【笔记】《浏览器原理与实践》2.页面渲染
May 4, 2019笔记js浏览器
2.页面渲染
2.1 导航流程
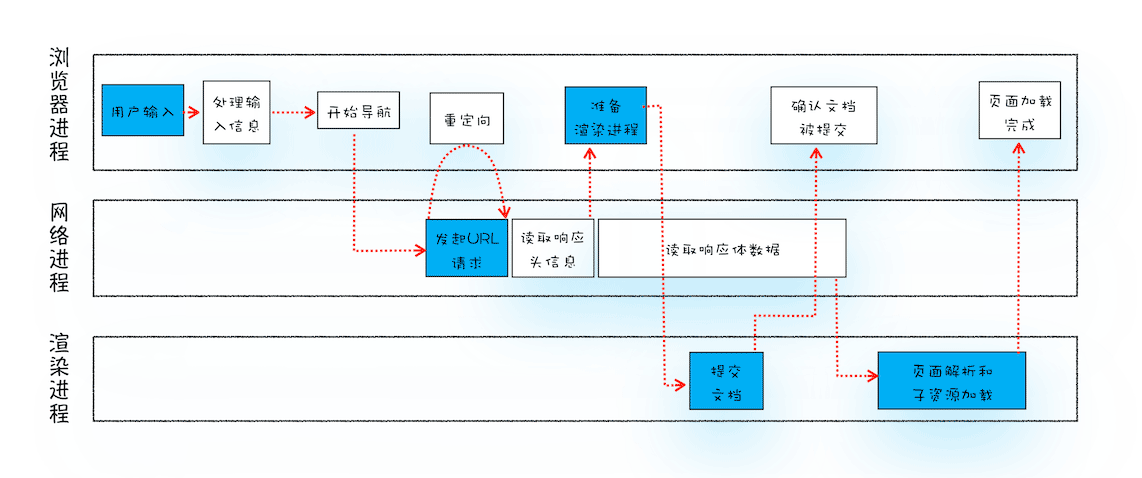
从输入 URL 到页面展示完整流程示意图
从图中可以看出,整个过程需要各个进程之间的配合,所以在开始正式流程之前,我们还是先来快速回顾下浏览器进程、渲染进程和网络进程的主要职责。
- 浏览器进程主要负责用户交互、子进程管理和文件储存等功能。
- 网络进程是面向渲染进程和浏览器进程等提供网络下载功能。
- 渲染进程的主要职责是把从网络下载的 HTML、JavaScript、CSS、图片等资源解析为可以显示和交互的页面。因为渲染进程所有的内容都是通过网络获取的,会存在一些恶意代码利用浏览器漏洞对系统进行攻击,所以运行在渲染进程里面的代码是不被信任的。这也是为什么 Chrome 会让渲染进程运行在安全沙箱里,就是为了保证系统的安全。
这个过程可以大致描述为如下:
- 首先,用户从浏览器进程里输入请求信息;
- 然后,网络进程发起 URL 请求;
- 服务器响应 URL 请求之后,浏览器进程就又要开始准备渲染进程了;
- 渲染进程准备好之后,需要先向渲染进程提交页面数据,我们称之为提交文档阶段;
- 渲染进程接收完文档信息之后,便开始解析页面和加载子资源,完成页面的渲染。
这其中,用户发出 URL 请求到页面开始解析的这个过程,就叫做导航。
从输入URL到页面展示
知道了浏览器的几个主要进程的职责之后,那么接下来,我们就从浏览器的地址栏开始讲起。
1.用户输入
当用户在地址栏中输入一个查询关键字时,地址栏会判断输入的关键字是搜索内容,还是请求的 URL。
如果是搜索内容,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键字的 URL。
如果判断输入内容符合 URL 规则,比如输入的是 blog.michealwayne.cn,那么地址栏会根据规则,把这段内容加上协议,合成为完整的 URL,如 https://blog.michealwayne.cn。
从图中可以看出,当浏览器刚开始加载一个地址之后,标签页上的图标便进入了加载状态。但此时图中页面显示的依然是之前打开的页面内容,并没立即替换为极客时间的页面。因为需要等待提交文档阶段,页面内容才会被替换。
2.URL请求过程
接下来,便进入了页面资源请求过程。这时,浏览器进程会通过进程间通信(IPC)把 URL 请求发送至网络进程,网络进程接收到 URL 请求后,会在这里发起真正的 URL 请求流程。那具体流程是怎样的呢?
首先,网络进程会查找本地缓存是否缓存了该资源。如果有缓存资源,那么直接返回资源给浏览器进程;如果在缓存中没有查找到资源,那么直接进入网络请求流程。这请求前的第一步是要进行 DNS 解析,以获取请求域名的服务器 IP 地址。如果请求协议是 HTTPS,那么还需要建立 TLS 连接。
接下来就是利用 IP 地址和服务器建立 TCP 连接。连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的 Cookie 等数据附加到请求头中,然后向服务器发送构建的请求信息。
服务器接收到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程。等网络进程接收了响应行和响应头之后,就开始解析响应头的内容了。(为了方便讲述,下面我将服务器返回的响应头和响应行统称为响应头。)
(1)重定向
在接收到服务器返回的响应头后,网络进程开始解析响应头,如果发现返回的状态码是 301 或者 302,那么说明服务器需要浏览器重定向到其他 URL。这时网络进程会从响应头的 Location 字段里面读取重定向的地址,然后再发起新的 HTTP 或者 HTTPS 请求,一切又重头开始了。在导航过程中,如果服务器响应行的状态码包含了 301、302 一类的跳转信息,浏览器会跳转到新的地址继续导航;如果响应行是 200,那么表示浏览器可以继续处理该请求。
(2)响应数据类型处理
在处理了跳转信息之后,我们继续导航流程的分析。URL 请求的数据类型,有时候是一个下载类型,有时候是正常的 HTML 页面,那么浏览器是如何区分它们呢?
