【笔记】各种部署方式小记
May 9, 2020工程软件【笔记】各种部署方式小记
蓝绿部署(Blue-green Deployment)
蓝绿部署,是采用两个分开的集群对软件版本进行升级的一种方式。它的部署模型中包括一个蓝色集群 A 和一个绿色集群 B,在没有新版本上线的情况下,两个集群上运行的版本是一致的,同时对外提供服务。
系统升级时,蓝绿部署的流程是:

首先,从负载均衡器列表中删除集群 A,让集群 B 单独提供服务。
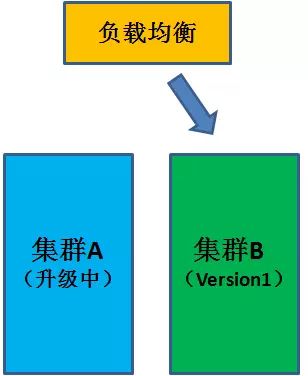
然后,在集群 A 上部署新版本。
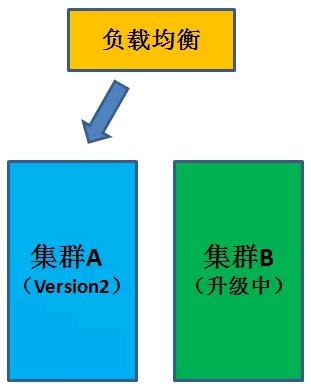
接下来,集群 A 升级完毕后,把负载均衡列表全部指向 A,并删除集群 B,由 A 单独提供服务。
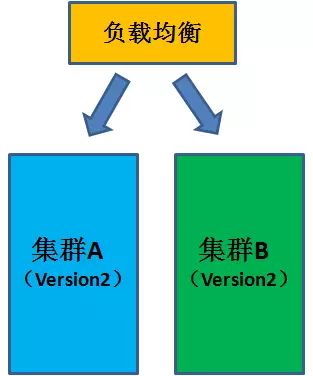
在集群 B 上部署完新版本后,再把它添加回负载均衡列表中。
这样,我们就完成了两个集群上所有机器的版本升级。
红黑部署(Red-black Deployment)
与蓝绿部署类似,红黑部署也是通过两个集群完成软件版本的升级。
当前提供服务的所有机器都运行在红色集群 A 中,当需要发布新版本的时候,具体流程是这样的:
先在云上申请一个黑色集群 B,在 B 上部署新版本的服务;
等到 B 升级完成后,我们一次性地把负载均衡全部指向 B;
把 A 集群从负载均衡列表中删除,并释放集群 A 中所有机器。
这样就完成了一个版本的升级。
可以看到,与蓝绿部署相比,红黑部署只不过是充分利用了云计算的弹性伸缩优势,从而获得了两个收益:一是,简化了流程;二是,避免了在升级的过程中,由于只有一半的服务器提供服务,而可能导致的系统过载问题。
至于这两种部署方式名字中的“蓝绿”“红黑”,只是为了方便讨论,给不同的集群取的名字而已,通过不同颜色表明它们会在系统升级时运行不同的版本。
滚动发布(rolling update)
在金丝雀发布基础上的进一步优化改进,是一种自动化程度较高的发布方式,用户体验比较平滑,是目前成熟型技术组织所采用的主流发布方式。
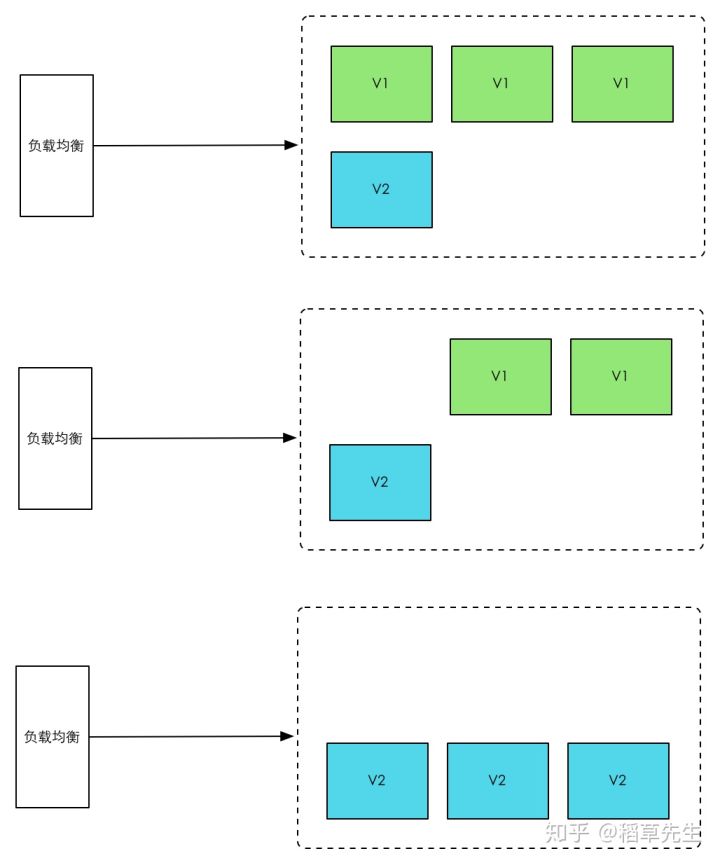
滚动发布,一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。这种部署方式相对于蓝绿部署,更加节约资源——它不需要运行两个集群、两倍的实例数。我们可以部分部署,例如每次只取出集群的20%进行升级。
这种方式也有很多缺点,例如:
- (1) 没有一个确定OK的环境。使用蓝绿部署,我们能够清晰地知道老版本是OK的,而使用滚动发布,我们无法确定。
- (2) 修改了现有的环境。
