【笔记】前端概念性知识随手记(持续)
Apr 27, 2019笔记前端概念前端概念性知识随手记(持续)
- start date: 2018-08-27 13:00:45
更少的代码 = 更少的错误覆盖面积 = 更少的 bug。
学会不如会学,会学不如会用,会用不如被用。学会(知其所然)——掌握一些具体编程知识;会学(知所以然)——能快速而深刻地理解技术并举一反三;会用(人为我用)——能将所学灵活运用到实际编程设计之中;被用(我为人用)——能设计出广为人用的应用程序(application)、库(library)、工具包(toolkit)、框架(framework)等。
被用的更高层次,发明出主流的设计模式、算法、语言,乃至理论等。
1 传统编译语言和JavaScript
传统编译语言的编译过程
在传统编译语言的流程中,程序中的一段源代码在执行之前会经历三个步骤,统称为“编译”。
- 分词/词法分析(Tokenizing/Lexing)
这个过程会将由字符组成的字符串分解成(对编程语言来说)有意义的代码块,这些代
码块被称为词法单元(token)。例如,考虑程序var a = 2;。这段程序通常会被分解成
为下面这些词法单元:var、a、=、2、;。空格是否会被当作词法单元,取决于空格在
这门语言中是否具有意义。 - 分词(tokenizing)和词法分析(Lexing)之间的区别是非常微妙、晦涩的,
主要差异在于词法单元的识别是通过有状态还是无状态的方式进行的。简
单来说,如果词法单元生成器在判断 a 是一个独立的词法单元还是其他词法
单元的一部分时,调用的是有状态的解析规则,那么这个过程就被称为词法
分析。 - 解析/语法分析(Parsing)
这个过程是将词法单元流(数组)转换成一个由元素逐级嵌套所组成的代表了程序语法
结构的树。这个树被称为“抽象语法树”(Abstract Syntax Tree,AST)。var a = 2;的抽象语法树中可能会有一个叫作 VariableDeclaration 的顶级节点,接下
来是一个叫作 Identifier(它的值是 a)的子节点,以及一个叫作 AssignmentExpression
的子节点。AssignmentExpression 节点有一个叫作 NumericLiteral(它的值是 2)的子
节点。 - 代码生成
将 AST 转换为可执行代码的过程称被称为代码生成。这个过程与语言、目标平台等息
息相关。
抛开具体细节,简单来说就是有某种方法可以将 var a = 2; 的 AST 转化为一组机器指
令,用来创建一个叫作 a 的变量(包括分配内存等),并将一个值储存在 a 中。
JavaScript的编译
JavaScript 引擎要复杂得多。例如,在
语法分析和代码生成阶段有特定的步骤来对运行性能进行优化,包括对冗余元素进行优化
等。
- 首先,JavaScript 引擎不会有大量的(像其他语言编译器那么多的)时间用来进行优化,因
为与其他语言不同,JavaScript 的编译过程不是发生在构建之前的。 - 对于 JavaScript 来说,大部分情况下编译发生在代码执行前的几微秒(甚至更短!)的时
间内。在我们所要讨论的作用域背后,JavaScript 引擎用尽了各种办法(比如 JIT,可以延
迟编译甚至实施重编译)来保证性能最佳。 - 简单地说,任何 JavaScript 代码片段在执行前都要进行编译(通常就在执行前)。因此,
JavaScript 编译器首先会对 var a = 2; 这段程序进行编译,然后做好执行它的准备,并且
通常马上就会执行它。
2 语言族
许多现存的语言都可以基于其计算模型加以分类,归入某些语言族中。1
2
3
4
5
6
7
8说明式
函数式:Lisp/Scheme,ML,Haskell
数据流:Id,Val
逻辑式,基于约束的:Prolog,VisiCale
命令式
冯.诺依曼:Fortran,Pascal,Basic,C,...
面向对象:Smalltalk,Eiffel,C++,Java
这里的类属并不清晰,含有争议,一个函数式语言可能又是面向对象的。
在说明式和命令式语言族里,又各有几个重要的子类。
- 函数式语言采用一种基于递归表示的函数定义的计算模型。它们的灵感来自λ演算,在本质上,程序被看作是一种从输入到输出的函数,基于一些更简单的函数,通过一种逐步精化的方式定义。如Lisp、ML和Haskell。
- 数据流语言将计算看成在一些基本的功能结点之间流动的信息(单词)流。这些语言提供了一种内在的并行模型:结点由输入单词的到达触发,能够并发操作。如Id、Val。
- 逻辑式或基于限制的语言由命题逻辑得到灵感,它们把计算看作是通过一种目标制导的搜素,设法根据一集逻辑规则找出满足某些特定关系的值。如VisiCalc、Excel、Lotus。
- 冯.诺依曼语言是最熟悉以及最成功的。这类语言包括了Fortran、Pascal、Basic、C等等,以及所有那些把修改变量的值当作基本计算方式的语言。
- 面向对象语言,大部分都与冯.诺依曼语言有很深的渊源,但在存储和计算两方面都采纳了一种更加结构化合分布式的模型。面向对象的语言并不是吧计算描绘为一个处理器子啊一个存储区上的操作,而是看作一些比较独立的对象之间的相互作用,每个对象有其自身的内部状态,以及一些管理这种状态的可执行函数。
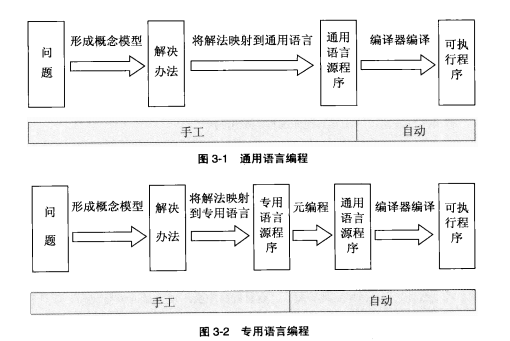
3 编译和解释
