【工具】性能测试中QPS、TPS等字段含义
Aug 8, 2020工具性能质量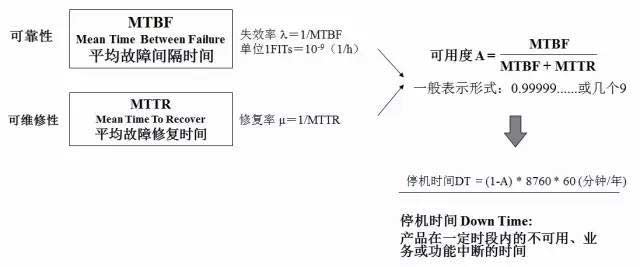
性能测试中QPS、TPS等字段含义
访问相关名词
PV
PV(Page View):页面访问量,每次用户访问或者刷新页面都会被计算在内。
UV
UV(Unique visitor):是指通过互联网访问、浏览这个网页的自然人。访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只被计算一次。一天内同个访客多次访问仅计算一个UV。
IP
IP(Internet Protocol):独立IP是指访问过某站点的IP总数,以用户的IP地址作为统计依据。00:00-24:00内相同IP地址之被计算一次。
VV
VV(Visit View):用以统计所有访客1天内访问网站的次数。当访客完成所有浏览并最终关掉该网站的所有页面时便完成了一次访问,同一访客1天内可能有多次访问行为,访问次数累计。
容量评估相关名词
RT
RT(Response Time):响应时间是指系统对请求作出响应的时间。直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的处理逻辑也千差万别,因而不同功能的响应时间也不尽相同,甚至同一功能在不同输入数据的情况下响应时间也不相同。所以,在讨论一个系统的响应时间时,人们通常是指该系统所有功能的平均时间或者所有功能的最大响应时间。当然,往往也需要对每个或每组功能讨论其平均响应时间和最大响应时间。
对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。需要指出的是,响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的。
RT计算
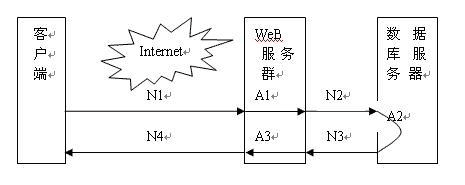
- 网络传输时间:
N1 + N2 + N3 + N4 - 应用服务器处理时间:
A1 + A3 - 数据库服务器处理时间:
A2
响应时间 = N1 + N2 + N3 + N4 + A1 + A3 + A2
TP
TP(Throughput):吞吐量是指系统在单位时间内处理请求的数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数。前面已经说过,对于单用户的系统,响应时间(或者系统响应时间和应用延迟时间)可以很好地度量系统的性能,但对于并发系统,通常需要用吞吐量作为性能指标。
对于一个多用户的系统,如果只有一个用户使用时系统的平均响应时间是t,当有你n个用户使用时,每个用户看到的响应时间通常并不是n×t,而往往比n×t小很多(当然,在某些特殊情况下也可能比n×t大,甚至大很多)。这是因为处理每个请求需要用到很多资源,由于每个请求的处理过程中有许多不走难以并发执行,这导致在具体的一个时间点,所占资源往往并不多。也就是说在处理单个请求时,在每个时间点都可能有许多资源被闲置,当处理多个请求时,如果资源配置合理,每个用户看到的平均响应时间并不随用户数的增加而线性增加。实际上,不同系统的平均响应时间随用户数增加而增长的速度也不大相同,这也是采用吞吐量来度量并发系统的性能的主要原因。一般而言,吞吐量是一个比较通用的指标,两个具有不同用户数和用户使用模式的系统,如果其最大吞吐量基本一致,则可以判断两个系统的处理能力基本一致。
VU
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。在性能测试工具中,一般称为虚拟用户数(Virutal User),注意并发用户数跟注册用户数、在线用户数有很大差别的,并发用户数一定会对服务器产生压力的,而在线用户数只是 ”挂” 在系统上,对服务器不产生压力,注册用户数一般指的是数据库中存在的用户数。
- 处理能力: 简称TPS, 每秒事务数, 是衡量系统性能的一个非常重要的指标。
- 响应时间:简称RT,指的是业务从客户端发起到客户端接受的时间。
与吞吐量TP相比,并发用户数是一个更直观但也更笼统的性能指标。实际上,并发用户数是一个非常不准确的指标,因为用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求。一网站系统为例,假设用户只有注册后才能使用,但注册用户并不是每时每刻都在使用该网站,因此具体一个时刻只有部分注册用户同时在线,在线用户就在浏览网站时会花很多时间阅读网站上的信息,因而具体一个时刻只有部分在线用户同时向系统发出请求。这样,对于网站系统我们会有三个关于用户数的统计数字:注册用户数、在线用户数和同时发请求用户数。由于注册用户可能长时间不登陆网站,使用注册用户数作为性能指标会造成很大的误差。而在线用户数和同事发请求用户数都可以作为性能指标。相比而言,以在线用户作为性能指标更直观些,而以同时发请求用户数作为性能指标更准确些。
TPS
TPS(Transactions Per Second):每秒事务数,每秒系统能够处理的事务次数。
VU与TPS换算