- (3) 如果需要回滚,很困难。举个例子,在某一次发布中,我们需要更新100个实例,每次更新10个实例,每次部署需要5分钟。当滚动发布到第80个实例时,发现了问题,需要回滚。此时,脾气不好的程序猿很可能想掀桌子,因为回滚是一个痛苦,并且漫长的过程。
- (4) 有的时候,我们还可能对系统进行动态伸缩,如果部署期间,系统自动扩容/缩容了,我们还需判断到底哪个节点使用的是哪个代码。尽管有一些自动化的运维工具,但是依然令人心惊胆战。
并不是说滚动发布不好,滚动发布也有它非常合适的场景。
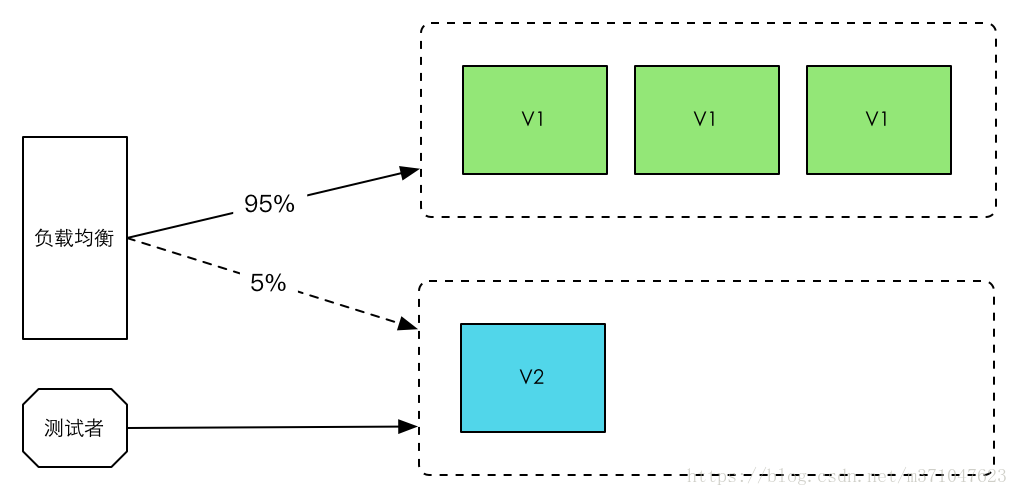
灰度发布(Gray Release ,或 Dark Launch)
灰度发布,也被叫作金丝雀发布。与蓝绿部署、红黑部署不同的是,灰度发布属于增量发布方法。也就是说,服务升级的过程中,新旧版本会同时为用户提供服务。
灰度发布的具体流程是这样的:
- 在集群的一小部分机器上部署新版本,给一部分用户使用,以测试新版本的功能和性能;
- 确认没有问题之后,再对整个集群进行升级。
简单地说,灰度发布就是把部署好的服务分批次、逐步暴露给越来越多的用户,直到最终完全上线。
之所以叫作灰度发布,是因为它介于黑与白之间,并不是版本之间的直接切换,而是一个平滑过渡的过程。
之所以又被叫作金丝雀发布,是因为金丝雀对瓦斯极其敏感,17 世纪时英国矿井工人会携带金丝雀下井,以便及时发现危险。这就与灰色发布过程中,先发布给一部分用户来测试相似,因而得名。
好了,以上就是几种有颜色的部署发布方式了。如果你还有哪些地方理解得不够透彻,可以去网络上搜索相关文章,或者直接给我留言吧。接下来,我将继续按照黄金圈法则,来帮助你深入了解这些部署、发布方式的 Why、How 和 What。
灰度发布/金丝雀部署适用的场景:
- 1、不停止老版本,额外搞一套新版本,不同版本应用共存。
- 2、灰度发布中,常常按照用户设置路由权重,例如90%的用户维持使用老版本,10%的用户尝鲜新版本。
- 3、经常与A/B测试一起使用,用于测试选择多种方案。AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。
蓝绿、红黑部署和灰度发布的 Why
究其根本,这些部署、发布方法,是为了解决频繁发布的生产模式带来的两个问题:
减少发布过程中新旧服务切换造成的服务停止时间。蓝绿部署和红黑部署都能实现无宕机时间部署(0 downtime deployment)。
控制新版本发布因为质量问题带来的风险。灰度发布就是一个例子。
蓝绿、红黑部署和灰度发布 What
关于提高上线产品的效率,实践主要有两个:一是利用负载均衡切换线上流量,二是使用功能开关切换线上流量。这两种方法都比较简单。