答案是 Content-Type。Content-Type 是 HTTP 头中一个非常重要的字段, 它告诉浏览器服务器返回的响应体数据是什么类型,然后浏览器会根据 Content-Type 的值来决定如何显示响应体的内容。
从返回的响应头信息来看,其 Content-Type 的值是 application/octet-stream,显示数据是字节流类型的,通常情况下,浏览器会按照下载类型来处理该请求。
需要注意的是,如果服务器配置 Content-Type 不正确,比如将 text/html 类型配置成 application/octet-stream 类型,那么浏览器可能会曲解文件内容,比如会将一个本来是用来展示的页面,变成了一个下载文件。
所以,不同 Content-Type 的后续处理流程也截然不同。如果 Content-Type 字段的值被浏览器判断为下载类型,那么该请求会被提交给浏览器的下载管理器,同时该 URL 请求的导航流程就此结束。但如果是HTML,那么浏览器则会继续进行导航流程。由于 Chrome 的页面渲染是运行在渲染进程中的,所以接下来就需要准备渲染进程了。
3.准备渲染进程
默认情况下,Chrome 会为每个页面分配一个渲染进程,也就是说,每打开一个新页面就会配套创建一个新的渲染进程。但是,也有一些例外,在某些情况下,浏览器会让多个页面直接运行在同一个渲染进程中。
Chrome 的默认策略是,每个标签对应一个渲染进程。但如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。官方把这个默认策略叫 process-per-site-instance。
渲染进程策略就是:
- 通常情况下,打开新的页面都会使用单独的渲染进程;
- 如果从 A 页面打开 B 页面,且 A 和 B 都属于同一站点的话,那么 B 页面复用 A 页面的渲染进程;如果是其他情况,浏览器进程则会为 B 创建一个新的渲染进程。
渲染进程准备好之后,还不能立即进入文档解析状态,因为此时的文档数据还在网络进程中,并没有提交给渲染进程,所以下一步就进入了提交文档阶段。
4.提交文档
首先要明确一点,这里的“文档”是指 URL 请求的响应体数据。
- “提交文档”的消息是由浏览器进程发出的,渲染进程接收到“提交文档”的消息后,会和网络进程建立传输数据的“管道”。
- 等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程。
- 浏览器进程在收到“确认提交”的消息后,会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 页面。
这也就解释了为什么在浏览器的地址栏里面输入了一个地址后,之前的页面没有立马消失,而是要加载一会儿才会更新页面。
到这里,一个完整的导航流程就“走”完了,这之后就要进入渲染阶段了。
5.渲染阶段
一旦文档被提交,渲染进程便开始页面解析和子资源加载了,关于这个阶段的完整过程,我会在下一篇文章中来专门介绍。这里你只需要先了解一旦页面生成完成,渲染进程会发送一个消息给浏览器进程,浏览器接收到消息后,会停止标签图标上的加载动画。
2.2 浏览器处理HTML、CSS和JavaScript
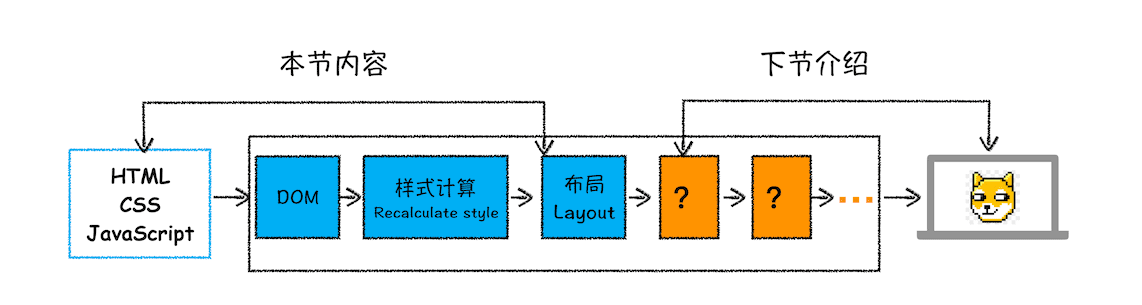
由于渲染机制过于复杂,所以渲染模块在执行过程中会被划分为很多子阶段,输入的 HTML 经过这些子阶段,最后输出像素。我们把这样的一个处理流程叫做渲染流水线,其大致流程如下图所示:
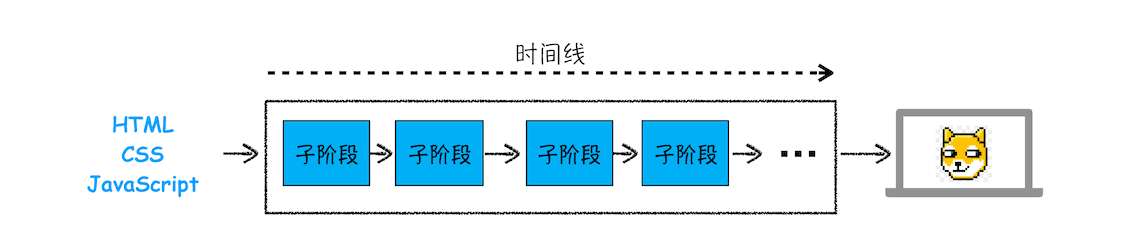
渲染流水线示意图
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、绘制、分块、光栅化和合成。内容比较多,我会用两篇文章来为你详细讲解这各个子阶段。接下来,在介绍每个阶段的过程中,你应该重点关注以下三点内容:
- 开始每个子阶段都有其输入的内容;
- 然后每个子阶段有其处理过程;
- 最终每个子阶段会生成输出内容。
理解了这三部分内容,能让你更加清晰地理解每个子阶段。
构建 DOM 树
为什么要构建 DOM 树呢?这是因为浏览器无法直接理解和使用 HTML,所以需要将 HTML 转换为浏览器能够理解的结构——DOM 树。
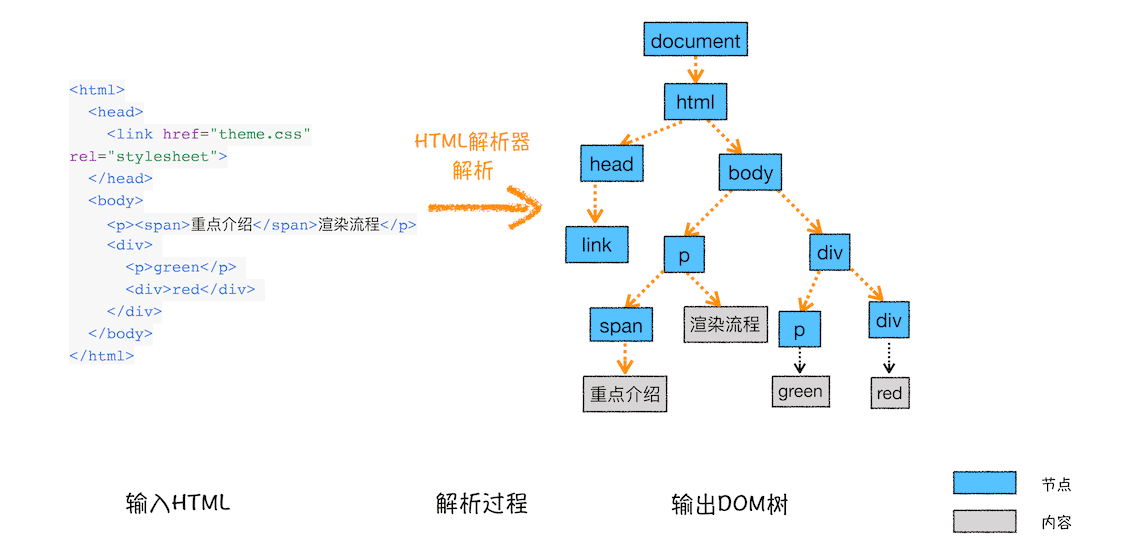
DOM 树构建过程示意图
构建 DOM 树的输入内容是一个非常简单的 HTML 文件,然后经由 HTML 解析器解析,最终输出树状结构的 DOM。
样式计算(Recalculate Style)
样式计算的目的是为了计算出 DOM 节点中每个元素的具体样式,这个阶段大体可分为三步来完成。
1.把CSS转换为浏览器能够理解的结构:和 HTML 文件一样,浏览器也是无法直接理解这些纯文本的 CSS 样式,所以当渲染引擎接收到 CSS 文本时,会执行一个转换操作,将 CSS 文本转换为浏览器可以理解的结构——styleSheets。并且该结构同时具备了查询和修改功能,这会为后面的样式操作提供基础。
2.转换样式表中的属性值,使其标准化:要理解什么是属性值标准化,你可以看下面这样一段 CSS 文本:
1
2
3
4
5
6body { font-size: 2em }
p {color:blue;}
span {display: none}
div {font-weight: bold}
div p {color:green;}
div {color:red; }可以看到上面的 CSS 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。
那标准化后的属性值是什么样子的?
