Skills 技术深度解析:AI Agent 能力扩展的新范式
Jan 18, 2026笔记aiSkills 技术深度解析:AI Agent 能力扩展的新范式
Skills 是可重用的、基于文件系统的资源,为 Claude/OpenAI 等 Agent 工具提供领域专业知识——工作流、上下文和最佳实践,将通用 Agent 转变为专家。
简洁版
Skills 技术兴起于 2025 年下半年。Anthropic Claude 率先推出,OpenAI Codex/ChatGPT 紧随其后,社区开源项目也迅速响应。这背后反映出业界在探索让模型高效调用外部知识与工具上的共识和热情。而开放标准的发布,则为 Skills 在更广泛的生态中传播奠定了基础。
Skills 的提出针对模型使用过程中的三个关键问题:如何低成本地赋予模型新能力,如何让模型在复杂任务上保持可靠、可控,以及如何突破上下文限制高效利用知识。Skills 通过将知识/工具封装成模块,使模型调用变得按需、精准和可管理,从而实现了以上目标
Skills/MCP/Function Call 三种机制本质上都在回答同一个问题——“如何让大模型正确地调用外部工具/知识?”。区别在于:MCP 制定了全面协议,函数调用提供了精确定义的钩子,Skills 则赋予模型自主“技艺”。对于开发者来说,Skills 降低了扩展模型的心智负担,只需提供知识而非操作细节;但在需要绝对精确控制时,函数调用或 MCP 依然不可或缺。因此,在构建复杂 AI 系统时,我们应根据任务需求,将这些机制灵活组合,以实现最佳效果。
编写高质量 Skill 既是一门提示工程,也是一门软件工程。既要懂模型的“小聪明”,也要防范它的“小毛病”。只有反复打磨,我们才能打造出既聪明又可靠的技能模块,让模型在各种复杂任务中游刃有余。
一、Skills 的发展背景和时间线
2025 年 10 月 16 日 Anthropic 正式推出 Claude Skills 能力,宣布 Claude 可以使用“技能”来提升特定任务的表现:“Claude can now use Skills to improve how it performs specific tasks. Skills are folders that include instructions, scripts, and resources that Claude can load when needed.”。换言之,开发者可以把某类任务的指导文档、示例代码等打包成一个 Skill,Claude 会在需要时动态加载,从而更好地完成专门任务(如处理 Excel 表格、遵循品牌文档格式等)。
Anthropic 官方工程博客 的定义:随着模型能力的提升,我们现在可以构建与完整计算环境交互的通用 Agent。但随着这些 Agent 变得更强大,我们需要更可组合、可扩展、可移植的方式来为它们配备领域专业知识。这促使 Anthropic 创建了 Skills:有组织的指令、脚本和资源文件夹,Agent 可以动态发现和加载它们,以更好地执行特定任务。
OpenAI Codex 随即跟进支持 Skills:在 Anthropic 的 Skills 概念发布后不久,OpenAI 也悄然开始在其开发者工具中采用类似机制。2025 年 12 月,OpenAI 的 Codex CLI 工具加入了实验性的 Skills 支持,并且 ChatGPT 的 Code Interpreter(即 GPT-4.5+/GPT-5 系列的代码执行模式)也出现了内置的 /home/oai/skills 目录。Simon Willison 实测分析显示,当时 ChatGPT 已含有用于处理表格、Docx 文档和 PDF 的技能包,并且模型会在需要时自动读取这些 Skill 文件(例如在生成 PDF 时,会先输出“Reading skill.md for PDF creation guidelines”再按其中指导执行)。这说明 OpenAI 已将 Skills 概念集成到其模型工具链中,与 Anthropic 保持同步发展。
开放标准和其他实现:为促进跨平台复用,Anthropic 在 2025 年 12 月 18 日将 Skills 规范开源,发布了Agent Skills Standard
这使得 Skills 的定义和用法成为开放标准,其他平台很快跟进。例如,开源的 AI 编程助手 OpenCode 参考该标准实现了 Skills 支持。OpenCode 是一个类似 Claude Code/Codex CLI 的本地代理工具,虽然在最初并不具备原生 Skills,但社区通过插件迅速补充了这一功能,并在稍后版本中原生集成了 Skills 系统。
OpenCode 的官方文档指出,其 Agent Skills 机制与 Anthropic 定义兼容:在特定目录下放置 Skill 文件,OpenCode 会在启动时扫描可用技能,并允许模型按需加载。
随着 Skills 标准的推出,我们看到 Skills 正快速成为业内通用机制,“任何具有文件系统访问能力的 LLM 工具都可以支持 Skills”。甚至有开发者指出,你完全可以将 Anthropic 的技能包用于 OpenAI Codex 或 Google Gemini,只需让模型读取相应的 Skill 文件即可。