编译
高级语言里的一个程序的编译和执行过程大致如下:
编译器将高级语言源程序翻译成与之等价的目标程序(典型情况就是机器语言程序),而后就隐退了。在随后的某个任意时刻,用户可以告诉操作系统去运行这个目标程序。编译器完全掌控者整个的编译过程,而目标程序在执行中完全控制着自己的活动。编译器本身也是一个机器语言程序,或许是由另外的某个高级语言程序编译而成的。在按照某种操作系统能理解的格式写入文件时,机器语言的程序常被称为目标代码。
优:更好的性能
解释

与编译器不同,在应用程序执行期间,解释器一直守在旁边。事实上,这种执行过程是完全由解释器控制的。从效果上看,这种解释器实现了一台虚拟的机器,其“机器语言”就是这里的高级程序设计语言。解释器一次读入这种语言的或多或少的语句,按照它们应该工作的方式执行相应的动作。
有关程序实现的决策推迟到运行时才做,这种方式被称为迟约束。
优:更大的灵活。
编译和解释的混合
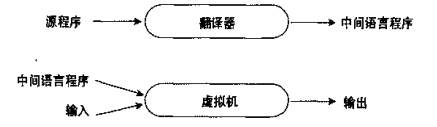
如果初始阶段的翻译器比较简单,我们就说这个语言是“解释的”,如果其中的翻译器很复杂,我们就说这一语言是“编译的”。
Lambda表达式
“Lambda 表达式”(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。Lambda表达式可以表示闭包(注意和数学传统意义上的不同)。
lambda 表达式全是函数组成,依靠函数来编写软件是非常高效和有意义的。
- 函数都是匿名的,在 JavaScript 中,表达式 const sum = (x, y) => x + y 的右侧,可以看作一个匿名函数表达式 (x, y) => x + y。
- lambda 表达式中的函数只接收一个参数。他们是一元的,如果你需要多个参数,函数将会接受一个输入返回一个调用下一个函数的函数,然后继续这样。非一元函数 (x, y) => x + y 可以被表示为一个像 x => y => x + y 的一元函数。这个把多元函数转换成一元函数的过程叫做柯里化。
- 函数是一等公民的,意味着函数可以作为参数传递给其他函数,同时函数可以返回函数。
组合
“在计算机科学中,复合数据类型或组合数据类型是可以使用编程语言原始数据类型和其他复合类型构建的任何数据类型。[…] 构建复合类型的行为称为组合。“ —— 维基百科
组合:“将部分或元素结合成整体的行为。” —— Dictionary.com
软件开发的过程可以说是把大问题拆分成更小的问题,构建解决这些小问题的组件,然后把这些组件组合在一起形成完整的应用程序。
- 函数组合:函数组合是将一个函数应用于另一个函数输出结果的过程。
- 组合对象:每次你构建任何非原始数据结构的时候,你都在执行某种对象组合。
在不提及参数的情况下编写的函数成为无值风格。
对象组合
三种对象组合关系:
- 委托(在状态,策略和观察者模式中使用);
- 结识(当一个对象通过引用知道另一个对象时,通常是作为一个参数传递:一个 uses-a 关系,例如,一个网络请求处理程序可能会传递一个对记录器的引用来记录请求 —— 请求处理程序使用一个记录器)
- 聚合(当子对象形成父对象一部分时:一个 has-a 关系,例如,DOM 子节点是 DOM 节点中的组件元素 —— DOM 节点拥有子节点)。
对象组成:”通过将对象放在一起形成复合对象,使得后者中的每一个都是‘前者’的一部分。“
类继承只是一种复合对象结构。所有类生成复合对象,但不是所有的复合对象都是由类或者类继承生成的。“在类继承上支持对象组合”意味着你应该从小组件部分构建复合对象,而不是在类层次上从祖先继承所有属性。
后者在面向对象设计中引起大量众所周知的问题:
- 强耦合问题:因为子类依赖于父类的实现,类继承是面向对象设计中最紧密的耦合。
- 脆弱的基类问题:由于强耦合,对基类的更改可能会破坏大量的后代类 —— 可能在第三方管理的代码中。作者可能会破坏掉他们不知道的代码。
- 不灵活的层次结构问题:对于单一的祖先分类法,给定足够的时间和改进,所有的类分类法最终都是错误的新用例。
- 必要性重复问题:由于层次结构不灵活,新的用例通常是通过复制而不是扩展来实现,从而导致类似的类意外地的发散。一旦复制开始,就不清楚或者为什么哪个新类应该从哪个类开始。
- 大猩猩/香蕉问题:”…面向对象语言的问题在于它们自身带有所有隐含的环境。你想要的是一根香蕉,但你得到的是拿着香蕉的大猩猩和整个丛林。“ —— Joe Armstrong,”工作中的编码员”。
JavaScript 中最常见的对象组合形式称为对象链接(又称混合组合)。它像冰淇淋一样。你从一个对象(如香草冰淇淋)开始,然后混合你想要的功能。加入一些坚果,焦糖,巧克力漩涡,然后你会结出坚果焦糖巧克力漩涡冰淇淋。
如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 类继承
class ObjA {
constructor () {
this.a = 'A';
}
}
class ObjB extends ObjA {
constructor (param) {
super(param);
this.b = 'B';
}
}
// 组合混合
let objA = {
a: 'A'
};
let objB = {
b: 'B'
};
let objAB = { ...a, ...b };
函数签名和重载