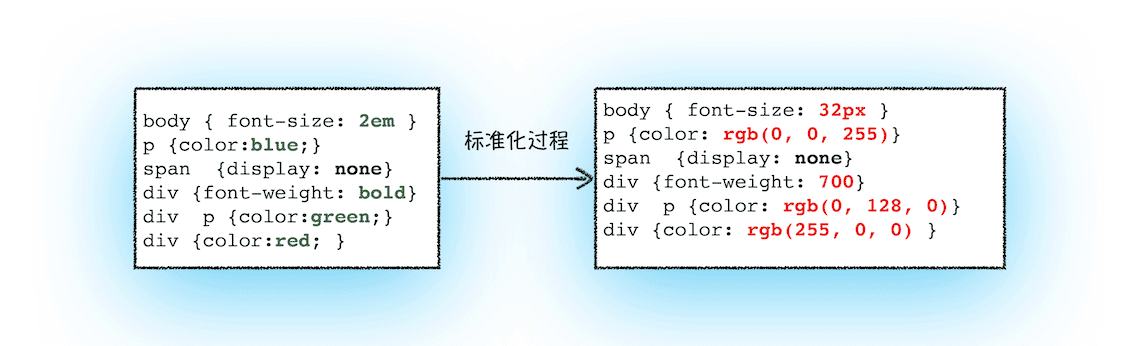
标准化属性值
3.计算出DOM树中每个节点的具体样式:
这就涉及到 CSS 的继承规则和层叠规则了。
首先是 CSS 继承。CSS 继承就是每个 DOM 节点都包含有父节点的样式。这么说可能有点抽象,我们可以结合具体例子,看下面这样一张样式表是如何应用到 DOM 节点上的。
1 | body { font-size: 20px } |
这张样式表最终应用到 DOM 节点的效果如下图所示:
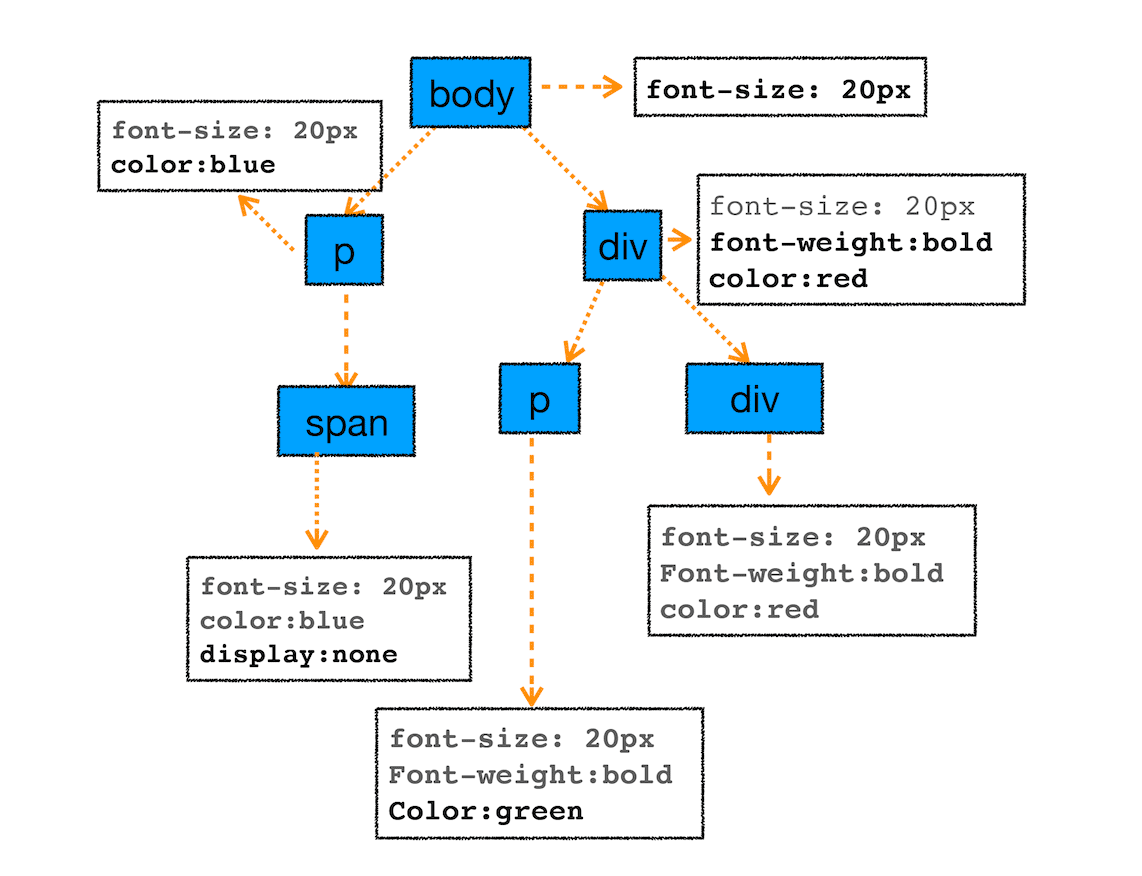
计算后 DOM 的样式
从图中可以看出,所有子节点都继承了父节点样式。比如 body 节点的 font-size 属性是 20,那 body 节点下面的所有节点的 font-size 都等于 20。
为了加深你对 CSS 继承的理解,你可以打开 Chrome 的“开发者工具”,选择第一个“element”标签,再选择“style”子标签,你会看到如下界面:
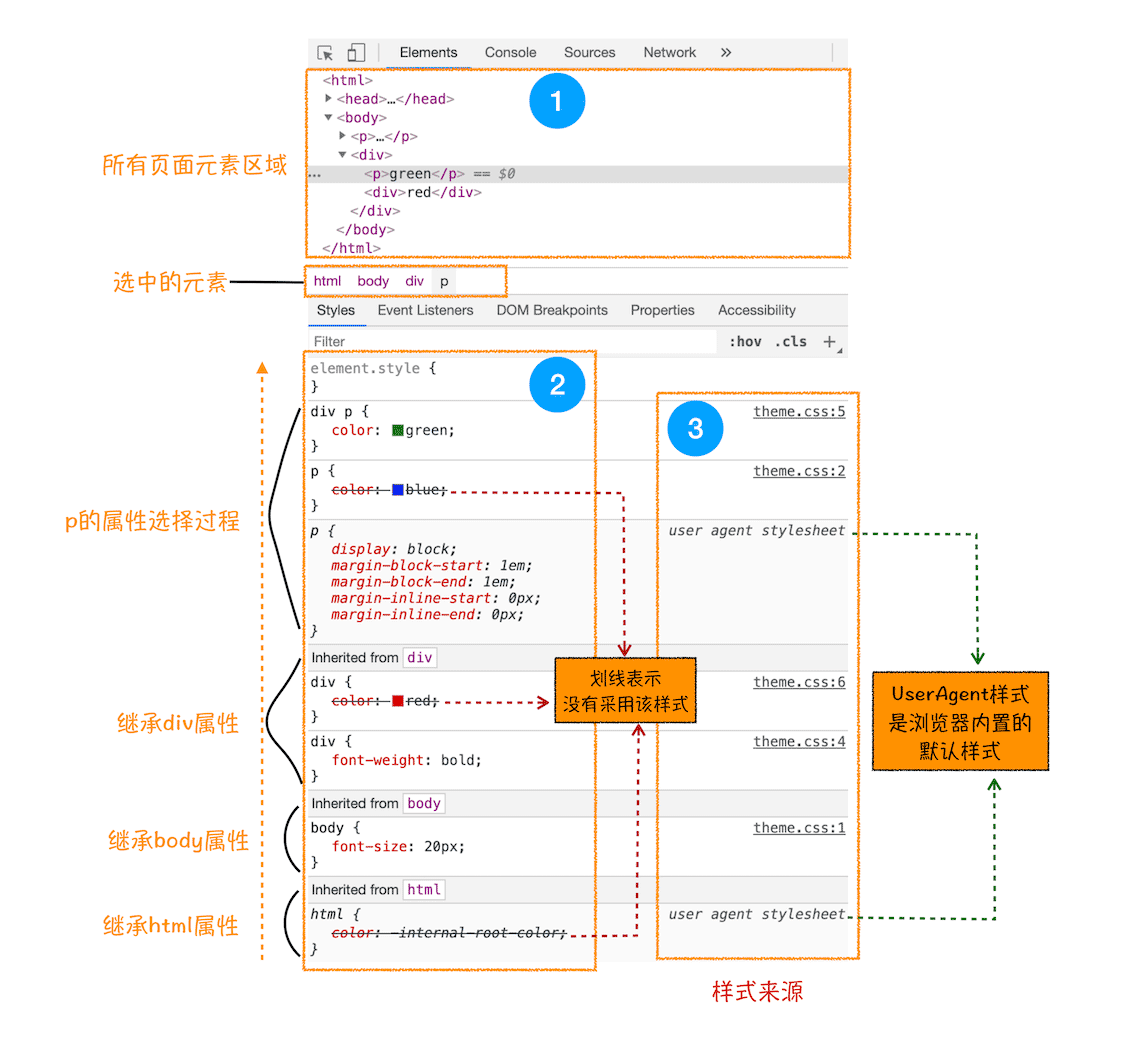
样式的继承过程界面
以上就是 CSS 继承的一些特性,样式计算过程中,会根据 DOM 节点的继承关系来合理计算节点样式。
样式计算过程中的第二个规则是样式层叠。层叠是 CSS 的一个基本特征,它是一个定义了如何合并来自多个源的属性值的算法。它在 CSS 处于核心地位,CSS 的全称“层叠样式表”正是强调了这一点。关于层叠的具体规则这里就不做过多介绍了,网上资料也非常多,你可以自行搜索学习。
总之,样式计算阶段的目的是为了计算出 DOM 节点中每个元素的具体样式,在计算过程中需要遵守 CSS 的继承和层叠两个规则。这个阶段最终输出的内容是每个 DOM 节点的样式,并被保存在 ComputedStyle 的结构内。
如果你想了解每个 DOM 元素最终的计算样式,可以打开 Chrome 的“开发者工具”,选择第一个“element”标签,然后再选择“Computed”子标签,如下图所示:
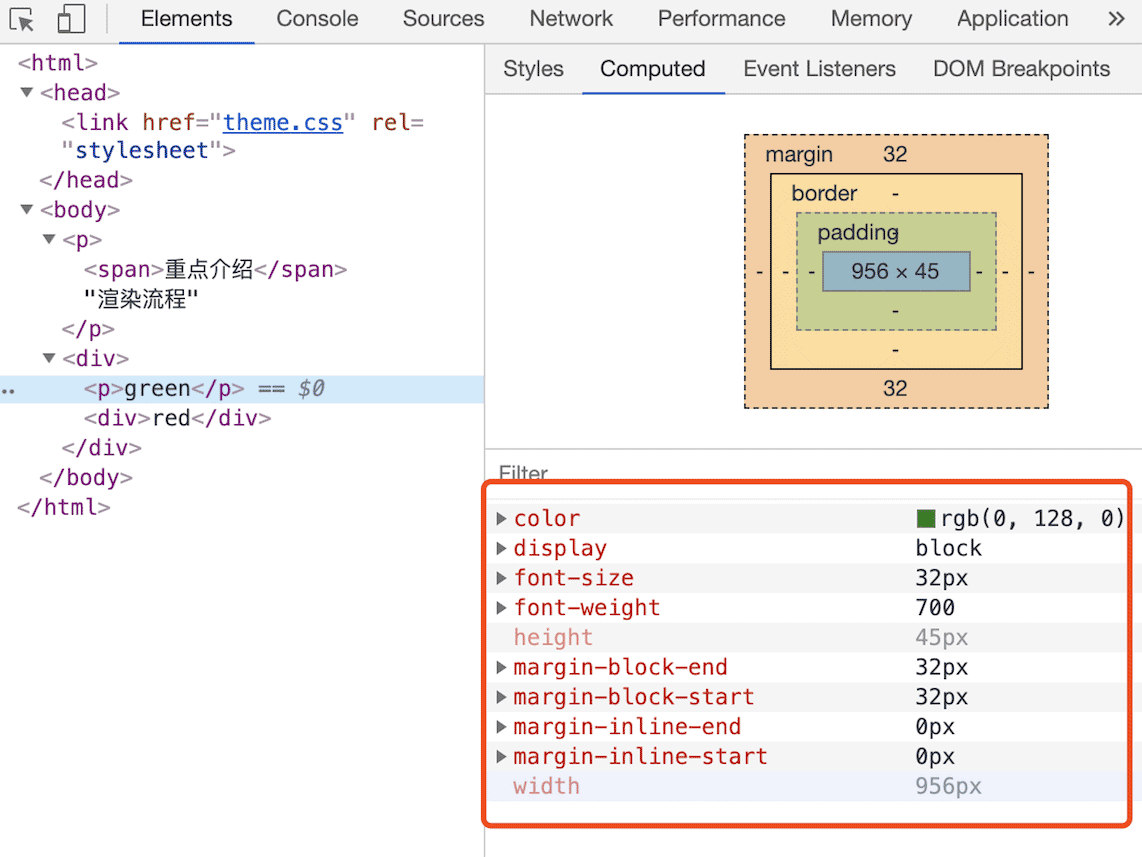
DOM 元素最终计算的样式