二、Skills 要解决的问题及核心价值
引入 Skills,究竟是为了解决哪些痛点?其核心价值体现在以下几个方面:
减少重复 prompt,扩展模型能力:传统上,为让模型执行特定复杂任务,往往需要在每次对话中提供详细说明或示例(prompt engineering),这既费时又占用大量上下文窗口。Skills 提供了一种“一次编写,多次使用”的方案——把专业领域的知识和操作流程编写成 Skill 文件,模型在需要时自行加载。这避免了反复粘贴同样提示的繁琐,提升了效率和一致性(社区有人形容 “AI Agent Skills Automation kills that cycle. It turns prompts into persistent knowledge.”)。对于企业或个人来说,这意味着可以沉淀自己的领域经验为技能模块,供模型随时调用,从而低成本地扩展模型能力
提升复杂任务的可靠性:大型模型虽然强大,但在执行涉及多步骤、工具使用或严格格式要求的任务时,常出现不稳定或偏差。Skills 针对这种情况引入专门的指导和脚本,以提高准确性。例如,Anthropic 官方提到,Claude 本身能理解 PDF 内容,但无法直接操作 PDF 表单,而引入 PDF Skill 后,就能通过附带的代码来读取和填写表单。又比如 Slack GIF Skill 内置了检查 GIF 文件大小的函数,Claude 在生成动图后会调用此验证函数,若超出 Slack 限制则自动调整重试。“某些操作用传统代码更可靠,而 Skills 允许将这类代码融入模型工作流”。因此,Skills 结合了 LLM 的智能和代码的确定性:模型负责决策和生成,遇到精细计算或格式校验时,可以执行预先编写的脚本,保证结果符合要求。
工具接口抽象与安全隔离:Skills 也是一种工具接口抽象。类似于 OpenAI 的函数调用把函数描述暴露给模型,Skills 则把更高层次的工作流程封装起来。例如,通过 Skill,可以向模型描述如何使用内部的多个工具完成一项任务(如“查询数据库然后绘制图表”这样的复合流程),而不必每次对模型重复解释各步骤。这带来了更好的可维护性和可控性:Skill 文件相当于文档化、模块化的提示,易于版本管理和审核。Anthropic 提到,这种结构化提示提升了可预测性和审计性,在企业和安全场景下尤为重要。另外,Skills 运行所需的外部代码通常在受控的沙盒环境中(如 Claude Code 或 ChatGPT Code Interpreter 的隔离容器),在提供扩展能力的同时降低安全风险。开发者可以预先审计 Skill 附带的脚本,从而避免模型直接运行互联网上的不明代码,增加了整体的安全性和可信度。
节省上下文,按需加载知识:“渐进披露”(Progressive Disclosure)是 Skills 设计的一大原则。每个 Skill 包含丰富的信息,但模型一开始只会看到其中精简的元数据(名称和描述),只有判断出技能相关时才进一步加载详细内容。这样做的好处是节省上下文长度。Anthropic 工程团队形象地将其比作一本组织良好的手册:目录告诉你章节内容,真正需要时再去读对应章节。因此,借助 Skills,模型能够带着“隐藏的长篇提示”工作——相关时才打开,不相关时不挤占内存。正如开发者所评价的那样:“Because the notification is only name + description + file, this is cheap r.e. tokens… Skills are Markdown with a tiny bit of YAML… throw in some text and let the model figure it out.”。这极大提高了扩展模型知识的性价比:相比一直在系统提示中堆满各种可能用到的说明,Skills 让上下文利用更加高效。
三、Skills 与 MCP、Function Calling 等机制的区别与联系
在工具使用方面,当前存在多种不同机制,常见的有 Anthropic 推动的 MCP(Model Context Protocol,多组件提示/多调用协议) 和 OpenAI API 中的 函数调用(Function Calling,也称 Tool Call)。那么 Skills 与这些机制有何区别?是否功能重叠,能否互补?我们分别来看:
- 与 MCP 的对比:MCP 将多步提示交互形式化为客户端-服务端协议。MCP 把 LLM 代理解耦成主机(Host)、工具服务器等角色,并通过 JSON-RPC 等通信让模型按照预定义步骤调用工具。其优点是严格规范了每一步的格式和顺序,适合复杂场景下的可追踪执行。然而这种规范也带来了实现和集成上的复杂度。正如开发者所评论的:“MCP is a whole protocol spec covering hosts, clients, servers, prompts, tools… and multiple transports (HTTP, SSE…). Skills are Markdown with a bit of YAML… They feel closer to the spirit of LLMs — just throw in some text and let the model figure it out.”。简单来说,MCP 更像一个工业级标准,强调完备和通用,Skills 则更轻量灵活,遵循“预先将说明放在文件里,模型用到时自己看”的思路。举例来说,配置一个 MCP 工具需要实现服务器端、定义请求/响应模式,而编写一个 Skill 只需写 Markdown 文档和必要脚本。开发速度和门槛上,Skills 显然更低,这也是为什么有人将 Skills 形容为对 MCP 的一种更实用的补充或替代。
值得注意的是,两者并非相互排斥。Anthropic 的团队就表示,将来会探索 Skills 与 MCP 的集成,例如通过 Skills 教会代理如何执行更复杂的、多工具组合的工作流,而底层的实际 API 调用仍由 MCP 服务器完成。换言之,Skills 可以封装调用 MCP 工具的策略和流程,MCP 则负责具体执行业务。二者结合,模型既知道“做什么”,也能通过标准协议“去做”。因此,我们可以将 Skills 看作更上层的抽象:MCP 解决模型和工具之间接口问题,Skills 则侧重知识和流程的封装。正如有评论指出的:“工具本身当然重要,但除了执行命令,很多机制只是为了帮你构建提示上下文… Skills 就是直接把现成的指令或文档拉入上下文的便利方式”。从这个意义上说,Skills 与 MCP 目标一致(让 AI 能利用外部能力),路径有别:一个偏重协议工程,一个偏重内容工程。
- 与函数调用(Tool Call)的对比:OpenAI 的函数调用机制是在模型推理结果中输出特殊格式(JSON)来请求调用某个函数。开发者需提前定义可调用函数的名字、参数 schema 和描述,模型则学会在回答中产生日志,指明何时以什么参数调用函数。函数调用的优势在于严格的结构化:模型只要决定调用,开发者就能精确获取所需参数并执行,从而完成诸如查天气、查数据库等操作。它类似于 RPC,强调一次调用一项功能。
Skills 则有所不同:它更像是“引入一段新能力”而不是单一函数。Skill 没有固定的输入/输出接口,而是一系列关于如何完成任务的说明,可能包含多个步骤、调用多个工具甚至执行代码。模型加载一个 Skill 后,在随后的对话中按照 Skill 的指导自行决策下一步。举个例子,假设有“报表生成”的 Skill,里面写了:“当用户需要生成报表时,先用 SQL 查询数据库,然后用 Matplotlib 绘图,最后写 PDF 输出。” 模型一旦加载该 Skill,就会明白整个流程,中间可能通过函数调用或代码执行来实现每一步。但这些细节不需要开发者每次提示,模型依据 Skill 文档自行展开。这表明 Skills 提供的是一种更高层次的“玩法”,而函数调用提供的是具体的“招式”。
从实现依赖来看,函数调用不要求模型有代码执行环境,它是由外部应用来实际运行函数;而 Skills 的威力往往在于模型具备执行环境(如 Claude Code 的沙箱、ChatGPT Code Interpreter 容器)。有了执行环境,模型甚至能修改或创建新代码文件来完成 Skill 指定的任务。这一点让 Skills 能够做“过程控制”(procedural tasks),而函数调用主要做“过程触发”(trigger a function)。当然,如果没有执行环境,某些 Skill 也可仅作为说明文档,指导模型输出结果(类似 Chain-of-Thought 提示);但完整发挥时,环境是重要前提。因此,有观点认为:Skills 的出现部分得益于“模型+沙盒”模式的发展,是 Code Interpreter 思路的延伸。
- 互补与重叠:总体而言,Skills、MCP、函数调用都是让 LLM 超越纯文本对话、更深入融入软件系统的途径,它们着眼点不同但目标一致。在实际应用中,这些机制可以组合使用,取长补短。例如,一个复杂的 AI 助手可以使用 Skills 提供高层策略,用函数调用来获取精确数据,再通过 MCP 服务器访问远程服务。Anthropic 官方也认为 Skills 能补充 MCP,以教授代理更复杂的工具使用方法。反过来,对于 Skill 未涵盖的低级操作,函数调用仍然是直接有效的手段。有人曾指出,其实巧妙利用函数调用也能实现类似 Skills 的效果,比如将 Skill frontmatter 的信息对应定义成一个函数,然后让模型决定调用(虽然后者不具备 Skill 的渐进加载优势)。总的来说,Skills 更强调通用智能+工具执行环境的结合,而 MCP/函数调用更强调明确的工具接口契约。随着开放标准的推进,这些路线或许会趋于融合——比如未来的统一代理可能同时支持 Agent Skills 文件和函数式 API,让模型在自由推理与结构化调用间无缝切换。
四、Skills 的定义与实现方式
理解了理念,我们再来看 Skills 的具体形态和实现细节。总体来说,每个 Skill 就是一个以特定格式编写的文件夹,里面包含了让模型掌握一项新技能所需的一切。常见结构如下:
- 核心文件
SKILL.md:必不可少的技能定义文件,采用 Markdown 编写。文件开头包含 YAML 格式的元数据区(Frontmatter),之后是面向模型的详细说明内容。
- 可选的脚本和资源:Skill 文件夹内可以有 scripts/ 子目录存放可执行脚本(如 .py、.js),有 references/ 存放参考资料(比如长文档拆分出的附加说明),以及 assets/ 存放模板或素材等。这些额外文件可以在 SKILL.md 的正文中通过引用链接,指导模型在需要时加载或运行。

下面是一段 Skill 元数据区 的示例(取自 OpenCode 对 Agent Skills 的定义),展示了常见字段:
1 | --- |
在上述 YAML Frontmatter 中,name 和 description 是最基本的必填项。Name 通常是简短易记的标识(限制长度,一般不超过 64 字符,全部小写字母加可选短横线),Description 则是一两句话描述技能的功能和何时该用它。这一描述非常关键——模型会依赖它决定是否调用该 Skill。其他字段如 license、compatibility、metadata 等提供附加信息,允许作者注明技能的版权、适用范围,或自定义一些键值对标签以供管理。
元数据区结束后,就是 Skill 的正文内容。在正文中,作者可以用 Markdown 格式详细编写模型执行该任务所需的一切信息。常见内容包括:
- 用途和功能:说明这个 Skill 能做什么(例如分点描述功能清单)。
- 使用场景:明确指出模型在什么情况下应当启用该技能,比如触发词或情境。
- 执行步骤:给出解决任务的推荐步骤或策略,有时以带编号的清单形式呈现。模型会将其内化为一种流程。
- 示例或模板:如有必要,可包含示例输入输出、格式模板,让模型参考。
- 附带工具使用:如果该技能涉及模型调用已有工具(如模型自带的读写文件、运行代码等操作),可以写明调用方式和注意事项。例如 Claude Code 环境下常用的
<bash>、<python>等工具指令。Anthropic 建议在 Claude 中使用特定格式(如 XML 标签)来提示模型严格遵循指令,这在 Skill 中也可体现。 - 错误处理:指导模型遇到问题时怎么做,比如如果脚本抛出异常,是否尝试再次执行或输出提示。
值得一提的是,Skill 本身并没有固定的参数接口。与 OpenAI 函数调用要求开发者定义 JSON 参数 schema 不同,Skill 更偏向自然语言层面的协议。模型根据用户请求上下文决定是否使用某技能,一旦决定,则自行按照技能说明开展工作,过程中如果需要用户提供额外信息,会再询问用户。这种机制虽然不如函数调用那样显式,但更灵活:很多情况下,用户的问题本身就已经提供了技能所需的信息,无需额外的参数传递。例如“请生成符合我公司品牌指南的 PPT 模板”——Claude 可以识别出需要 Brand Guidelines Skill,加载后直接按照 Skill 内容(颜色、字体等)执行,而不需要像函数调用那样将品牌名称作为参数填入调用。
模型如何发现和加载 Skill:在实现上,Skills 通常通过模型启动时的系统消息或环境设置来告知模型有哪些技能可用。典型流程如下:
1.发现技能:模型的运行环境(例如 Claude Code、OpenCode CLI)会在启动时扫描预定的文件夹路径,将所有可用技能的 name 和 description 提取出来。在 Claude/Claude Code 中,这些信息会注入到系统提示中,让模型一开始就“知道”有哪些技能选项,但只以很简短的形式呈现,所以对话上下文开销很小。在 OpenCode 中,技能列表则体现在一个特殊的“技能工具”的描述里。例如 OpenCode 会提供一个内置工具叫 skill,它的功能说明中包含所有技能名称及描述。模型可以通过查看该工具描述了解到当前可用哪些技能。
2.决定调用:当用户的请求与某个技能的描述吻合时,模型会决定“激活”它。不同平台触发的方式略有不同:Claude 可以自动触发(隐式调用)——Claude 检测到用户请求涉及技能场景,就内部执行相应的读取操作;OpenCode/Codex CLI 则既支持隐式也支持显式调用,显式方式下用户可以在提示中明确要求使用某技能(比如在对话中输入 $skillName 或通过界面选择技能)。
3.加载技能内容:一旦决定使用某技能,模型/环境会将对应 SKILL.md 的完整内容注入到对话上下文中。实现上通常是让模型调用一个工具去读取文件。例如 Claude Code 里,技能触发实际上体现为 Claude 执行了一条 read file(或 open_file)命令来打开 技能名/SKILL.md。OpenCode 中,模型会调用 skill 工具并传入参数 { name: “技能名” } 来达到同样效果。无论何种方式,结果都是该 Skill 文件内容以一条新的系统/助手消息形式出现在对话历史里。