函数签名:函数的名称及其参数类型组合在一起,就定义了一个唯一的特性,称为函数签名。(不包括返回类型)
在编写包含函数调用的语句时,编译器就会使用该调用创建一个函数签名,再把它与函数原型/或定义中可用的函数签名集比较。如果找到匹配的函数名,就建立所调用的函数。
函数的签名可以包含以下内容:
一个 可选的 函数名。
在括号里的一组参数。 参数的命名是可选的。
返回值的类型。
函数重载:多个相同函数名,不同的参数个数或者类型的形式叫做函数的重载。
函子functor
在范畴论中,函子(functor)是范畴间的一类映射,通俗地说,是范畴间的同态。 ——百度百科
所谓 functor(函子),是能够对其进行 map 操作的对象。换言之,functor 可以被认为是一个容器,该容器容纳了一个值,并且暴露了一个接口(译注:即 map 接口),该接口使得外界的函数能够获取容器中的值。
图灵完备的(Turing-complete)
一个能计算出每个图灵可计算函数(Turing-computable function)的计算机系统被称为图灵完备的,一个语言是图灵完备的,意味着该语言的计算能力与一个通用图灵机(Universal Turing Machine)相当,这也是现代计算机语言所能拥有的最高能力。
计算机语言分代
- 第一代语言(1GL):机器语言;
- 第二代语言(2GL):汇编语言——IA-32 Assembly,SPARC Assembly等;
- 第三代语言(3GL):高级语言——Fortran、Pascal、C、Java、VB等;
- 第四代语言(4GL):面向问题语言——SQL、SAS、SPSS等;
- 第五代语言(5GL):人工智能语言——Prolog、Mercury、OPS5等;
领域特定语言DSL
领域特定语言,简称DSL,它区别于通用语言,一般用于特定的问题领域,多属于第4代语言。比如,SQL是专门针对数据库的语言,LateX是专门用于排版的语言,正则表达式(regular expression)是专门处理字符匹配的语言。还有SAS、SPSS、mathematica等等。
通用编程语言(General-Purpose Programming Language,简称GPPL)。
编程范式(Programming Paradigm)
指的是计算机编程的基本风格或典范模式,相当于武功心法。如面向对象编程。编程是为了解决问题,而解决问题可以有多种视角和思路,其中普适且行之有效的模式被归结为范式。由于着眼点和思维方式的不同,相应的范式自然各有侧重和倾向,因此一些范式常用’oriented’来描述。换言之,每种范式都引导人们带着某种的倾向去分析问题、解决问题。
抽象的编程范式须要通过具体的编程语言来体现。范式的世界观体现在语言的核心概念之中,范式的方法论体现在语言的表达机制中。一种语言的语法和风格与其所支持的编程范式密切相关。
学习编程范式能增强编程语言的语感。
命令范式——一切行动听指挥
命令式编程(Imperative Programming):程序是由若干行动指令组成的有序列表。它用变量来存储数据,用语句来执行命令。命令式编程是冯诺依曼机运行机制的抽象,即依序从内存中获取指令和数据,然后去执行。
绝大多数语言是命令式的,机器语言都是命令式的。命令式编程提倡迭代而不鼓励递归。
过程式编程
过程式编程(procedural Programming)是指引入了过程(procedure)、函数(function)或子程序(subroutine/subprogram)的命令式编程。现代的命令式语言均具备此特征,所以同命令式编程。
结构化编程
结构化编程(structure Programming,SP)是在过程式编程的基础上发展,本质是一种编程原则,提倡代码应具有清晰的逻辑结构,以保证程序易于读写、测试、维护和优化。
按照结构化订立,任何程序都可用顺序(concatenation)、选择(selection)和循环(repetition)等三种基本控制结构来表示,如下图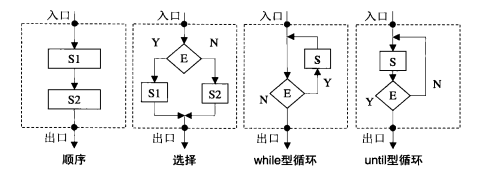
这些基本控制结构都满足“单入口、单出口”(single entry、single exit,SESE)的原则。
结构化编程的思想包括两方面,在微观上,主张循规守矩,采用顺序、选择和循环3种逻辑结构,摒弃或限制goto语句,以避免杂乱无章的代码;在宏观上,主张分而治之(divide and conquer),采用“自顶向下”(top-down)的设计,通过模块化将一个较为复杂的系统分界为若干相对简单的子系统,每个子系统可用独立地进一步分解,直到容易编码实现为止。
声明范式——目标决定行动
声明式编程(declarative Programming,DP)重目标、轻过程,专注问题的分析和表达而不致陷入算法的迷宫,其代码也更加简洁清晰、易于修改和维护。
声明式编程由若干规范(specification)的声明组成的,即一系列陈述句:“已知这,求解那”,强调“做什么”而非“怎么做”。声明式编程是人脑思维方式的抽象,即利用数理逻辑或既定规范对已知条件进行推理或运算。
声明式编程发轫于人工智能的研究,主要包括函数式编程(FP)和逻辑式编程(logic Programming,LP)。其中函数式编程将计算描述为数学函数的求值,而逻辑式编程通过提供一系列事实和规则来推导或论证结论。