上图红色方框中显示了 html.body.div.p 标签的 ComputedStyle 的值。你想要查看哪个元素,点击左边对应的标签就可以了。
布局阶段
现在,我们有 DOM 树和 DOM 树中元素的样式,但这还不足以显示页面,因为我们还不知道 DOM 元素的几何位置信息。那么接下来就需要计算出 DOM 树中可见元素的几何位置,我们把这个计算过程叫做布局。
Chrome 在布局阶段需要完成两个任务:创建布局树和布局计算。
创建布局树:你可能注意到了 DOM 树还含有很多不可见的元素,比如 head 标签,还有使用了 display:none 属性的元素。所以在显示之前,我们还要额外地构建一棵只包含可见元素布局树。
我们结合下图来看看布局树的构造过程:
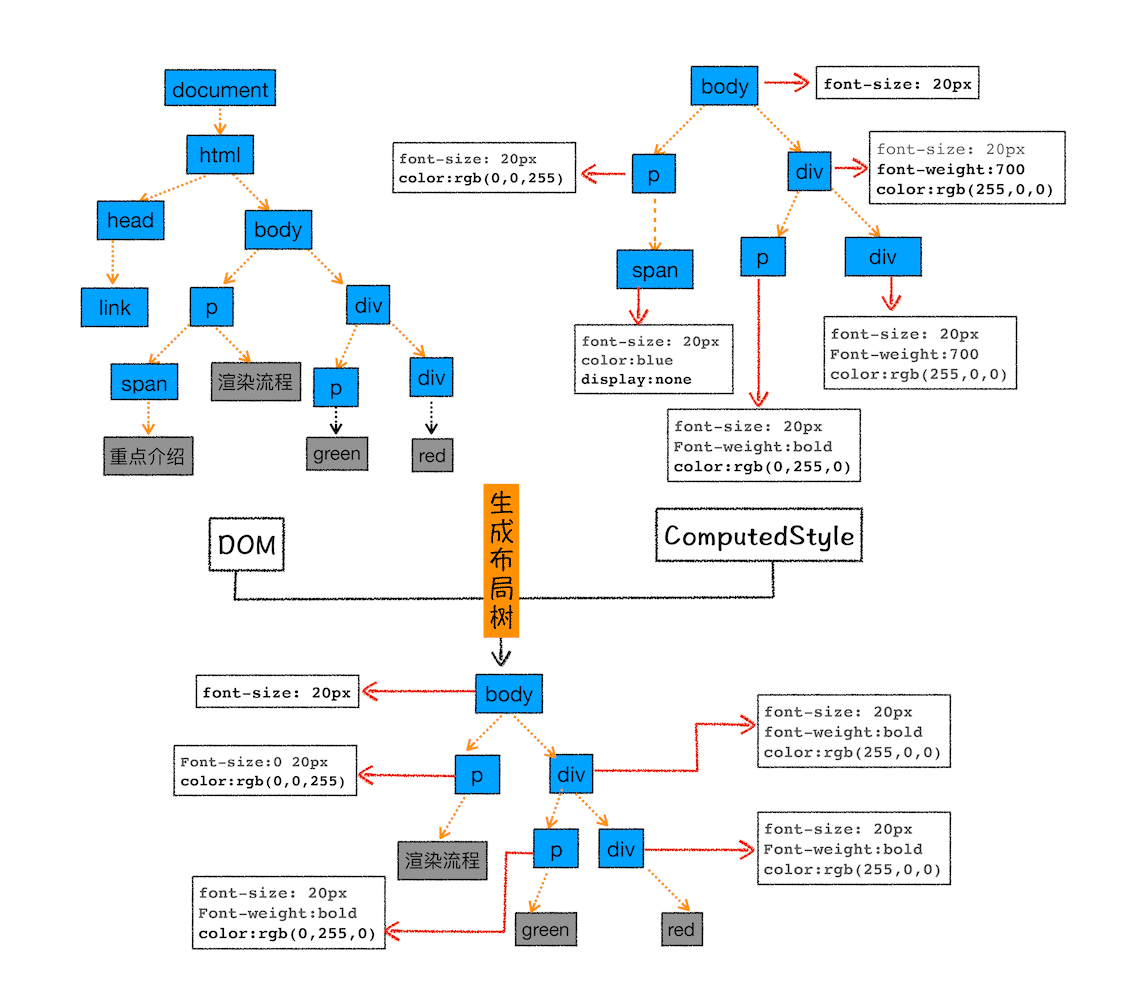
布局树构造过程示意图
从上图可以看出,DOM 树中所有不可见的节点都没有包含到布局树中。
为了构建布局树,浏览器大体上完成了下面这些工作:
- 遍历 DOM 树中的所有可见节点,并把这些节点加到布局中;
- 而不可见的节点会被布局树忽略掉,如 head 标签下面的全部内容,再比如 body.p.span 这个元素,因为它的属性包含 dispaly:none,所以这个元素也没有被包进布局树。
2.布局计算:现在我们有了一棵完整的布局树。那么接下来,就要计算布局树节点的坐标位置了。布局的计算过程非常复杂,我们这里先跳过不讲,等到后面章节中我再做详细的介绍。
在执行布局操作的时候,会把布局运算的结果重新写回布局树中,所以布局树既是输入内容也是输出内容,这是布局阶段一个不合理的地方,因为在布局阶段并没有清晰地将输入内容和输出内容区分开来。针对这个问题,Chrome 团队正在重构布局代码,下一代布局系统叫 LayoutNG,试图更清晰地分离输入和输出,从而让新设计的布局算法更加简单。
渲染流水线图
分层
现在我们有了布局树,而且每个元素的具体位置信息都计算出来了,那么接下来是不是就要开始着手绘制页面了?
答案依然是否定的。
因为页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)。如果你熟悉 PS,相信你会很容易理解图层的概念,正是这些图层叠加在一起构成了最终的页面图像。
