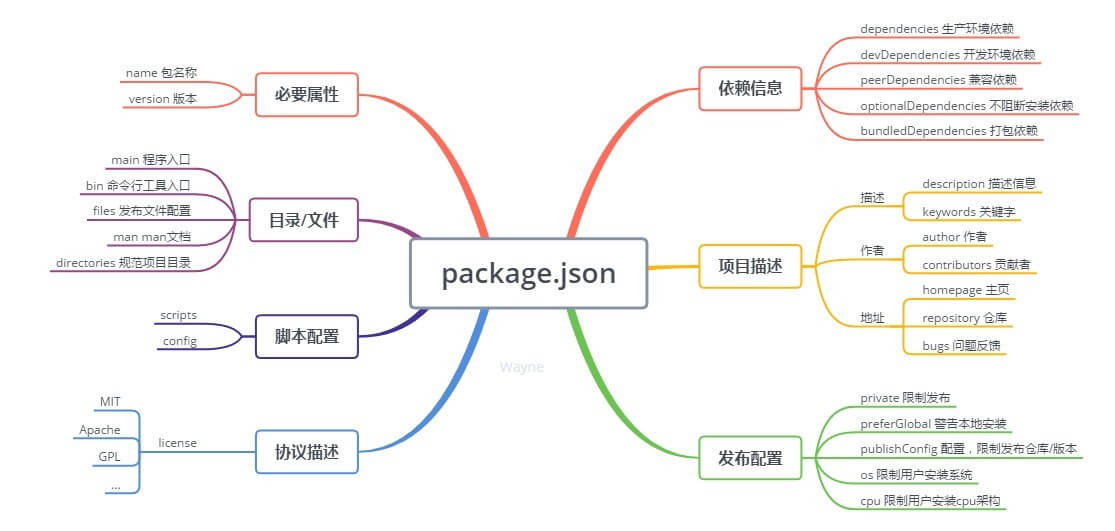
package.json 字段介绍
node 模块
Node.js 的模块分为两类,一类为原生(核心)模块,一类为文件模块。原生模块在 Node.js 源代码编译的时候编译进了二进制执行文件,加载的速度最快。另一类文件模块是动态加载的,加载速度比原生模块慢。但是 Node.js 对原生模块和文件模块都进行了缓存,于是在第二次 require 时,是不会有重复开销的。其中原生模块都被定义在 lib 这个目录下面,文件模块则不定性。
实际上在文件模块中,又分为 3 类模块。这三类文件模块以后缀来区分,Node.js 会根据后缀名来决定加载方法。
.js。通过 fs 模块同步读取 js 文件并编译执行。.node。通过 C/C++ 进行编写的 Addon。通过 dlopen 方法进行加载。.json。读取文件,调用 JSON.parse 解析加载。
Node.js 在编译 js 文件的过程中实际完成的步骤有对 js 文件内容进行头尾包装。以 app.js 为例,包装之后的 app.js 将会变成以下形式:
1 | (function (exports, require, module, __filename, __dirname) { |
这段代码会通过 vm 原生模块的 runInThisContext 方法执行(类似 eval,只是具有明确上下文,不污染全局),返回为一个具体的 function 对象。最后传入 module 对象的 exports,require 方法,module,文件名,目录名作为实参并执行。
这就是为什么 require 并没有定义在 app.js 文件中,但是这个方法却存在的原因。从 Node.js 的 API 文档中可以看到还有 filename、dirname、module、exports 几个没有定义但是却存在的变量。其中 filename 和 dirname 在查找文件路径的过程中分析得到后传入的。module 变量是这个模块对象自身,exports 是在 module 的构造函数中初始化的一个空对象({},而不是 null)。
在这个主文件中,可以通过 require 方法去引入其余的模块。而其实这个 require 方法实际调用的就是 load 方法。
load 方法在载入、编译、缓存了 module 后,返回 module 的 exports 对象。这就是 circle.js 文件中只有定义在 exports 对象上的方法才能被外部调用的原因。
以上所描述的模块载入机制均定义在 lib/module.js 中。
一个符合 CommonJS 规范的包应该是如下这种结构:
- 一个 package.json 文件应该存在于包顶级目录下
- 二进制文件应该包含在 bin 目录下。
- JavaScript 代码应该包含在 lib 目录下。
- 文档应该在 doc 目录下。
- 单元测试应该在 test 目录下。
Node.js 在没有找到目标文件时,会将当前目录当作一个包来尝试加载,所以在 package.json 文件中最重要的一个字段就是 main。而实际上,这一处是 Node.js 的扩展,标准定义中并不包含此字段,对于 require,只需要 main 属性即可。但是在除此之外包需要接受安装、卸载、依赖管理,版本管理等流程,所以 CommonJS 为 package.json 文件定义了如下一些必须的字段:
- name。包名,需要在 NPM 上是唯一的。不能带有空格。
- description。包简介。通常会显示在一些列表中。
- version。版本号。一个语义化的版本号( http://semver.org/ ),通常为 x.y.z。该版本号十分重要,常常用于一些版本控制的场合。
- keywords。关键字数组。用于 NPM 中的分类搜索。
- maintainers。包维护者的数组。数组元素是一个包含 name、email、web 三个属性的 JSON 对象。
- contributors。包贡献者的数组。第一个就是包的作者本人。在开源社区,如果提交的 patch 被 merge 进 master 分支的话,就应当加上这个贡献 patch 的人。格式包含 name 和 email。如:
1 | "contributors": [{ |
- bugs。一个可以提交 bug 的 URL 地址。可以是邮件地址(mailto:mailxx@domain),也可以是网页地址(http://url)。
- licenses。包所使用的许可证。例如:
1 | "licenses": [{ |
- repositories。托管源代码的地址数组。
- dependencies。当前包需要的依赖。这个属性十分重要,NPM 会通过这个属性,帮你自动加载依赖的包。
以下是 Express 框架的 package.json 文件,值得参考。
1 |
|
除了前面提到的几个必选字段外,我们还发现了一些额外的字段,如 bin、scripts、engines、devDependencies、author。这里可以重点提及一下 scripts 字段。包管理器(NPM)在对包进行安装或者卸载的时候需要进行一些编译或者清除的工作,scripts 字段的对象指明了在进行操作时运行哪个文件,或者执行拿条命令。如下为一个较全面的 scripts 案例:
1 |
|
11 package.json 与 package-lock.json
package.json 中各依赖版本遵守semver 的语义版本控制,简单来说版本由主要版本.次要版本.补丁版本。补丁中的修改不会破坏任何内容的错误修复,次要版本的更改不会破坏任何内容的新功能,主要版本的更改代表一个破坏兼容性的大变化。
默认情况下,npm 安装最新版本,并预先插入版本号,如^1.2.12,这表示至少应该使用1.2.12版本,但任何高于此版本的版本都可以,只要它具有相同的主要版本。