命令式编程是行动导向(Action-Oriented)的,因而算法是显性而目标是隐性的;声明式编程是目标驱动(Goal-Dirven)的,因而目标是显性而算法是隐性的。
如1
2
3
4
5
6
7/* 命令式 */
int factor (int n)
{
int f = 1;
for(; n > 0; --n) f *= n;
return f;
}
1 | /* 函数式 */ |
1 | /* 逻辑式 */ |
声明式编程让我们重回数学思维,函数式编程类似代数中的表达式变换和计算,逻辑式编程则类似数理逻辑推理。声明式语言(尤其是函数式语言和逻辑式语言)擅长基于数理逻辑的应用,如人工智能、符号处理、数据库、编译器等,对基于业务逻辑的、尤其是交互式或事件驱动型的应用就不那么得心应手了。
声明式编程并不仅仅局限于函数式和逻辑式。HTML属于声明式。声明式语言提倡递归而不支持迭代。
编程是寻求一种机制,将制定的输入转化为指定的输出。
三种核心编程范式的比较
| 范式 | 程序 | 输入 | 输出 | 程序设计 | 程序运行 |
|---|---|---|---|---|---|
| 命令式 | 自动机 | 初始状态 | 最终状态 | 设计指令 | 命令执行 |
| 函数式 | 数学函数 | 自变量 | 因变量 | 设计函数 | 表达式变换 |
| 逻辑式 | 逻辑证明 | 题设 | 结论 | 设计命题 | 逻辑推理 |
对象范式——民主制社会的编程法则
OOP(Object-Oriented Programming)是一种计算机编程模式,它将对象作为问题空间的基本元素,利用对象和对象间的相互作用来设计程序。所谓对象,是实际问题中实体的抽象,具有一定的属性和功能。
OOP的3个基本特征是:封装性、继承性和多态性。
OOP虽然是在命令式的基础上发展起来的,但其核心思想可泛化为:以数据为中心组织逻辑,将系统视为相互作用的对象集合,并利用继承与多态来增强可维护性、可拓展性和可重用性。OOP大多是命令式的,但也有函数式的和逻辑式的OO语言。
纯粹的OOP(不含其它范式)是不存在的,必须结合其他范式。OOP适合用于大型复杂的、交互式的,尤其是与现实世界密切相关的系统,在小型应用、数学计算、符号处理等方面并无优势。
过程式编程的理念是以过程为中心,自顶向下、逐步求精。OOP则相反,以数据为中心,自底向上、逐步合并。
如果把整个流程看作一颗倒长的大树,过程式编程自树根向下,逐渐分支,直到每片树叶,类似数学证明中的分析法,即执果索因的逆推法;OOP则从每片树叶开始,逐渐合并,直到树根,类似数学证明中的综合法,即执因索果的正推法。倘若把树根看成主函数,离树根越近,离用户需求也越近。如果用过程式编程,由于是逆推法,树干改变容易导致树枝相应改变,因此一旦用户需求发生变化,可能从树根波及到树枝甚至树叶,维护起来殊为不易。相反OOP从树叶开始设计,离用户需求较远,抽象程度较高,受波及的程度较小,因此更易维护和重用。
软件设计最重要的并不是编程语言,也不是编程范式,而是抽象思维。OOP以对象为基本模块单位,而对象是现实中具体事物和抽象概念的模拟,这使得编程设计更自然更人性化。
OOP更接近人类的认知模式,编程者更容易也更乐于用这种方式编程,易用性。如牛.吃(肉)跟吃(牛, 肉)的区别。
函数可类比于电器元件,OOP的对象类比于电器。过程式编程的模块以函数为单位,OOP模块以对象为单位,二者的区别是:函数是被动的实体,对象是主动的实体。过程式程序的世界是君主制的。主函数是国王,其他函数是臣民,等级分明,所有臣民在听命于上级的同时也对下级发号施令,最终为国王服务;OO程序的世界是民主制的,所有对象都是独立而平等的公民,有权利保护自己的财产和隐私并向他人寻求服务,同时又义务为他人提供承诺的服务,公民之间通过信息交流来协作完成各种任务。更进一步地,封装使得公民拥有个体身份,须要对自己负责;继承使得公民拥有家庭身份,须要对家庭负责;多态使得公民拥有社会身份,须要对社会负责。
并发范式——合作与竞争
并发式编程(Concurrent Programming,CP)以进程(process)或线程(thread)为基本单位。类比于洗茶杯;放茶叶;灌水壶;水开后泡茶跟灌水壶;在烧水的同时,洗茶杯;放茶叶;水开后泡茶。方案一是串行式编程,方案二是并发式编程。
并发式编程以进程为导向(Process-Oriented)、以任务为中心将系统模块化。相比串行式,并发式在模块之间引入了新的通信和控制方式。也就是说,原先的一些模块的定义和划分一定是建立在线程机制的基础上的。
并发式编程以资源共享与竞争为主线。
并发式与对象式均与3大核心范式正交,并且越来越广泛地向它们渗透着;均为传统编程的一种推广——并发式进程的个数为1时即为传统的串行编程,对象的方法个数为零时即为传统的数据类型;均将整个程序系统分解为若干独立的子系统,不同的是一个以任务为单位,一个以对象为单位;子系统之间均能交流与合作,不同的是一个以竞争为主题,一个以服务为主题。
最传统的1个是命名是;最基本的两个是命令式和声明式;最核心的3个是命令式、函数式和逻辑式;最主要的4个是命令式、函数式、逻辑式和对象式;最重要的5个是命令式、函数式、逻辑式、对象式和并发式。1
2
3
4
5过程式:以过程为模块的君主体系,模块之间互相授命与听命。
函数式:以函数为模块的数学体系,模块之间互相替换与合成。
逻辑式:以断言为模块的逻辑体系,模块之间互相归纳与演绎。
对象式:以对象为模块的民主体系,模块之间互相交流与服务。
