大模型缓存技术工程指南(下):面向缓存命中的 Prompt 与 Agent 工程实践
上篇重点介绍了大模型缓存技术的基本机制,包括 KV Cache、Prompt Cache、Prefix Cache、Context Cache、Semantic Cache 等。本篇继续从工程视角展开:当模型厂商已经把“缓存命中”体现在 API 定价和延迟优化中时,工程团队应该如何组织 Prompt、工具定义、上下文和 Agent 平台能力,才能真正提高缓存命中率,并把缓存收益转化为可观测、可治理、可持续优化的工程能力。
目录
- 为什么缓存问题最终会变成 Prompt 工程问题
- 先区分:哪些缓存是工程侧能明显影响的
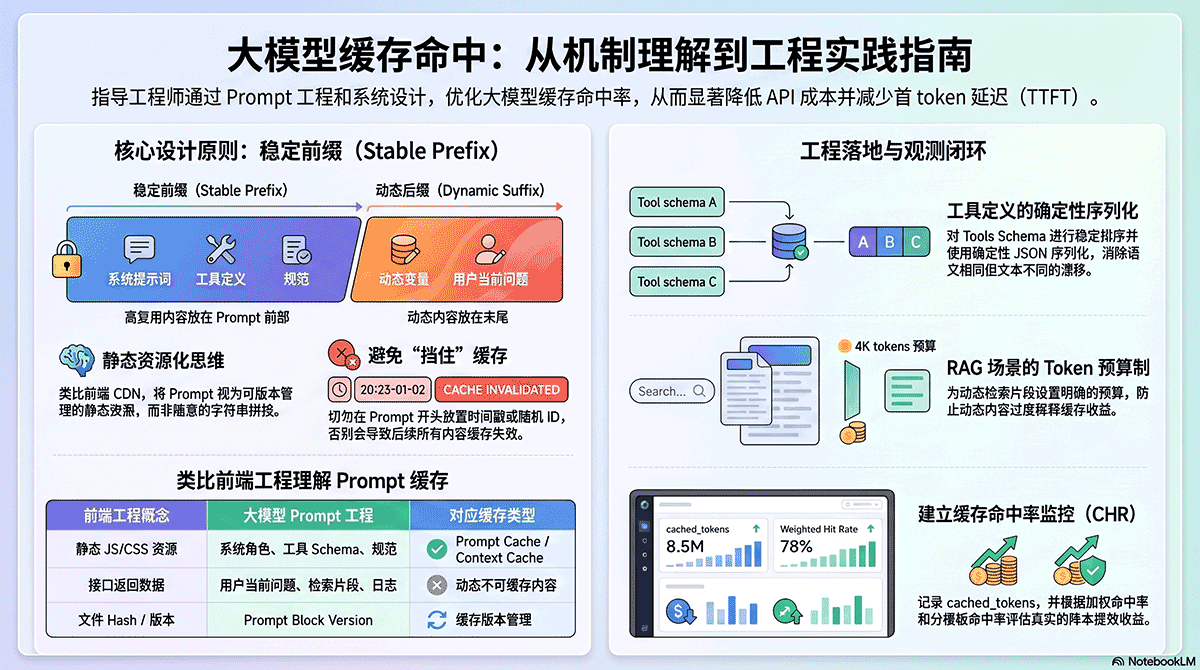
- 总原则:稳定前缀 + 动态后缀
- Prompt 结构推荐模板
- 固定角色和系统约束应该前置
- 不要把时间戳、随机 ID、Trace ID 放进稳定前缀
- 固定内容要版本化,而不是每次动态拼接
- Tools / Function Calling Schema 要稳定排序
- 减少”等价但不同写法”的 Prompt 漂移
- 哪些内容适合缓存
- RAG 场景的缓存实践
- 多轮对话中的缓存实践
- 显式 Context Cache 的工程管理
- 建设 Prompt Block Registry
- 建立缓存命中率和成本观测
- Prompt Lint:把缓存实践变成工程门禁
- 常见反模式清单
- 面向 Agent 平台的落地路线
- 推荐实践总结
TL;DR
一句话:缓存能不能命中,很大程度取决于工程侧如何组织 Prompt、工具定义、RAG 片段、多轮历史和 Agent 平台上下文。
工程实践要点:
- Prompt 要模块化和版本化
把 system prompt、工具定义、代码规范、DSL schema 拆成 Prompt Block,并维护 id / version / cachePolicy。
- Tools schema 要稳定
工具顺序、JSON key 顺序、description 内容都要稳定,否则语义一样也可能缓存不命中。
- RAG 结果要后置且控长
动态检索结果不要放最前面,也不要无限塞入。要做 topK、rerank、截断、去重和 token 预算控制。
- 多轮对话要摘要化
最近几轮保留原文,更早历史压缩成 summary。稳定 summary 可以靠前,易变状态要放后面。
- Context Cache 要做权限隔离
不能只存 cacheId,还要有 tenantId / projectId / accessControl / contentSensitivity / expiresAt 等信息。
要建立缓存观测指标
重点看:
1
2
3
4
5
6
| cached_input_tokens
cache_hit_ratio
TTFT
prefill_latency
cost_saving
prompt_template_version
|
Prompt Lint 可以做工程门禁
检查动态变量是否出现在前缀、tools 是否稳定排序、schema 是否稳定序列化、是否记录 cached tokens。
1. 为什么缓存问题最终会变成 Prompt 工程问题
很多工程同学第一次看到大模型厂商价格表里的 cached input、cache read、context cache 时,会自然地把它理解为“模型服务端帮我做了缓存”。这个理解没有错,但还不够。