4.执行技能逻辑:Skill 内容进入上下文后,模型即可依据其中的指导继续完成用户请求。如果 Skill 包含需要运行的脚本(例如 scripts/ 内的代码),模型通常也会尝试执行。例如 Skill 正文可能指示:“运行脚本 scripts/do_X.py 完成数据处理”。Claude Code 或 ChatGPT 会在看到这提示后,在其工具环境中执行该脚本,获取结果再继续。。如果 Skill 提供了参考文件(如 reference.md),模型可能也会判断是否要打开阅读,以获取更详尽的信息。整个过程对用户是透明的——用户只看到模型最终产出的结果,而不知道其中模型临时加载了哪些技能、跑了多少代码。这降低了用户使用复杂 AI 能力的门槛。
举一个实际例子来串联:假如用户问 Claude,“请帮我分析这份 Excel 数据并制作图表”。Claude 启动时已加载了一个处理 Excel 的技能描述,该技能叫 “excel-analysis”,描述里提到当需要分析 Excel 时可用。Claude 识别出用户请求匹配这个场景,于是调用环境的文件系统读取了 excel-analysis/SKILL.md。该 Skill 正文里有指导:“使用 Pandas 读取 Excel,计算统计指标,然后用 Matplotlib 画图保存为 PNG”。Claude 于是继续运行 Skill 附带的 Python 脚本完成这些步骤,最后将结果图表发送给用户。整个过程中,我们并没有显式要求 Claude 调用某函数或 API,一切都是 Claude 根据 Skill“自觉”完成。这展示了 Skills 机制的强大之处:通过提供任务流程文档+可执行代码,让模型在复杂任务上表现得像一个训练有素的专家。
示例——“竞品分析 Skill”
流程图示意
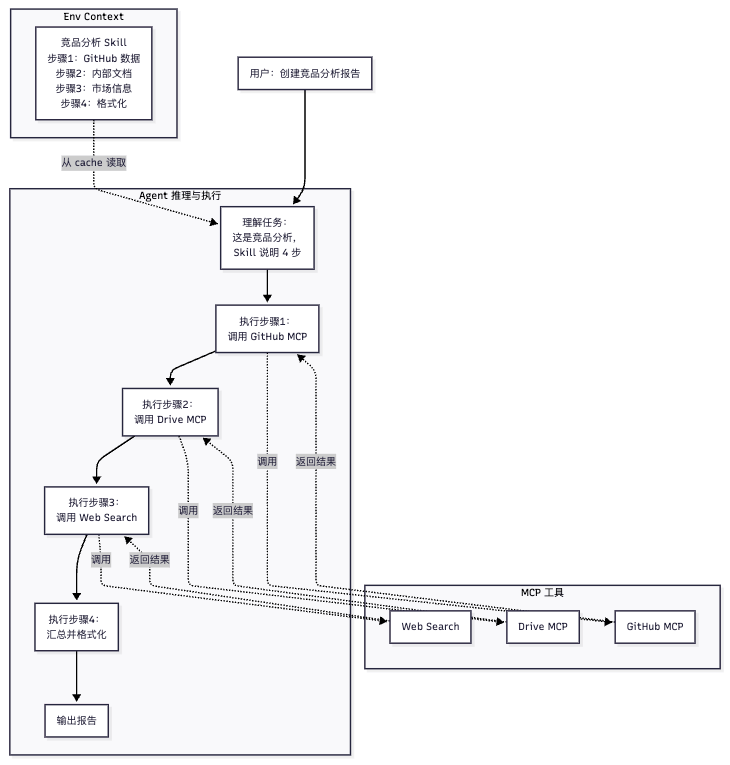
目录结构
1 | skills/ |
SKILL.md
1 | --- |
templates/report.md
1 | # 竞品分析报告(as of {{AS_OF_DATE}})- {{TARGET_NAME}} |
schemas/cache_index.schema.json
1 | { |
schemas/summary.schema.json
1 | { |
*Skills 集合——skillsmp
skillsmp是一个“Agent Skills(SKILL.md 标准)技能聚合/发现站”,核心定位类似“技能市场/目录”:把散落在 GitHub 各处的 Claude/Codex/ChatGPT Skills 聚合起来,方便你搜索、筛选、安装。
SkillsMP 在 About 里把痛点说得很直接:技能很多,但分散、难找、难判断质量,于是它做“发现与筛选”的入口。主页也强调:提供搜索、分类过滤、质量指标,帮助快速找到合适技能。
我们可以借助其找现成技能,快速扩展 AI 能力,一键安装到 Claude Code / Codex CLI / OpenCode 里用,也可以学习别人怎么写 Skill(作为写技能的参考库)。
五、如何编写高质量的 Skill
Skill 的威力虽然很大,但要充分发挥,需要精心的设计和打磨。下面我们结合 Anthropic 和社区提供的最佳实践,讨论编写高质量技能包应注意的要点:
- 明确的命名与描述:技能的名称和描述是模型决策的入口,必须清晰准确。名称最好能概括技能主题,例如“pdf-reader”“sql-query”等,长度短而有辨识度。描述则需要点明技能要做什么以及何时该用。Anthropic 建议描述不要泛泛而谈,应包含触发场景的关键词。例如:“Apply Acme Corp brand guidelines to presentations and documents” 这条描述清楚表明了应用场景(演示文稿和文档)。另外,从 OpenCode 社区经验来看,描述的措辞甚至可以带有引导性语气,以促使模型注意使用技能——比如在描述里使用“MUST”或“重要”等词强调必要性。有开发者分享说,把描述改成“You MUST load me before any commit”后,模型几乎每次在提交代码前都会调用对应技能。当然,要避免滥用夸张词,否则可能导致模型过于频繁地错误调用技能。总之,描述的策略是在 200 字符左右的限制内,既准确包含技能功能,又埋下足够的提示让模型联想到相关场景
- 合理的内容结构(Schema 设计):这里的“Schema”不是指 JSON Schema,而是 Skill 正文内容的组织。良好的结构能帮助模型快速抓住重点。可以考虑将 Skill.md 正文拆分成几个小节,例如:“What I do(我能做什么)”、“When to use me(何时使用)”、“Steps(步骤)”、“Examples(示例)”等,用二级或三级标题划分。在“What I do”部分列出技能提供的具体功能点,用简短 bullet points 描述,让模型了解能力边界。在“When to use me”部分说明触发条件,这能强化描述里已有的信息,让模型更精准判断时机。如果有示例输入/输出或模板格式,可以放在 Examples 部分,让模型模仿。这样的模块化写法既方便模型阅读,也利于日后维护扩充。另外,如果技能内容较多,Anthropic 建议使用渐进披露的思路,将不常用或互斥的内容拆到附加文件中,用超链接引用。这样当模型不需要那部分信息时,就不会占用主 SKILL.md 的宝贵上下文窗口。例如,在 PDF Skill 中,关于填写 PDF 表单的说明被移到了 forms.md,主 Skill.md 里只在需要时提示 Claude 打开它。这种结构优化可以让技能既详尽又高效。