并发式:以进程为模块的生产体系,模块之间互相竞争与合作。
常用范式
泛型范式——抽象你的算法
泛型编程(Generic Programming, GP),其基本思想是:将算法与其作用的数据结构分离,并将后者尽可能泛化,最大限度地实现算法重用。这种泛化是基于模板(template)的参数多态(parametric polymorphism),相比OOP基于继承(inheritance)的子类型多态(subtyping polymorphism),不仅普适性更强,而且效率也更高。
泛型编程是算法导向(Algorithm-Oriented)的,即以算法为起点和中心点,逐渐将其所涉及的概念(如数据结构、类)内涵模糊化、外延扩大化,将其所涉及的运算(函数、方法、接口)抽象化、一般化,从而扩展算法的适用范围。
如1
2
3
4
5
6
7
8
9/* 泛型编程 */
template <typename T>
T max(T a, T b)
{
return (a > b) ? a : b;
}
/* 宏定义 */
- TypeScript泛型:https://www.tslang.cn/docs/handbook/generics.html
STL有3要素:算法(algorithm)、容器(container)和迭代器(iterator)。算法是一系列切实有效的不走;容器是数据的集合,可理解为抽象的数组;迭代器是算法与容器之间的接口,可理解为抽象的指针或游标。
超级范式——提升语言的级别
元编程作为超级范式的一个体现是,它能提升语言的级别。它是编写、操纵程序的程序。在传统编程中,运算是动态的,但程序本身是静态的;在元编程中,二者都是动态的。元程序将程序作为数据来对待,有着其他程序所不具备的自觉性、自适应性和智能性,可以说是一种最高级的程序。
如果说OOP的关键在于构造对象的概念,那么LOP(Language-Oriented Programming,语言导向式编程)的关键在于构造语言的语法。
离开IDE就无法编写、编译或调试的程序员,如同卸盔下马后便失去战斗力的武士,是残缺和孱弱的。
模板编程(Template MetaProgramming),与泛型编程密切相关但自成一派,隶属于另一种编程范式——元编程(MetaProgramming),简称MP。比如,元数据(Metadata)是关于数据的数据,元对象(Metaobject)是关于对象的对象,以此类推,元编程是关于程序的程序。
如果一个大型系统涉及到的领域十分专业,包含的业务逻辑十分复杂,为其定制DSL或许会磨刀不误砍柴工。由于DSL比通用语言更简单、更抽象、更专业、更接近自然语言和声明式语言,开发效率显著提高,因此手工部分的时间相应减少,特别地,这种方式填补了专业程序员与业务分析员之间的鸿沟。
如果处理一些复杂、非标准格式的文档,可以考虑用元编程;如果整个而延误逻辑复杂多变,可以考虑利用现有的DSL或创造新的DSL来处理业务,即LOP。
自动生成源代码的编程也属于另一种编程范式——产生式编程(Generative Programming, GP)的范畴,区别在于后者更看重代码的生产,而元编程看重的是生成代码的可执行性。
切面范式——多角度看问题
无论是过程式的函数,还是对象式的方法,都包含了完整的执行代码。但有些代码横跨多个模块,以片断的形式散落在各处,虽具有相似的逻辑,却无法用传统的方式提炼成模块,难以实现Soc与DRY。
AOP自OOP的土壤中长出,却脱离藩篱自成一体。OOP只能沿着继承树的纵向方向重用,而AOP则弥补了OOP的不足,可以在横纵方向重用。
AOP的实现机理:AOP就是在管道上钻一些孔,在每个孔中注入新的代码流。因此AOP实现的关键是将advice的代码嵌入到主体程序之中,术语称编织(weaving)。编织分为两种:一种是静态编织,通过修改源码或字节码(bytecode)在编译器(compile-time)、后编译器(post-compile)或加载期(load-time)嵌入代码。
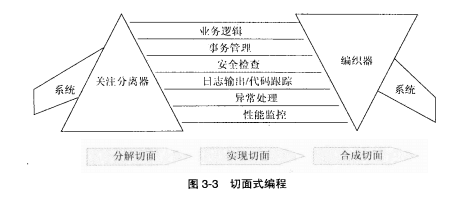
由图可知,AOP的实施分3步:切面分解、切面实现和切面合成。地中第一步是在设计者的头脑中进行的,第三步是通过AOP的工具实现的,真正需要程序员编码的部分在第二步,即分别实现各切面的advice。
接入点是附加行为——建议(advice)的执行点,切入点(pointcut)是指定的接入点(join point)集合,这些接入点共享一段插入代码。切入点与建议组成了切面(aspect),是模块化的横切关注点。
AOP无非是SoC原理和DRY原则的一种应用。SoC(Separation of Concerns),关注点分离;DRY(Don’t Repeat Yourself),尽量减少重复代码。
不良代码通常有两种病征:一是结构混乱、或聚至纠缠打结、或散至七零八落;二是代码重复,叠床架屋、臃肿不堪。治疗此类病症有一个有效的方法:抽象与分解。从问题中抽象出一些关注点,再以此为基础进行分解。分解后的子问题主题鲜明且独立完备,既不会牵一发而动全身,也不会四分五裂、支离破碎。同时具有相同特征的部分可以想代数中的公因子一样提取出来,提高了重用性,减少了重复性。
抽象与分解中,抽象是前提,分解是方式,模块化是结果。之前的编程范式基本思想也是如此,将程序分别抽象分解为过程、函数、断言、对象和进程,就依次成为过程式、函数式、逻辑式、对象式和并发式,泛型式虽未引入新类型的模块,其核心也是抽象出算法后与数据分解。以此类推,AOP将程序抽象分解为切面。