假如1个虚拟用户在1秒内完成1笔事务,那么TPS明显就是1;如果某笔业务响应时间是1ms,那么1个用户在1秒内能完成1000笔事务,TPS就是1000了;如果某笔业务响应时间是1s,那么1个用户在1秒内只能完成1笔事务,要想达到1000TPS,至少需要1000个用户;因此可以说1个用户可以产生1000TPS,1000个用户也可以产生1000TPS,无非是看响应时间快慢。比如 1000 并发,RT 平均从 1 秒变长到 2 秒,那么 TPS 也从 1000 下降到了 500。
QPS
QPS(Query Per Second):每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。 (看来是类似于TPS,只是应用于特定场景的吞吐量)。
峰值QPS
- 原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
- 公式:
( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)。 - 机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 。
每天300w PV 的在单台机器上,这台机器需要多少QPS?1
( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)。
一般需要达到139QPS,因为是峰值。
TPS与QPS
一个TPS可能包含多个QPS:事务表示客户端发起请求到收到服务端最终响应的整个过程,这是一个TPS。
而在这个TPS中,为了处理第一次请求可能会引发后续多次对服务端的访问才能完成这次工作,每次访问都算一个QPS。
*OPS
Operates Per Second,一般是操作次数,与qps区别不大。
系统可靠性相关
MTBF
MTBF(Mean Time Between Failure):平均故障间隔时间,是衡量一个产品(尤其是电器产品)的可靠性指标。单位为“小时”。具体来说,是指相邻两次故障之间的平均工作时间,也称为平均故障间隔。概括地说,产品故障少的就是可靠性高,产品的故障总数与寿命单位总数之比叫“故障率”(Failure rate)。它仅适用于可维修产品。同时也规定产品在总的使用阶段累计工作时间与故障次数的比值为MTBF。磁盘阵列产品一般MTBF不能低于50000小时。
λ
失效率是指工作到某一时刻尚未失效的产品,在该时刻后,单位时间内发生失效的概率。一般记为λ,它也是时间t的函数,故也记为λ(t),称为失效率函数,有时也称为故障率函数或风险函数。
失效率λ=1/MTBF,单位1FITs=10-9(1/h)
MTTR
MTTR(Mean Time To Repair):平均修复时间。是指可修复产品的平均修复时间,就是从出现故障到修复中间的这段时间。MTTR越短表示易恢复性越好。
MTTR也必须包含获得配件的时间,维修团队的响应时间,记录所有任务的时间,还有将设备重新投入使用的时间。是一个缩写的平均时间恢复或平均修复时间代表的平均时间将有缺陷的部件或系统恢复工作秩序。 它是衡量一个系统的可维护性和可预测的平均所需的时间让系统工作的情况下再次出现系统故障。 MTTR可以从几个毫秒,如不间断电源(UPS)的许多数小时甚至数天的情况下的应用软件或复杂的机制。
μ
修复率repair rate 产品维修性的一种基本参数。修理时间已达到某个时刻但尚未修复的产品,在该时刻后的单位时间内完成修理的概率。
5个9、4个9、3个9
在系统的高可靠性(也称为可用性,英文描述为HA,High Available)里有个衡量其可靠性的标准——X个9,这个X是代表数字3~5。X个9表示在系统1年时间的使用过程中,系统可以正常使用时间与总时间(1年)之比,我们通过下面的计算来感受下X个9在不同级别的可靠性差异。
3个9:(1-99.9%)36524=8.76小时,表示该系统在连续运行1年时间里最多可能的业务中断时间是8.76小时。
4个9:(1-99.99%)36524=0.876小时=52.6分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟。
5个9:(1-99.999%)36524*60=5.26分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟。
SLA
SLA(service-level agreement):服务级别协议,也称服务等级协议、服务水平协议,是服务提供商与客户之间定义的正式承诺。SLA的概念,对互联网公司来说就是网站服务可用性的一个保证。
SLA包括两个要素,一个是SLI,一个是SLO,其中SLI定义的是测量指标;SLO定义的是服务提供的一种状态。
SLI:SLI是经过仔细定义的测量指标,它根据不同系统特点确定要测量什么,SLI的确定是一个非常复杂的过程。SLI确定测量的具体指标,在确定具体指标的时候,需要做到该指标能否准确描述服务质量以及该指标是否可靠。
SLO:SLO(服务等级目标)指定了服务所提供功能的一种期望状态,包含所有能够描述服务应该提供什么样功能的信息。一般描述为:每分钟平均qps > 100k/s;99% 访问延迟 < 500ms;99% 每分钟带宽 > 200MB/s。
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com