而提高上线产品的安全性,相对来说就比较复杂了,但又很重要。因为在敏捷、持续交付等开发模式愈发流行的今天,产品的研发节奏越来越快,我们必须在上线过程中,在生产环境上进行更多的测试,以保证产品质量。
讲到这里,你可能一下就想到了,这正是我们在上一篇文章中提到的测试右移要做的工作。接下来,我就与你分别介绍如何在部署、发布、发布后这 3 个阶段提高上线产品的安全性,也就是测试右移的实践。
部署阶段的实践
在部署阶段,因为服务还没有真正面对用户,所以比较安全。在这一步,我们可以尽量运行比较多的检验。但一定要注意的是,我们在运行检验的时候,不能产生副作用,也就是不能影响到正在给用户提供服务的系统。具体来说,我们可以运行集成测试、流量镜像(shadowing,也叫作 Dark Traffic Testing or Mirroring)、压测和配置方面的测试这 4 种检验。
第一种检验是,集成测试。
集成测试,指的是对模块之间的接口,以及模块组成的子系统进行的测试,介于单元测试和系统测试之间。
传统的集成测试是在测试环境或类生产环境上进行的。这种方式的问题在于,测试运行的环境和生产环境差别较大,不容易发现生产环境可能会出现的问题。一个最典型的原因是,在这些非生产环境上,只有测试用例在运行,没有在处理任何真实的用户请求,所以在生产环境中运行集成测试,才可能发现在非生产环境上难以发现的问题。
在具体进行集成测试的时候,如果所做的操作没有产生数据,也就是不会产生副作用,会比较安全。如果产生了数据,我们一般有两种处理方法:
第 1 种方法是,对测试产生的数据添加一个“测试”标签。同时代码的逻辑,对有测试标签的数据都进行特殊处理,比如说完全忽略。
第 2 种方法是,对测试用例产生的请求,就直接不写数据。具体实现方法是,在业务里直接添加这个特殊处理的逻辑。如果你使用的是服务网格(Service Mesh),则可以使用服务的代理(比如 Sidecar Proxy)来进行处理。
第二种检验是,流量镜像。
流量镜像,指的是对线上流量的全部或者一部分进行复制,并把复制的流量定向到还没有面向用户的服务实例上,从而达到使用线上流量进行测试的效果。
关于引流的实现,通常是使用代理,比如 Envoy Proxy 和 Istio 配合使用。如果你想深入了解引流的实现方式,可以参考“使用 Envoy 做镜像引流”这篇文章。
需要注意的是,使用引流进行测试时,不能给生产环境带来副作用。具体办法与集成测试的处理方法类似,我们也可以给引流产生的数据打标签,在流量复制的时候,对复制的请求统一添加一个特殊字段(比如 shadow),从而让接收到请求的服务可以对其进行特殊处理。
使用流量镜像,除了普通的检测之外,还有一个比较有用的实践就是,对测试流量与实时服务流量的运行结果进行对比,来检查新服务的运行是否符合预期。Twitter 在 2015 年开源了一款这样的代理工具Diffy ,它可以在镜像流量的同时调用线上服务和新服务,并对结果进行对比。