抽象与分解的原则是:单一化、正交化。每个模块职责明确专一,模块之间相互独立,即高内聚低耦合(high cohesion & low coupling)。
AOP以切面(Aspect)为模块,它描述的是横切关注点(cross-cutting concerns),就是程序的纵向主流执行方向横向正交的关注焦点。
AOP增加了一定的复杂度和性能损耗,它们更适用于大中型程序。
事件驱动——有事我叫你,没事别烦我
采用警觉式者主动去轮询(polling),行为取决于自身的观察判断,是流程驱动的,符合常规的流程驱动式编程(Flow-Driven Programming)的模式。采用托付式者被动等通知(notification),行为取决于外来的突发事件,是事件驱动的,符合事件驱动式编程(Event-Driven Programming,EDP)的模式。
事件:它是已经发生的某种令人关注的事情。在软件中,它一般表现为一个程序的某些信息状态上的变化。基于事件驱动的系统一般提供两类的内建事件(built-in event):一类是底层事件(low-level event)或称原生事件(native event),在用户图形界面(GUI)系统中这类事件直接由鼠标、键盘等硬件设备触发;一类是语义事件(semantic event),一般代表用户的行为逻辑,是若干底层事件的组合。比如鼠标拖放多表示移动杯拖放的对象,由鼠标按下、鼠标移动和鼠标释放三个底层事件组成。还有一类用户自定义事件(user-defined event),它们可以是在原有的内建事件的基础上进行的包装,也可以是纯粹的虚拟事件(Virtual event)。除此之外,编程者不但能定义事件,还能产生事件。如模拟鼠标点击等,这类事件被称为合成事件(synthetic event),这些都进一步丰富完善了事件体系和事件机制,使得事件驱动式编程更具渗透性。
在软件模块分层中,低层模块为高层模块提供服务,并且不能依赖高层模块,以保证其可重用性;另一方面,通常被调者(callee)为调用者(caller)提供服务,调用者依赖被调者。两相结合,决定了低层模块多为被调者,高层模块多为调用者。但这种惯例并不总是合适的——低层模块为了追求更强的普适性和可拓展性,有时也有调用高层模块的需求,于是便邀callback来相助。
函数指针是C和C++用来实现callback(回调函数)的一种方式。此外,抽象类(abstract class)、接口(interface)、C++中的泛型函子(generic functor)和C#中的委托(delegate)都可以实现callback。
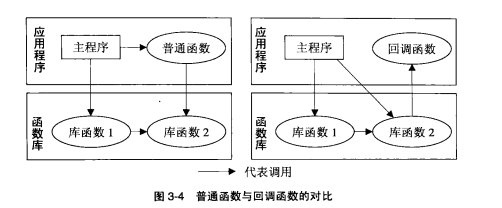
时间驱动式编程的3个步骤:实现事件处理器;注册事件处理器;实现事件循环。
它的主要特征是被动性和异步性。被动性来自控制反转,异步性来自会话切换。
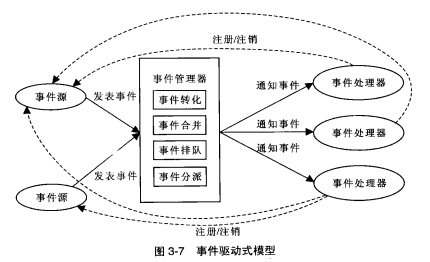
事件处理器事先在关注的事件源上注册,后者不定期地发表事件对象,经过事件管理器的转化(translate)、合并(coalesce)、排队(enqueue)、分派(dispatch)等集中处理后,事件处理器接收到事件并对其进行相应处理。通过事件机制,事件源与事件处理器之间建立了松耦合的多对多关系:一个事件源可以有多个处理器,一个处理器可以监听多个事件源。
发行/订阅模式(publish-subscribe pattern)正是观察者模式(observer pattern)的别名,一方面可看作简化或退化的事件驱动式,另一方面可看作事件驱动式的核心思想。该模式省略了事件管理器部分,由事件源直接调用事件处理器的接口,这样更加简明易用,但威力有所削弱,缺少事件管理、事件连带等机制。著名的MVC架构正是它在架构设计上的一个应用。
事件驱动式的应用极广,变化极多,还涉及框架、设计模式、架构,以及其他的编程范式,本身也可作为一种架构模型。
IoC 控制反转
一般library中用到callback只是局部的控制反转,而framework将IoC机制用到全局,程序员牺牲了对应用程序流程的主导权,换来的是更简洁的代码和更高的生产效率。控制反转不仅增强了framework在代码和设计上的重用性,还极大地提高了framework的可拓展性。这是因为framework的内部运转机制虽是封闭的,但也开放了不少与外部相连的扩展接口点,类似插件(plugins)体系。
控制反转的主要作用是降低模块之间的依赖性,从而降低模块的耦合度和复杂度,提高软件的可重用性、柔韧性和可拓展性,但对可伸缩性并无太大帮助。
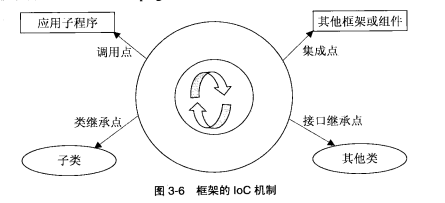
依赖反转原则(Dependency-Inversion Principle, DIP)比IoC更具体——高层模块不应依赖低层模块,他们都应依赖抽象;抽象不应依赖细节,细节应依赖抽象。经常相提并论的还有依赖注射(Dependency Injection,DI)——动态地为一个软件组件提供外部依赖。
他们的主题是控制与依赖,目的是解耦,方法是反转,而实现这一切的关键是抽象接口。
回调强调的是行为方式——低层反调高层,而”抽象接口“强调的是实现方式——正是由于接口具有抽象性,低层才能在调用它时无须虑及高层的具体细节,从而实现控制反转。