- 提供调用上下文与约束:在 Skill 中,我们可以巧妙地为模型设置执行时的上下文信息,包括允许哪些操作、不允许哪些操作等。Anthropic Claude 的技能规范甚至支持在元数据里限定技能执行时可用的工具集合(Claude Code 的实现里有一个 allowed_tools 机制,用于防止技能滥用无关工具)。在 OpenCode 中,可以通过权限配置限制哪些技能可被哪些代理使用。作为技能作者,应在说明中明确模型该如何使用技能内的工具/脚本。例如:“Use the fetch_data function from this skill’s script to get the data” 这样的提示,确保模型不会偏离预期流程。同时,也可以在 Skill 中指定不要做什么,例如提示模型“请勿调用网络 API”或“遇到错误不要反复尝试超过 3 次”等等。如果技能需要依赖某些第三方库或特殊环境,也务必在元数据的 dependencies 字段注明(如 python>=3.8, pandas>=1.5.0),以便部署技能时准备好运行环境。总之,想象模型在没有人类监护的情况下执行技能,你需要在 Skill 里把边界和规则交代清楚。
- 数据校验与错误处理:高质量技能应尽可能涵盖可能出现的异常情况。尤其当技能涉及代码执行时,要考虑脚本的失败或异常输出。一个好的做法是在 Skill 的脚本部分加入验证与错误提示,并在 Skill 说明里指导模型如何应对。例如前面提到的 Slack GIF 技能,在脚本里检查生成的 GIF 大小是否超标,如果超标则输出警告信息。Claude 读取到这信息后,会根据 Skill 逻辑尝试重新调整参数生成更小 GIF。同样地,如果 Skill 需要读取文件,需考虑文件不存在或格式不符时模型该怎么办——可以在 Skill.md 里写上:“如果文件未找到,请礼貌地向用户报错”。再如当调用 API 失败时,Skill 可以建议模型重试一定次数或者输出缓存结果。利用 LLM 的灵活性,我们甚至可以指导模型自行 debug:Anthropic 提到,可以让 Claude 在用技能跑偏时自我反思哪里出错了,并把经验反馈进技能中。虽然让模型改写技能目前仍是前沿探索,但这种自省思路值得技能作者借鉴:在技能中加入检查点,让模型验证每步结果,一旦偏离预期就及时终止或纠偏,而不是盲目进行错误操作。实践中,多运行几次技能、收集模型输出是完善错误处理的好方法——观察模型在异常情况下的行为,针对性地在 Skill 中增加指导。经过充分打磨的技能,应当像稳健的函数一样:在合理输入下完成任务,在异常情况下优雅退出,不给用户带来困扰。
- 模型提示的设计技巧:Skills 毕竟还是以“提示”的形式在引导模型,因此编写时要遵循良好的提示设计原则。首先,语言上简明扼要、措辞专业但避免歧义。模型有时会错误解读人类语言中的模糊表述,所以尽量使用直接的指令语句。例如,“Step 1: Do X. Step 2: Do Y. If Z happens, do …”。必要时可以使用列表、表格、特殊格式来强化结构。Anthropic 的经验是,Claude 对于带有 XML 标签的提示遵从度更高,因为它被训练中过类似格式。因此在 Claude 的技能中,开发者常用
<tool>、<assistant>之类的标签包裹指令,让模型更严格地执行。而对于 OpenAI 的模型,使用 Markdown 代码块、分隔符等方式也能帮助模型理清步骤。其次,避免在 Skill 中加入与该任务无关的信息,以免干扰模型注意力。技能应该聚焦于完成当前任务的一系列要点,切忌把过多背景或聊天式的内容混进来(除非这些就是任务必须的)。再次,要考虑模型可能的误解点,提前在 Skill 中澄清。例如,如果技能涉及翻译代码注释,也许要提醒模型不要翻译代码本身。换位思考模型阅读 Skill 时的视角:哪些地方可能让模型困惑?它会不会忽略某个重要步骤?通过不断模拟模型执行技能,可以发现提示需要改进之处。 - 兼容性和可移植性设计:随着 Agent Skills 标准的推出,一个技能文件可能在不同平台上被使用。因此编写技能要考虑环境差异。例如,同样是执行 Shell 命令,Claude Code 用的是