从 API 使用者视角看,缓存是否命中,往往不只取决于模型厂商是否支持缓存,而取决于调用方如何组织请求内容。
尤其是 Prompt Cache / Prefix Cache / Context Cache 这类跨请求缓存,本质上都依赖一个前提:
如果每次请求的前缀都不同,即使其中包含大量重复信息,也可能无法很好地命中缓存。
举一个工程侧很常见的例子。
不利于缓存的组织方式:
1
2
3
4
5
6
7
8
| 当前时间:2026-05-18 10:23:12
请求 ID:req_8f3a9d
用户问题:帮我生成一个活动页
你是一个前端代码生成 Agent。
以下是公司前端规范……
以下是组件库说明……
以下是工具定义……
|
看起来这段 Prompt 里有大量固定内容,但因为最前面的时间、请求 ID、用户问题每次都变,后面的稳定内容就不容易形成可复用的相同前缀。
更适合缓存的组织方式:
1
2
3
4
5
6
7
8
9
10
11
| 你是一个前端代码生成 Agent。
以下是公司前端规范……
以下是组件库说明……
以下是工具定义……
---
本次请求上下文:
当前时间:2026-05-18 10:23:12
请求 ID:req_8f3a9d
用户问题:帮我生成一个活动页
|
这背后的核心思想非常像前端工程里的“静态资源缓存”:
1
2
3
| 稳定不变的资源要有稳定 URL / hash;
经常变化的数据要和静态资源分离;
不要因为一小段动态内容,让整份资源都失去缓存价值。
|
在大模型调用里也一样:
1
2
| 稳定 Prompt 前缀 ≈ 可缓存静态资源
动态用户上下文 ≈ 每次请求的数据载荷
|
因此,缓存优化不只是模型服务端能力,而是调用方上下文工程能力的一部分。
2. 先区分:哪些缓存是工程侧能明显影响的
从工程实践角度,可以把大模型缓存分为三类。
| 缓存类型 |
工程侧是否容易影响 |
主要影响方式 |
| KV Cache |
较弱 |
通常由推理引擎自动管理;工程侧主要通过控制上下文长度、输出长度、并发策略间接影响 |
| Prompt Cache / Prefix Cache |
很强 |
通过 Prompt 组织顺序、稳定前缀、工具定义排序、上下文拆分直接影响 |
| Context Cache |
很强 |
通过显式创建缓存、维护 cache id、版本和过期策略直接影响 |
| Semantic Cache |
很强 |
应用层自己实现,基于问题相似度或业务 key 复用答案 |
本篇重点讨论工程侧最能发力的两类:
1
2
| Prompt Cache / Prefix Cache
Context Cache
|
它们共同指向一个问题:
3. 总原则:稳定前缀 + 动态后缀
最重要的 Prompt 组织原则是:
1
2
| 稳定、复用率高、变化少的内容放前面;
动态、每次请求都不同的内容放后面。
|
推荐结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| [稳定前缀]
1. 平台级 system prompt
2. 固定角色设定
3. 固定输出规范
4. 固定安全规则
5. 固定工具定义 / function schema
6. 固定 DSL / 组件库 / 代码规范
7. 固定项目背景 / 长文档 / 知识库摘要
[动态后缀]
8. 当前用户问题
9. 当前任务状态
10. 当前文件 diff
11. 当前错误日志
12. 当前检索片段
13. 当前轮临时约束
|
这不是单纯的“写 Prompt 技巧”,而是一种工程分层方式。
可以类比前端页面:
| 前端工程 |
大模型 Prompt 工程 |
| 静态 JS/CSS 资源 |
稳定 system prompt、工具 schema、项目规范 |
| 接口返回数据 |
当前用户问题、当前错误日志、当前 diff |
| CDN 缓存 |
Prompt Cache / Context Cache |
| 文件 hash / version |
Prompt block version |
| cache miss |
Prompt 前缀变化导致无法复用 |
如果把所有内容随意拼成一个字符串,就像把 JS、CSS、接口数据、用户状态全部打进一个文件里。任何一点变化,都会导致整体缓存失效。
4. Prompt 结构推荐模板
对于 Agent 平台,可以建立一套统一 Prompt 模板。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| # System Role
你是一个公司内部研发 Agent,负责辅助完成需求分析、代码生成、代码审查和测试验证。
# Global Rules
- 必须优先遵守公司研发规范。
- 不确定时必须先读取上下文,不允许编造。
- 涉及危险操作时必须停止并请求确认。
- 输出必须结构化、可执行。
# Tool Definitions
{{stable_tools_schema}}
# Project Rules
{{stable_project_rules}}
# Code Style Guide
{{stable_code_style_guide}}
# DSL / Component Specification
{{stable_dsl_or_component_spec}}
---
# Runtime Context
当前项目:{{project_name}}
当前分支:{{branch_name}}
当前任务类型:{{task_type}}
# User Task
{{user_task}}
# Dynamic Context
{{retrieved_context}}
{{current_diff}}
{{error_logs}}
# Output Requirements
{{runtime_output_requirements}}
|
这个模板有几个关键点:
- 角色、规则、工具、项目规范、代码规范都在前面。
- 当前任务、当前 diff、错误日志、检索片段都在后面。
- 固定上下文和动态上下文之间有明确分隔。
- 后续可以对前半部分做版本管理、缓存统计和命中率优化。
5. 固定角色和系统约束应该前置
在 Agent 类产品里,以下内容通常是高复用的:
1
2
3
4
5
6
| - 你是什么角色
- 你要遵循哪些全局规则
- 你有哪些工具可以用
- 你应该如何输出
- 你不能做哪些危险操作
- 你应该遵守哪些团队规范
|
这些内容应该尽量放在 Prompt 的最前面。
推荐:
1
2
3
4
5
6
7
8
9
10
11
12
| 你是一个公司内部 AIGC 研发 Agent。
你需要遵循以下规则:
- 优先读取项目规范
- 修改代码前先分析影响范围
- 不允许执行危险命令
- 输出必须符合指定格式
以下是可用工具定义:
...
以下是公司前端规范:
...
|
不推荐:
1
2
3
4
5
6
7
| 本次用户问题:帮我修复一个样式问题
当前时间:2026-05-18 10:23:12
当前文件:src/pages/Home.tsx
你是一个公司内部 AIGC 研发 Agent。
以下是可用工具定义:
...