独立是异步的前提,耗时是异步的理由。
异步过程在主程序中以非堵塞的机制运行,即主程序不必等待该过程的返回就能继续下一步。异步机制能减少随机因素造成的资源浪费,提高系统的性能和可伸缩性。
阻塞呼叫
程序中一些函数须要等待某些数据而不能立即返回,从而堵塞整个进程。
版本化
理想情况下,一个程序员对程序的贡献都应该保存在版本控制系统(version control system)中,一遍跟踪、比较、改进、借鉴和再生成。
递归和迭代
从概念上讲,递归就是指程序调用自身的编程思想,即一个函数调用本身;迭代是利用已知的变量值,根据递推公式不断演进得到变量新值得编程思想。
如1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 递归
function recursion (num) {
if (num < 100) {
return recursion(num + 1)
} else {
return num;
}
}
// 迭代
function iteration (num) {
while (num < 100) {
num += 1
}
return num;
}
递归中一定有迭代,但是迭代中不一定有递归。递归实际上不断地深层调用函数,直到函数有返回才会逐层的返回,因此,递归涉及到运行时的堆栈开销(overhead)(参数必须压入堆栈保存,直到该层函数调用返回为止),所以有可能导致堆栈溢出的错误;但是递归编程所体现的思想正是人们追求简洁、将问题交给计算机,以及将大问题分解为相同小问题从而解决大问题的动机。从执行效率上来讲,底层(迭代)往往比高层(递归)来的高,但高层(递归)却能提供更加抽象的服务,更加的简洁。
迭代着眼微观过程而递归着眼宏观规律。
尾递归(tail recursion)是一种特殊的递归,其递归调用出现在函数的最后一步运算,这类递归很容易通过手工活编译器转化为迭代形式,以优化性能。js尾递归优化,在ES6的严格模式下才实现。
框架与库/工具包的不同
框架就是一组协同工作的类,它们为特定类型的软件构筑了一个可重用的设计。与库和工具包不同之处在于前者侧重设计重用而后两者侧重代码重用。库和工具包是为程序员带来自由的,框架是为程序员带来约束的。具体地说,库和工具包是为程序员提供武器装备的,框架则利用控制反转(IoC)机制实现对各模块的统一调度,从而剥夺了程序员对全局的掌控权,使他们成为手执编程武器、随时听候调遣的士兵。
控制反转(Inversion of Control)是一种软件设计原则。与通常的用户代码调用可重用的库代码不同,IoC倒转了控制流方向:由库代码调用用户代码。有人将此比作好莱坞法则:不要打电话给我们,我们会打给你的。
通常在工作中,在宏观管理上选取一些框架以控制整体的结构和流程;在微观实现上利用库和工具包来解决具体的细节问题。框架的意义在于使设计者在特定领域的整体设计上不必重新发明轮子;库和工具包的意义在于使开发者摆脱底层编码,专注特定问题和业务逻辑。
设计模式(design pattern)和架构(architecture)
设计模式和架构不是软件产品,而是软件思想。设计模式是软件的战术思想,架构是软件的战略决策。设计模式是针对某些经常出现的问题而提出的行之有效的设计解决方案,它侧重思想重用,因此比框架更抽象、更普适,但多限于局部解决方案,没有框架的整体性。与之相似的还有惯用法(idiom),也是针对常发问题的解决方案,但偏重实现而非设计,与实现语言密切相关,是一种更底层更具体的编程技巧。至于架构,一般指一个软件系统的最高层次的整体结构和规划,一个架构可能包含多个框架,而一个框架可能包含多个设计模式。
计算机的行为只有两种:确定性和随机性。当你一步步地闯关来到这里就是确定行为,当你随意点了个链接就来到这里就是随机行为。
动态类型语言和鸭子类型
编程语言按照数据类型大体可以分为两类,一类是静态类型语言,另一类是动态类型语言。
- 静态类型语言在编译时便已确定变量的类型
- 动态类型语言的变量类型要到程序运行的时候,待变量被赋予某个值之后,才会具有某种类型。
JavaScript是一门典型的动态类型语言。
动态类型语言对变量类型的宽容给实际编码带来了很大的灵活性。由于无需进行类型检测,
我们可以尝试调用任何对象的任意方法,而无需去考虑它原本是否被设计为拥有该方法。
这一切都建立在鸭子类型(duck typing)的概念上,鸭子类型的通俗说法是:“如果它走起
路来像鸭子,叫起来也是鸭子,那么它就是鸭子。”
利用鸭子类型的思想,我们不必借助超类型的帮助,就能轻松地在动态类型语言中实现一个原则:“面向接口编程,而不是面向实现编程”。例如,一个对象若有push和pop方法,并且这些方法提供了正确的实现,它就可以被当作栈来使用。一个对象如果有length属性,也可以依照下标来存取属性(最好还要拥有slice和splice等方法),这个对象就可以被当作数组来使用。
前端架构
前端架构是一系列工具和流程的集合,旨在提升前端代码的质量,并实现高效、可持续的工作流。
前端架构师的职责
- 体系设计
- 工作规划
- 监督跟进
四个核心
- 代码
- 流程
- 测试
- 文档
设计的六大原则
总原则:开闭原则
定义:一个软件实体如类、模块或函数应该对扩展开放,对修改关闭。
简单的说就是,当一个软件实体需要扩展的时候,不要去修改原有的代码,而是去扩展原有的代码。其实开闭原则是最基础的一个原则,下面六个原则都是开闭原则的具体形态。