现在你知道了浏览器的页面实际上被分成了很多图层,这些图层叠加后合成了最终的页面。下面我们再来看看这些图层和布局树节点之间的关系,如文中图所示:
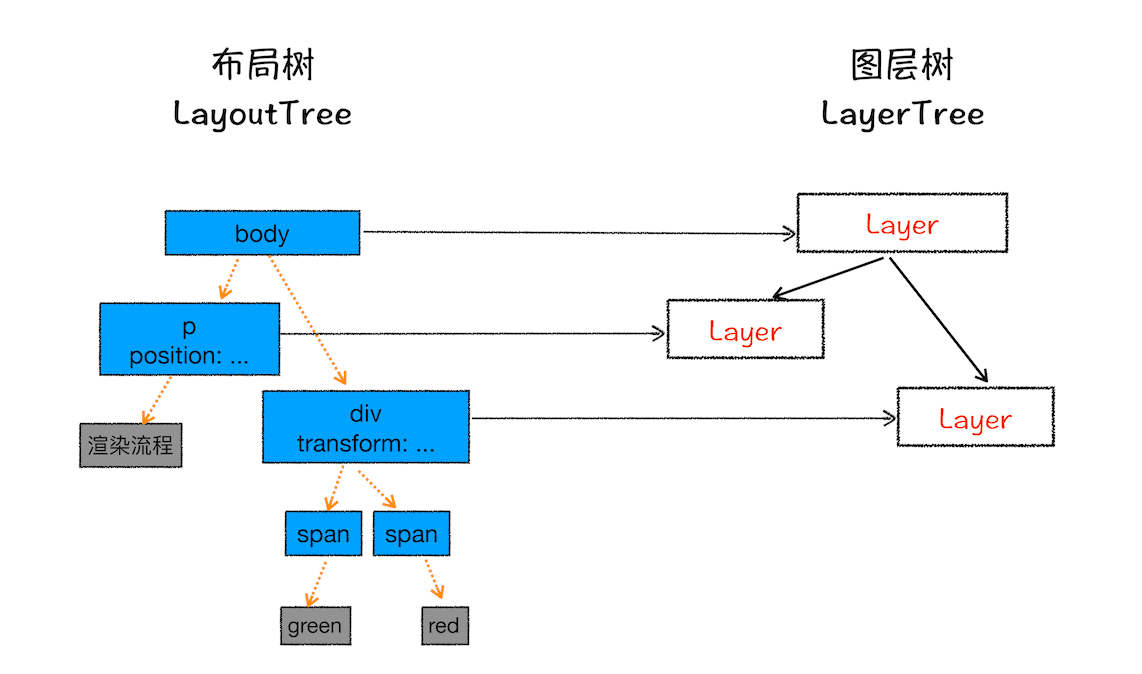
布局树和图层树关系示意图
通常情况下,并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。如上图中的 span 标签没有专属图层,那么它们就从属于它们的父节点图层。但不管怎样,最终每一个节点都会直接或者间接地从属于一个层。
那么需要满足什么条件,渲染引擎才会为特定的节点创建新的层呢?通常满足下面两点中任意一点的元素就可以被提升为单独的一个图层。
1.拥有层叠上下文属性的元素会被提升为单独的一层:页面是个二维平面,但是层叠上下文能够让 HTML 元素具有三维概念,这些 HTML 元素按照自身属性的优先级分布在垂直于这个二维平面的 z 轴上。你可以结合下图来直观感受下:
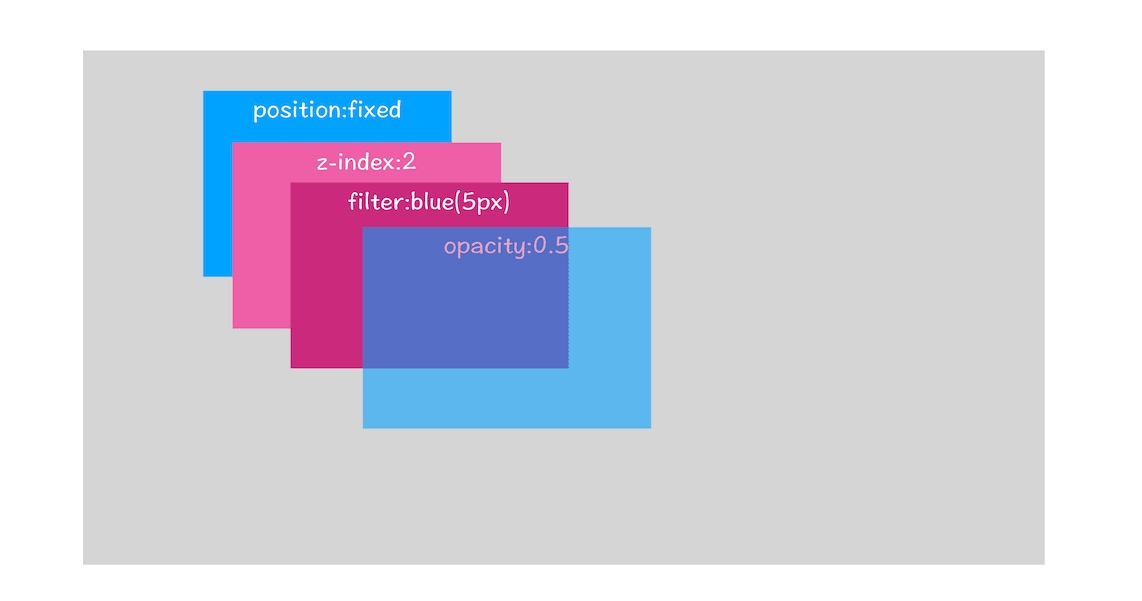
层叠上下文示意图
从图中可以看出,明确定位属性的元素、定义透明属性的元素、使用 CSS 滤镜的元素等,都拥有层叠上下文属性。
2.需要剪裁(clip)的地方也会被创建为图层:不过首先你需要了解什么是剪裁,结合下面的 HTML 代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<style>
div {
width: 200;
height: 200;
overflow:auto;
background: gray;
}
</style>
<body>
<div >
<p> 所以元素有了层叠上下文的属性或者需要被剪裁,那么就会被提升成为单独一层,你可以参看下图:</p>
<p> 从上图我们可以看到,document 层上有 A 和 B 层,而 B 层之上又有两个图层。这些图层组织在一起也是一颗树状结构。</p>
<p> 图层树是基于布局树来创建的,为了找出哪些元素需要在哪些层中,渲染引擎会遍历布局树来创建层树(Update LayerTree)。</p>