比如我们需要安装 express,npm install express --save,在编写代码时最新版本是4.17.1,所以"express": "^4.17.1"作为我的 package.json 中的依赖项添加。但过一段时候,express 升级到了4.17.2,别人在 clone 项目时执行 npm install 后便安装的是4.17.2的版本。如果4.17.2出现了一些非兼容4.17.1的功能时便会出现问题,这也就是 package-lock 出现的原因。
package-lock.json就是为了避免在安装模块时会导致两种不同安装结果的问题。npm 在 v5 的版本时增加了 package-lock.json,因此如果你使用的 npm 版本大于等于 5,除非禁用此功能否则它会自动生成。
package-lock 的内容结构
package-lock 是 package.json 中列出的每个依赖项的大型列表,应安装的特定版本,模块的位置(URI),验证模块完整性的哈希,它需要的包列表 ,以及依赖项列表。 如 package-lock.json 中的 express:
1 | "express": { |
requires 包含 express 每个依赖包的版本,并且在执行 npm install 命令时 npm 会使用 package-lock.json 而不是 package.json 来解析和安装模块,因为 package-lock 能保证每个依赖项的指定版本、位置和完整性哈希,以保证每次安装都是相同的。
package-lock 的争议
在 npm 5.x.x 之前,package.json 是项目的真实来源,npm 用户喜欢这个模型,并且非常习惯于维护他们的包文件。 但是,当首次引入 package-lock 时,它的行为与有多少人预期的相反。 给定一个预先存在的包和 package-lock,对 package.json 的更改(许多用户认为是真实的来源)没有同步到 package-lock 中。
例如:包 A,版本 1.0.0 在 package.json 和 package.lock.json 中。 在 package.json 中,A 被手动编辑为 1.1.0 版。 如果认为 package.json 是真实来源的用户运行。
package-lock.json 中不存在模块,但它存在于 package.json 中,作为一个将 package.json 视为真实来源的用户,我希望能够安装我的模块。 但是,由于 package-lock.json 不存在该模块,因此未安装该模块,并且我的代码因无法找到模块而失败。
大部分时间,因为我们无法弄清楚为什么我们的依赖关系没有被正确安装,要么删除了 package-lock.json 并重新安装,要么完全禁用 package-lock.json 来解决问题。
期望与真实行为之间的这种冲突在 npm repo 中引发了一个非常有趣的问题线索。 有些人认为 package.json 应该是事实的来源,有些人认为,因为 package-lock 是 npm 用来创建安装的东西,所以应该被认为是事实的来源。 这场争议的解决方案在于 PR#17508。 如果 package.json 已更新,Npm 维护者添加了一个更改,导致 package.json 覆盖 package-lock。 现在,在上述两种情况下,都会正确安装用户期望安装的软件包。 此更改是作为 npm v5.1.0 的一部分发布的,该版本于 2017 年 7 月 5 日上线。
使用 cnpm install 时候,并不会生成 package-lock.json 文件。并且,在 cnpm 安装的时候,就算你项目中有 package-lock.json 文件,cnpm 也不会识别,仍会根据 package.json 来安装。
在考虑 package-lock 的依赖安装时,推荐使用 npm ci 命令,而不是 npm install。
12 大文件逐行读取:readline
fs.readFile()和fs.readFileSync()打开文件的时候需要将整个文件读取到内存中,如果遇到大文件的情况就会遇到错误,因此需要逐行读取。
readeline 模块
内置模块,每次从任何可读的流中读取一行。使用如:
1 | const readline = require('readline'); |
line-reader
安装:
1 | npm i --save line-reader |
line-reader 提供了读取给定文件的每一行的eachLine()方法。它接受一个带有两个参数的回调函数:行内容和一个布尔值,该值指定行 read 是否是文件的最后一行。如:
1 | const lineReader = require('line-reader'); |
使用 line-reader 的另一个好处是,当某些条件变为真时,可以停止读取。可以通过回调函数返回值来实现:
1 | lineReader.eachLine('file.txt', (line, isLast) => { |
LineByLine
安装:
1 | npm i --save linebyline |
linebyline 以 readline 模块为基础,为每行触发一个 line 事件,如:
1 | const linebyline = require('linebyline'); |
常见问题解决汇总
1.不同操作系统下的 NODE_ENV
比如一个 package.json 设置的某个 script 如下:
1 | "scripts": { |
这在 mac 下没有问题,但 windows 上报错了,因为 windows 上没有 export。这时候可以用set代替export:
1 | "scripts": { |
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com