为什么要采用开闭原则:
- 对测试的影响:通过扩展实现变化,测试只需要对新增类进行单元测试即可,单元测试是孤立的,只需要保证新类提供的方法正确就行。而如果是修改类来实现变化,则该类相应的测试方法也都要随着重构,而且当类很复杂时难免存在遗漏情况。
- 可以提高复用性:避免以后维护人员为了修改一个微小的缺陷或增加新功能,却要在整个项目中到处查找相关的代码逐一修改。
- 提高可维护性:开发新功能时,扩展一个类往往比修改一个类更容易。
- 面向对象开发的要求
1. 单一职责原则(Single Responsibility Principle,SRP)
定义:应该有且仅有一个原因引起类的变更。
优点:
- 类的复杂性降低。类的职责单一,复杂性自然就降低了。
- 可读性高。
- 易维护。
- 变更引起的风险降低。
难点:
- “职责”和“变化原因”都是不可度量的,因项目、环境而异。
- 过细的划分会引起类的剧增,人为的增加系统的复杂性。
建议:
- 接口的设计一定要做到单一原则,类的设计尽量做到只有一个原因引起变化。
- 职责的划分需要根据项目和经验来权衡,既要保证职责的单一性,又要尽量避免过细的划分。
2. 里氏替换原则(Liskov Substitution Principle,LSP)
定义:所有引用基类的地方都必须能透明地使用其子类的对象。
继承的优点:
- 代码共享,提高代码的重用性。
- 提高代码的可扩展性。
- 提高产品或者项目的开放性。
继承的缺点:
- 继承是侵入式的,只要继承,就拥有了父类的属性和方法。
- 降低代码灵活性,子类拥有了父类的属性和方法,多了一些约束。
- 增强了耦合性。父类的常量、变量或方法改动时,必须还要考虑子类的修改,可能会有大段代码需要重构。
里氏替换原则四层含义:
- 子类必须完全实现父类的方法
- 在类中调用其他类时务必使用父类或接口,如若不能,则说明类的设计已经违背LSP原则。
如果子类不能完整的实现父类的方法,或者父类的方法在子类中发生畸变,这建议断开父子继承关系,采用依赖、聚集、组合等方式代替继承。 - 子类可以有自己的特性:即子类出现的地方父类未必可以出现。
- 覆盖父类的方法时输入参数可以被放大:输入参数类型宽于父类的类型的覆盖范围,例如 hashmap -> map。
- 覆盖父类的方法时输出参数可以被缩小
3. 依赖倒置原则(Dependence Inversion Principle,DIP)
定义:
- 高层模块不应该依赖低层模块,两者都要改依赖其抽象(模块间的依赖通过抽象产生,实现类不发生直接的依赖关系)
- 抽象不应该依赖细节(接口或者抽象类不依赖实现类)
- 细节可以依赖抽象(实现类依赖接口或者抽象类)
建议:
- 每个类尽量都有接口或抽象类。
- 变量的表面类型尽量是接口或抽象类。
- 任何类都不应该从具体类派生(其实只要不是超过两层的继承都是可以忍受的)。
- 尽量不要复写基类已实现的方法。
- 结合里氏替换原则使用。
面向接口编程:
- 接口负责定义 public 属性和方法,并且声明与其它对象的依赖关系,抽象类负责公共构造部分的实现,实现类准确实现业务逻辑,同时在适当的时候对父类进行细化。
4. 接口隔离原则
定义:客户端不应该依赖他不需要的接口,类之间的依赖关系应该建立在最小的接口上。
四层含义:
- 接口尽量要小,不要出现臃肿的接口。
- 接口要高内聚。
- 只提供访问者需要的方法:每个接口中不存在子类用不到却必须实现的方法,如果不然,就要将接口拆分。
- 接口设计是有限度的:接口设计粒度越小,系统越灵活。但是结构会越复杂、开发难度增加,可维护性降低。
建议:
- 一个接口只服务一个子模块或者业务逻辑。
- 尽量压缩接口内的方法,保证方法都是有用的,避免臃肿。
- 已经被污染的接口尽量去修改,若变更风险大,则采用适配器模式转化处理。
- 深入了解业务逻辑,拒绝盲从。
5. 迪克特法则(最少知道原则)(Least Knowledge Principle,LKP)
定义:一个对象应该对其他对象有最少的了解(低耦合)。
三层含义:
- 一个类只与朋友交流,不和陌生类交流,方法尽量不引入类中不存在的对象。
- 尽量不要对外暴露过多的 public 方法和非静态的 public 变量,尽量内敛。
- 自己的就是自己的。如果一个方法放在本类中,既不增加类间关系,也对本类不产生负面影响,那就放置在本类中。
总结:
迪米特法则的核心观念就是类间解耦,低耦合。其负面影响就是产生了大量的中转或者跳转类,导致系统复杂性提高,也为维护带来了难度。需要反复权衡,既做到结构清晰,又要高内聚低耦合。
如果一个类需要跳转两次以上才能访问到另一个类,就需要想办法重构了。
6. 合成复用原则(Composite/Aggregate Reuse Principle,CARP)
定义:是在一个新的对象里面使用一些已有的对象,使其成为新对象的一部分。新对象通过委派达到复用已有功能的效果。
优点:
- 使用对象的合成/聚合将有助于你保持每个类被封装,并被集中在单个任务上。这样类和集成层次会保持较小规模,并且不太可能增长为不可控制的庞然大物。
缺点:
- 通过这种方式复用建造的系统会有较多的对象需要管理;为了能将多个不同的对象作为组合块来使用,必须仔细地对接口进行定义。
简单地说:尽量首先使用合成/聚合的方式,而不是使用继承。
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com