</div>
</body>在这里我们把 div 的大小限定为 200 200 像素,而 div 里面的文字内容比较多,文字所显示的区域肯定会超出 200 200 的面积,这时候就产生了剪裁,渲染引擎会把裁剪文字内容的一部分用于显示在 div 区域,下图是运行时的执行结果:

剪裁执行结果
出现这种裁剪情况的时候,渲染引擎会为文字部分单独创建一个层,如果出现滚动条,滚动条也会被提升为单独的层。你可以参考下图:
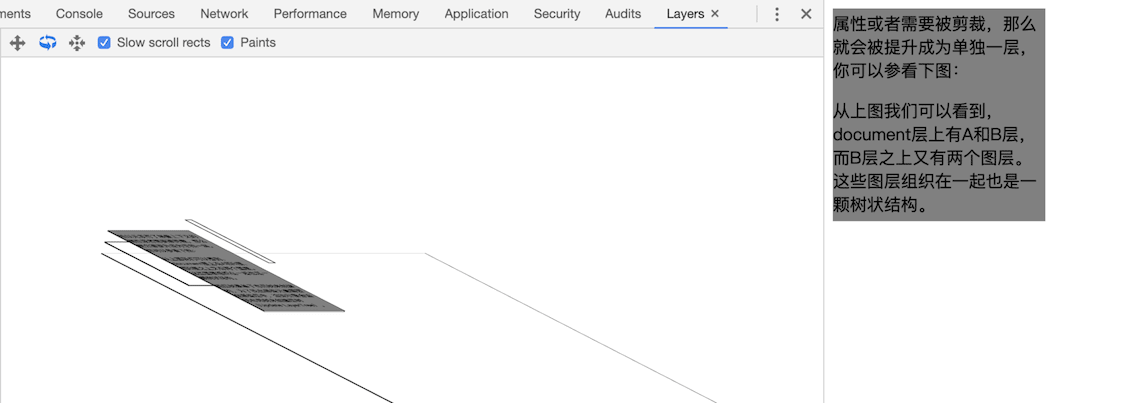
被裁剪的内容会出现在单独一层
所以说,元素有了层叠上下文的属性或者需要被剪裁,满足这任意一点,就会被提升成为单独一层。
图层绘制
在完成图层树的构建之后,渲染引擎会对图层树中的每个图层进行绘制,那么接下来我们看看渲染引擎是怎么实现图层绘制的?
试想一下,如果给你一张纸,让你先把纸的背景涂成蓝色,然后在中间位置画一个红色的圆,最后再在圆上画个绿色三角形。你会怎么操作呢?
通常,你会把你的绘制操作分解为三步:
- 绘制蓝色背景;
- 在中间绘制一个红色的圆;
- 再在圆上绘制绿色三角形。
渲染引擎实现图层的绘制与之类似,会把一个图层的绘制拆分成很多小的绘制指令,然后再把这些指令按照顺序组成一个待绘制列表,如下图所示:

绘制列表
从图中可以看出,绘制列表中的指令其实非常简单,就是让其执行一个简单的绘制操作,比如绘制粉色矩形或者黑色的线等。而绘制一个元素通常需要好几条绘制指令,因为每个元素的背景、前景、边框都需要单独的指令去绘制。所以在图层绘制阶段,输出的内容就是这些待绘制列表。
栅格化(raster)操作
绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际上绘制操作是由渲染引擎中的合成线程来完成的。你可以结合下图来看下渲染主线程和合成线程之间的关系:
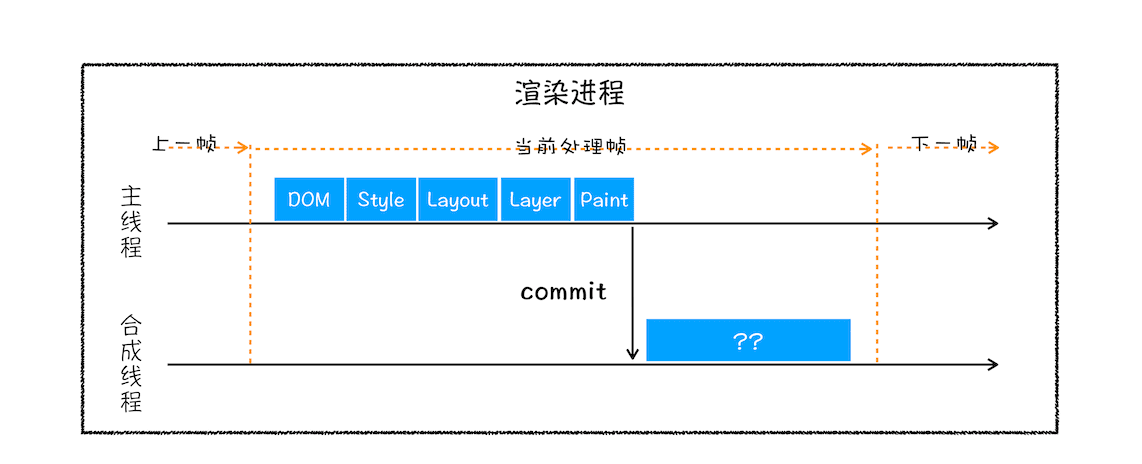
渲染进程中的合成线程和主线程
如上图所示,当图层的绘制列表准备好之后,主线程会把该绘制列表提交(commit)给合成线程,那么接下来合成线程是怎么工作的呢?