<bash>工具,而 OpenCode 原生支持的是!bash或其它格式。理想情况下,你的技能应尽量使用通用的指令或者注明适配。可以在元数据里通过 compatibility 字段标记该技能针对哪个平台(比如 compatibility: claude 或 compatibility: opencode)。如果要编写跨平台技能,尽量避免依赖某一平台特有的工具。例如 Anthropic Claude 内置了 search 工具可以上网,而 OpenCode 可能没有;这种情况下,可以在 Skill 写法上检测环境:比如“如果没有 search 工具,则让用户自行提供资料”。另外,利用开源社区提供的翻译层也是办法之一。之前提到的“Superpowers”插件在 OpenCode 里做了一件事:替换 Anthropic 技能中的专有工具名为 OpenCode 对应工具。例如 Skill 里出现 TodoWrite 工具(Claude 的计划功能),Superpowers 就自动替换为 OpenCode 的 update_plan;Skill 工具调用替换为 OpenCode 的 use_skill。了解这些差异,有助于我们编写技能时尽量对症下药:要么针对特定平台优化写法,要么写得抽象一点,让平台自己去适配。总之,高质量的技能在不同环境下都应有合理表现,不会因为一点上下文差异就完全失效。 - 持续测试和迭代:最后,写完一个 Skill 并不意味着大功告成。AI 行为的随机性决定了技能效果需要反复验证。Anthropic 工程师建议从评估入手:先在没有技能的情况下观察模型哪一步做不到位,然后针对性地逐步加入技能内容调优。写完后,用多组示例测试模型是否会在正确场景激活技能、是否按照预期步骤执行。如果有条件,可以进行单元测试/评估 (eval):例如设计一系列不同复杂度的问题,看模型调用技能成功率。注意收集模型失败的 case,分析是技能描述不到位还是模型理解偏差,并相应改进。与其试图一开始就穷尽所有情况,不如采取渐进增强的策略:让模型和你“配合”打磨技能——当模型妥善完成某任务后,可以让它把用到的关键思路写入技能;当出错时,引导它分析原因,再把防止出错的措施写入技能。通过这样人机协作的循环,技能会越来越健壮。正如 Anthropic 所说:“Iterate with Claude”——把 Claude 当成共创伙伴,一起完善这些技能。
除此之外也需要注意官方推荐的内容 token 限制:

六、Skills 的发展趋势和未来前景
Agent Skills 技术虽然问世不久,但已展现出蓬勃的发展势头。展望未来,我们可以预见以下趋势:
- Skills 生态和自动化发现:随着 Anthropic 将技能规范开放,以及社区贡献大量技能范例,各平台有望出现技能市场或目录,方便共享和发现技能。有人在讨论中提到:“如果有一个带评论和评分的 Skills 市场,那将大大推动这项技术传播”。Anthropic 官方也表示,会致力于完善技能的完整生命周期支持,包括发现、分享等环节。未来我们也许能在类似 App Store 的平台浏览各类技能,一键安装到自己的 AI 代理中。与此同时,模型自动发现技能的能力可能出现——例如模型遇到未掌握的新任务时,能联网检索相应的技能包并请求用户确认后加载。这类似于人不会的就去搜教程的思路。技术上要实现这一点,需要解决技能的标准化描述和可信度评估问题,但开放标准已经迈出第一步。可以想见,一个繁荣的技能生态将极大丰富 AI 的即用能力库,让“小模型也能办大事”(通过加载专精技能来弥补参数规模不足)。
- 上下文驱动的 Skills 装配:当前的 Skills 主要以单一技能调用为单位,未来代理可能学会动态组合多个技能来应对复杂任务。这有点类似人类解决难题时会调用不同领域的专长。OpenCode 等已经支持子代理(Sub-agent)和多技能并行,如 Reddit 社区中有人用 Skills 让模型并行调用谷歌搜索获取深度资料。未来模型或许能根据上下文自动决定技能调用顺序,甚至在一次对话中串联多个技能(先用 Skill A 处理文本,再用 Skill B 分析结果)。这需要更强的规划与记忆能力,可能涉及和 Agent 规划算法结合。不过值得高兴的是,Skills 本身为这种流水线式智能提供了很好的模块封装。我们已经看到一些探索:比如 Anthropic 提到,会研究 Skills 如何与 MCP 等多步调用协议互补,教会代理处理涉及外部软件的复杂工作流。这暗示未来 AI 代理在拿到任务时,可能先通过内置 planner(或大模型 chain-of-thought)分解子任务,然后挑选合适的技能一步步执行——这和当前一些开源 Agent 框架(如 AutoGPT)试图让 AI 自己规划调用工具的思路不谋而合。有了技能这个高层抽象,agent 的自主决策空间将更加优化,自动化组装技能解决问题的时代值得期待。
- 多模态 Skills 和模型融合:今天的 Skills 主要围绕文本和结构化数据处理,但随着多模态大模型的发展,多模态技能可能会出现。例如,一个图像处理技能,里面包含如何调用图像识别模型或绘图工具的说明;一个语音助手技能,指导模型如何调用语音合成/识别引擎等。实际上,OpenAI 已经在尝试这方面:ChatGPT 的 PDF 技能通过将 PDF 转为图片,再利用具备视觉能力的 GPT 模型来解析,从而保留了格式和图像信息。这可以视作一种雏形的多模态 Skill 应用。未来,当多模态模型(如 Google Gemini 等)成为主流,技能中可以囊括处理视觉、音频的步骤,让 AI 真正成为全能助手。例如,“设计海报”技能可以指导模型调用绘图 API 生成初稿,再用视觉模型检查设计是否美观,再调整,如此循环。这需要跨模型协作,而技能文件恰好可以作为不同能力模型之间沟通的桥梁,因为它以一种人类可读、模型可解析的形式描述任务。在开放技能标准下,不排除未来出现技能级别的多模态接口,即一个技能既能被语言模型加载,其内嵌的脚本还能调用视觉模型 API。这会将 AI 能力提升到一个新的层次,真正实现多模态、多工具融合。