第三种检验是,压测。
压测,也是在部署阶段比较有价值的一种测试方法。比如,我们可以把新服务部署到一个比较小的集群上,然后把线上环境的流量全部复制并指向这个新集群,以相对客观地了解最新服务的抗压能力。
第四种检验是,配置方面的测试。
系统配置方面的变更,一旦出现问题,往往会给业务带来重大损失。部署阶段,因为不直接面向用户,所以是测试配置变更的好时机。
如果你想深入了解这部分内容的细节,可以参考Facebook 关于可靠性的见解这篇文章。
发布阶段的实践
在发布阶段,我们可以使用金丝雀发布和监控两种方法,来及早发现错误,并减少错误带来的损失。
第一个方法是,金丝雀发布。
金丝雀发布,是发布阶段最基本、最常见的实践。这里,我两个小贴士:
让金丝雀服务先面向内部用户,也就是 Dogfooding,来降低出现问题时造成的损失。
最近几年出现的一些部署工具和平台,比如 Spinnaker,已经对金丝雀发布有了比较好的支持。你可以考虑直接使用,降低引入成本。
第二个方法是,监控。
监控,是安全发布必不可少的关键环节,其重要性不言自明。在发布过程中,我们应该注意监测用户请求失败率、用户请求处理时长和异常出现数量这几个信息,以保证快速发现问题并及时回滚。
发布后的实践
产品成功发布之后,我们的主要工作就是监控和补救,具体实践包括三个:监控、A/B 测试和混沌工程(Chaos Engineering)。
第一个实践是,监控。
服务上线后,我们需要提供有效的监控,来了解服务的质量。关于监控的内容,我推荐参考可观察性(Observability)的三大支柱,即日志、度量和分布式追踪。如果你想深入了解这部分内容,推荐你看一下这篇文章。
第二个实践是,A/B 测试。
系统上线之后发现问题,有一个快速的补救办法是,继续使用旧的服务代码。对于这一点,我们可以通过 A/B 测试的方法来实现。
也就是说,添加风险比较大的新功能时,使用 A/B 测试让新旧功能并存,通过配置或者功能开关决定使用哪一个版本服务用户。如果发现新功能实现有重大问题,可以马上更改配置(而不需要重新部署服务),就能重新启用旧版本。
第三个实践是,混沌工程。
混沌工程,指的是主动地在生产环境中引入错误,来测试系统的可靠性的工程方法。最早为人熟知的混沌工程,是网飞(Netflix)公司的 Chaos Monkey。这种方法可以引入的错误主要包括:
杀死系统中的节点,比如关闭服务器;
引入网络阻塞的情况;
切断某些网路链接。
不过,一般是在公司达到了很好的稳定性之后,对稳定性有更上一层楼的需求时,或者是对稳定性要求特别高的公司,混沌工程的价值才比较大。
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com