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。
在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
基于这个原因,合成线程会将图层划分为图块(tile),这些图块的大小通常是 256x256 或者 512x512
然后合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。而图块是栅格化执行的最小单位。渲染进程维护了一个栅格化的线程池,所有的图块栅格化都是在线程池内执行的,运行方式如下图所示:
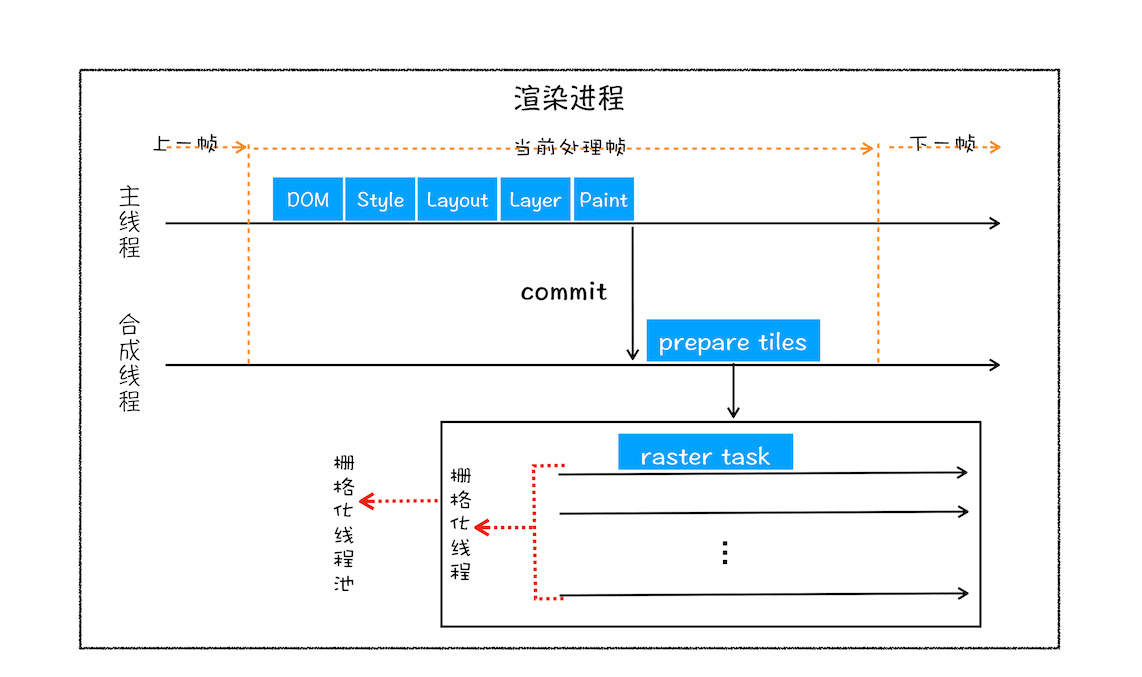
合成线程提交图块给栅格化线程池
通常,栅格化过程都会使用 GPU 来加速生成,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中。
相信你还记得,GPU 操作是运行在 GPU 进程中,如果栅格化操作使用了 GPU,那么最终生成位图的操作是在 GPU 中完成的,这就涉及到了跨进程操作。具体形式你可以参考下图:
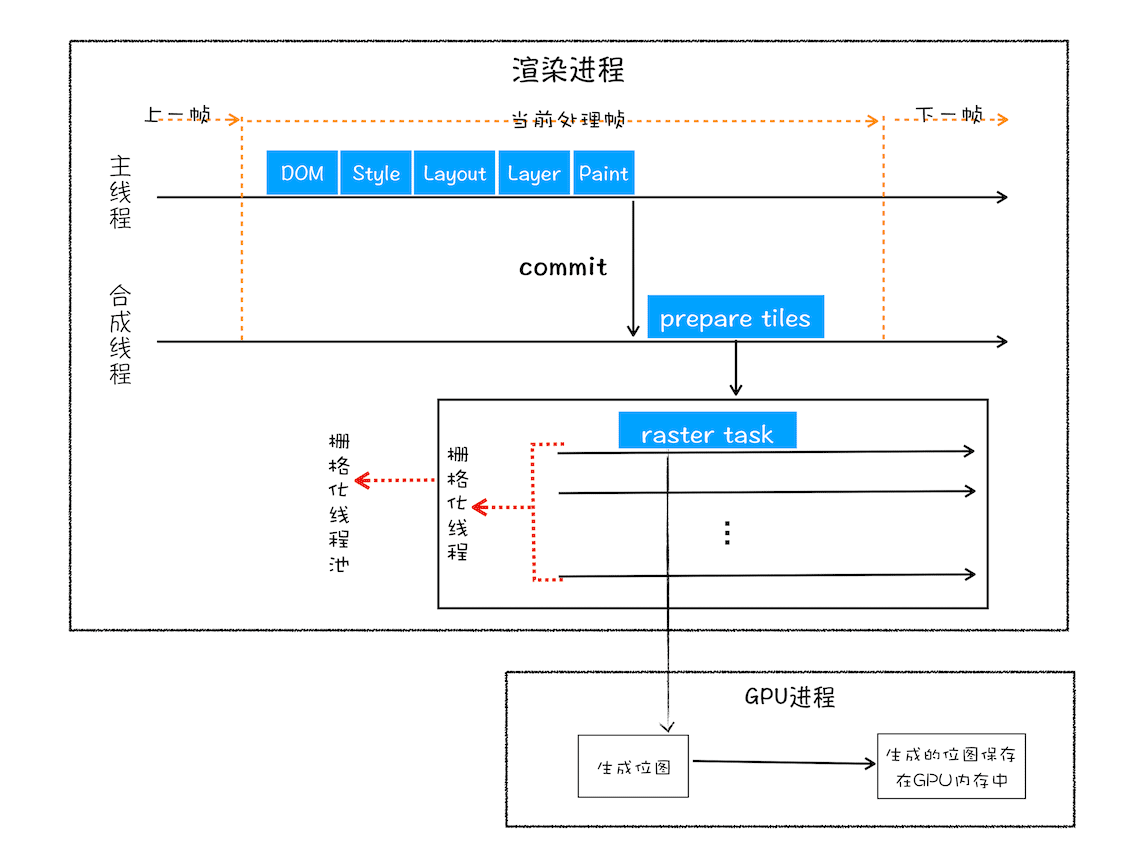
GPU 栅格化
从图中可以看出,渲染进程把生成图块的指令发送给 GPU,然后在 GPU 中执行生成图块的位图,并保存在 GPU 的内存中。
合成和显示
一旦所有图块都被光栅化,合成线程就会生成一个绘制图块的命令——“DrawQuad”,然后将该命令提交给浏览器进程。
浏览器进程里面有一个叫 viz 的组件,用来接收合成线程发过来的 DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在屏幕上。
到这里,经过这一系列的阶段,编写好的 HTML、CSS、JavaScript 等文件,经过浏览器就会显示出漂亮的页面了。
渲染流水线大总结
好了,我们现在已经分析完了整个渲染流程,从 HTML 到 DOM、样式计算、布局、图层、绘制、光栅化、合成和显示。下面我用一张图来总结下这整个渲染流程:
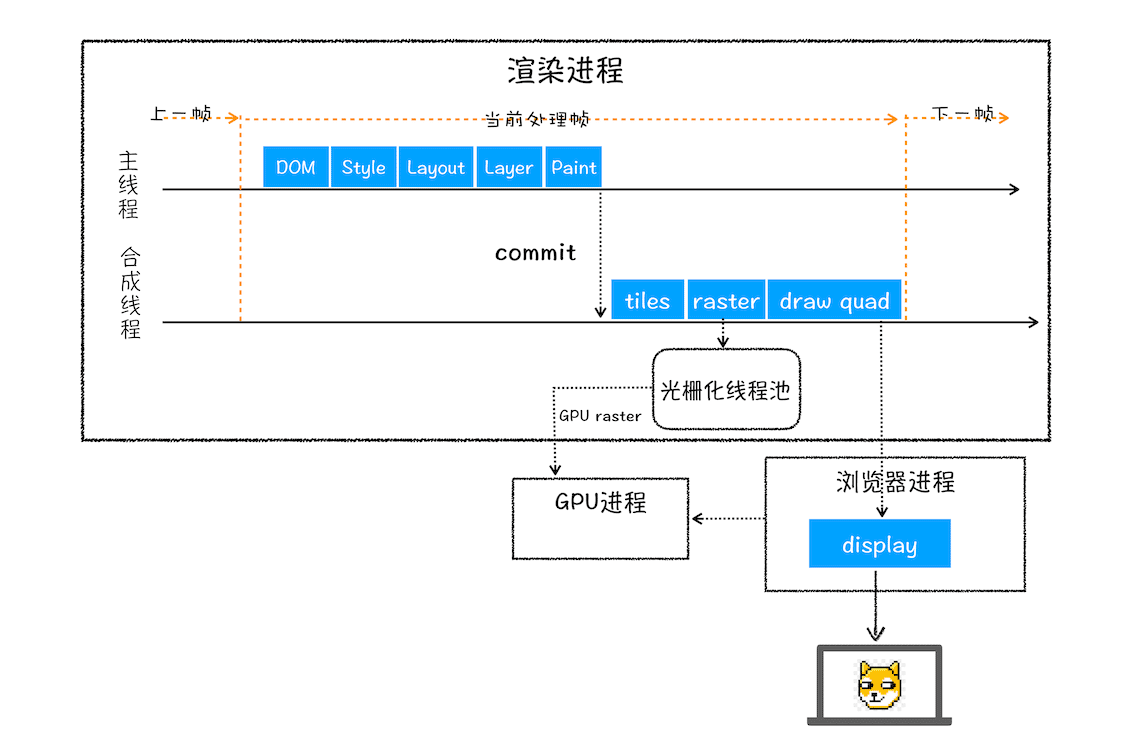
完整的渲染流水线示意图
结合上图,一个完整的渲染流程大致可总结为如下:
- 渲染进程将 HTML 内容转换为能够读懂的DOM 树结构。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的styleSheets,计算出 DOM 节点的样式。