- 自主 Agent 与 Skills 的融合:2025 年被称为“AI Agents 元年”,各种定义的 Agent 层出不穷。Skills 的出现,无疑为 Agent 提供了更易用的能力插件。我们可能会看到,未来的 AI Agent 框架把技能当作原生单元,支持热插拔。Agent 可以根据用户目标动态加载相关技能,而不是预先写死在系统提示里的功能。另外还可以让代理自主地进化:Anthropic 展望未来,希望让“Agents to create, edit, and evaluate Skills on their own”。也就是说,让 AI 代理在执行任务中学会把自己的新知识提炼成技能,下次遇到类似问题就能自己调用。这几乎是在赋予 AI 一种“编写说明书教自己”的元能力。如果实现,AI 将具备持续改进的闭环:
执行任务 → 学到新模式 → 生产新技能 → 下次表现更好。这有点像人类在工作中总结沉淀方法论,只不过由 AI 自动完成。当然,实现这一点还有诸多挑战,包括保证 AI 编写的技能正确且不危害系统。不过一些早期迹象已经出现:OpenAI Codex 引入了 skill-creator 工具,可以根据用户描述自动生成技能骨架供开发者完善。这说明让 AI 参与技能编写并非天方夜谭。 - 更安全和精细的能力管控:随着技能赋予模型更多自主权,安全问题也不可忽视。未来的发展一方面会加强技能沙盒环境的安全隔离(例如执行代码的权限控制、资源使用限制等),另一方面会引入更细粒度的技能权限。OpenCode 已经实现了按模式(pattern)控制哪些技能可被使用,未来企业可能需要对技能做签名、验证,确保模型只能加载可信来源的技能。也可能出现技能审计工具,自动分析技能脚本是否存在恶意操作。这些配套措施将使技能生态在扩大的同时,安全性有保障。最终目标是建立可信的 AI 能力商店:用户/企业可以方便地获取所需技能,又不用担心其中暗藏风险。
展望:Skill 技术的出现,被很多业内人士视为 AI 应用的一个分水岭。一位开发者甚至称:“Skills 的出现也许比 MCP 更为重要”。因为它找到了一个几乎零门槛(写文档)的方式来持续提升 AI 能力,让专业人士可以将自己的 know-how 注入 AI。如果说预训练模型给予 AI 普遍的语言和常识,那么技能机制正在赋予 AI 一个连接人类具体经验和工具的接口。可以想象,不久的将来,不同领域会沉淀下丰富的技能库,AI Agent 可以像安装软件那样加载“法律咨询技能”“医学诊断技能”“编程调试技能”……AI 不再是一个通用的大脑,而可以瞬间学习各种“手艺”。这种灵活性和可扩展性,正是 Skill 技术的魅力所在。我们正迈向一个高度模块化、可组装的 AI 智能时代。在这个过程中,无论是开发者还是普通用户,都将因技能生态的繁荣而受益:前者更快捷地构建复杂应用,后者享受到更专业、更个性化的 AI 助手服务。
结语
Skills 技术展现了统一的趋势:让大模型变得更聪明、更勤劳、更听话。它汲取了软件工程的模块化思想,又融合了 Prompt 的灵活创造力,正在重塑人们对 AI 能力边界的想象。对于 AI 开发者来说,掌握 Skills 意味着掌握了一种新的编程范式——不再只是写代码给计算机执行,而是写“说明书”给 AI 去理解执行。而对于普通用户,将来或许一句话就能安装“新技能”到你的 AI 助手,让它完成以前无法企及的任务。Skills 为 AI 打开了一扇门,一扇通往无限可能的门。我们正站在门槛,目睹一个丰富多彩的 AI 技能世界徐徐展开。
其他相关链接
Skills Hub:https://skillsmp.com/、https://openaitoolshub.org/en/skillsmap
Awesome 集合:https://github.com/ComposioHQ/awesome-claude-skills、https://github.com/sickn33/antigravity-awesome-skills
Vercel 的 Skills:https://github.com/vercel-labs/agent-skills/tree/main/skills
Anthropic Agent Skills:https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills、https://github.com/anthropics/skills/tree/main/skills
Coze Skill:https://www.coze.cn/open/docs/guides/skill_overview
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com