- 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。
- 合成线程将图层分成图块,并在光栅化线程池中将图块转换成位图。
- 合成线程发送绘制图块命令DrawQuad给浏览器进程。
- 浏览器进程根据 DrawQuad 消息生成页面,并显示到显示器上。
相关概念
有了上面介绍渲染流水线的基础,我们再来看看三个和渲染流水线相关的概念——“重排”“重绘”和“合成”。理解了这三个概念对于你后续 Web 的性能优化会有很大帮助。
更新了元素的几何属性(重排)
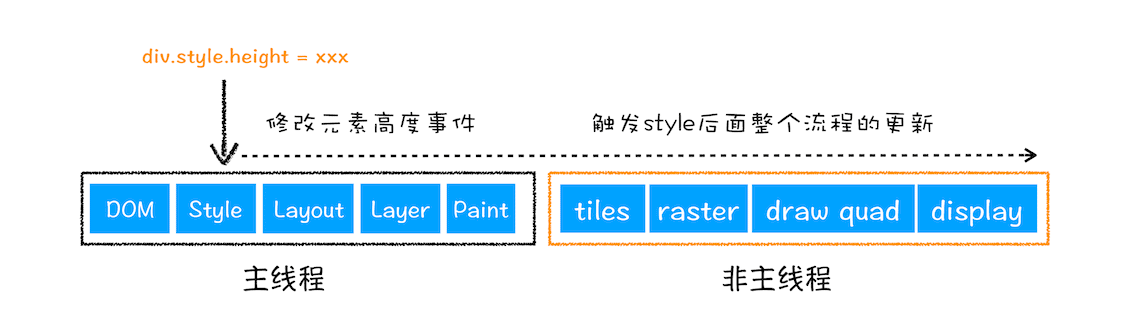
更新元素的几何属性
从上图可以看出,如果你通过 JavaScript 或者 CSS 修改元素的几何位置属性,例如改变元素的宽度、高度等,那么浏览器会触发重新布局,解析之后的一系列子阶段,这个过程就叫重排。无疑,重排需要更新完整的渲染流水线,所以开销也是最大的。
更新元素的绘制属性(重绘)
接下来,我们再来看看重绘,比如通过 JavaScript 更改某些元素的背景颜色,渲染流水线会怎样调整呢?你可以参考下图:
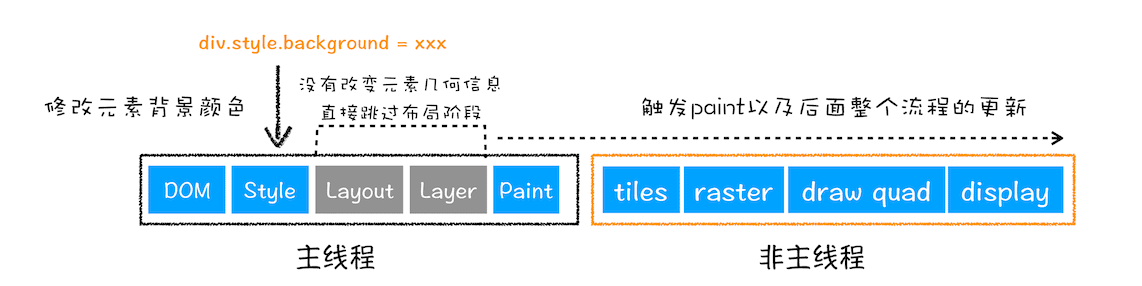
更新元素背景
从图中可以看出,如果修改了元素的背景颜色,那么布局阶段将不会被执行,因为并没有引起几何位置的变换,所以就直接进入了绘制阶段,然后执行之后的一系列子阶段,这个过程就叫重绘。相较于重排操作,重绘省去了布局和分层阶段,所以执行效率会比重排操作要高一些。
直接合成阶段
那如果你更改一个既不要布局也不要绘制的属性,会发生什么变化呢?渲染引擎将跳过布局和绘制,只执行后续的合成操作,我们把这个过程叫做合成。具体流程参考下图:
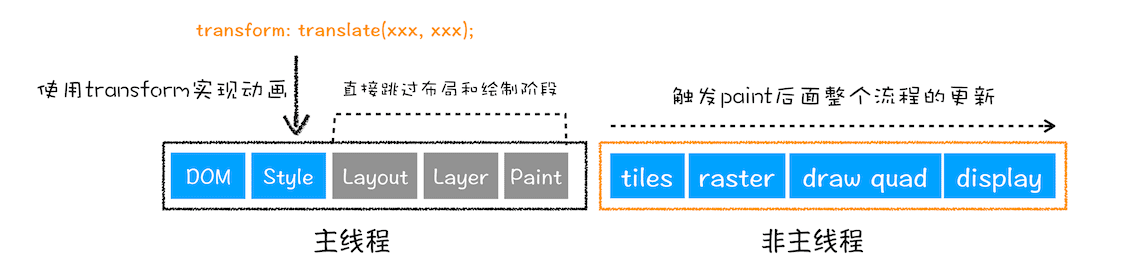
避开重排和重绘
在上图中,我们使用了 CSS 的 transform 来实现动画效果,这可以避开重排和重绘阶段,直接在非主线程上执行合成动画操作。这样的效率是最高的,因为是在非主线程上合成,并没有占用主线程的资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率。
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com