|
后者的问题是,真正稳定的内容被动态信息“挡在后面”,不利于缓存命中。
6. 不要把时间戳、随机 ID、Trace ID 放进稳定前缀
以下内容天然会破坏前缀稳定性:
1
2
3
4
5
6
| 当前时间:{{now}}
请求 ID:{{requestId}}
用户 ID:{{userId}}
会话 ID:{{sessionId}}
随机 nonce:{{nonce}}
Trace ID:{{traceId}}
|
不是说这些信息永远不能给模型,而是不要放在 Prompt 的最前面,尤其不要夹在稳定系统说明之前。
推荐做法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| [固定系统说明]
你是一个前端代码生成 Agent。
你需要遵守以下代码规范……
[固定工具定义]
……
[固定项目规范]
……
[动态请求上下文]
当前时间:{{now}}
请求 ID:{{requestId}}
用户输入:{{userPrompt}}
|
对于纯日志追踪字段,如果模型并不需要理解它们,最好不要放进 Prompt,而是放入业务日志、tracing 系统或 API metadata 中。
7. 固定内容要版本化,而不是每次动态拼接
工程系统里常见的 Prompt 拼接方式是:
1
2
3
4
5
6
7
| const prompt = `
${getRolePrompt()}
${getRulesFromDB()}
${getToolsSchema()}
${getProjectDocs()}
${userInput}
`;
|
这很直观,但容易产生几个问题:
1
2
3
4
5
| - getRulesFromDB 每次返回顺序可能不同
- tools schema 序列化字段顺序可能不同
- 不同业务方会插入不同版本的 system prompt
- 某些动态字段混入了固定规则块
- 很难知道缓存命中和哪个 Prompt 版本有关
|
更好的做法是把 Prompt 拆成版本化 block。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| export type PromptBlock = {
id: string;
version: string;
content: string;
cacheable: boolean;
};
const stableBlocks: PromptBlock[] = [
{
id: "system-role",
version: "v1.3.0",
cacheable: true,
content: SYSTEM_ROLE_PROMPT,
},
{
id: "frontend-rules",
version: "v2.1.0",
cacheable: true,
content: FRONTEND_RULES,
},
{
id: "tool-schema",
version: "v1.8.2",
cacheable: true,
content: stableStringify(TOOLS_SCHEMA),
},
];
const dynamicBlock: PromptBlock = {
id: "user-task",
version: "runtime",
cacheable: false,
content: userInput,
};
|
这样做的好处是:
1
2
3
4
5
| - 能区分哪些内容可缓存,哪些内容不可缓存
- 能追踪缓存命中率和 Prompt 版本的关系
- 能对 Prompt 变更做审计
- 能支持灰度实验
- 能减少多人维护导致的 Prompt 漂移
|
Agent 平台经常会动态注册工具,例如:
1
2
3
4
5
| read_file
write_file
search_code
run_tests
git_diff
|
如果每次 tools 数组顺序不同,即使工具语义完全一样,最终序列化出来的 token 序列也可能不同。
不稳定示例:
1
2
3
4
5
| [
{ "name": "run_tests" },
{ "name": "read_file" },
{ "name": "write_file" }
]
|
另一次请求:
1
2
3
4
5
| [
{ "name": "read_file" },
{ "name": "write_file" },
{ "name": "run_tests" }
]
|
对于人来说语义相同,对于缓存来说却可能是不同前缀。
推荐对工具定义做稳定排序:
1
2
3
4
5
6
7
8
9
10
| function normalizeTools(tools: ToolDefinition[]) {
return tools
.slice()
.sort((a, b) => a.name.localeCompare(b.name))
.map(tool => ({
name: tool.name,
description: tool.description.trim(),
parameters: sortJsonSchema(tool.parameters),
}));
}
|
同时,对 JSON schema 也要做稳定序列化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| function stableStringify(value: unknown): string {
if (Array.isArray(value)) {
return `[${value.map(stableStringify).join(",")}]`;
}
if (value && typeof value === "object") {
const obj = value as Record<string, unknown>;
return `{${Object.keys(obj)
.sort()
.map(key => `${JSON.stringify(key)}:${stableStringify(obj[key])}`)
.join(",")}}`;
}
return JSON.stringify(value);
}
|
生产环境注意:上面的 stableStringify 只是用于解释“稳定序列化”的简化示例,不建议直接复制到生产环境。真实 tools schema / OpenAPI / JSON Schema 可能包含 $ref 循环引用、多行 description、转义差异、数字精度差异、Unicode 规范化差异,以及不同 JSON 库的序列化行为差异。生产环境建议使用成熟的 deterministic JSON / canonical JSON 实现,例如 fast-json-stable-stringify、canonicalize,或结合 JSON Schema canonical form / schema bundling 工具处理 $ref、排序、格式化和版本化。
核心原则是:
1
| 同一组工具,在语义不变时,序列化后的文本也应该完全一致。
|
9. 减少“等价但不同写法”的 Prompt 漂移
下面这些表达对人类来说差异不大:
1
2
3
| 你是前端专家。
你是一个前端专家。
你是一名资深前端专家。
|
1
2
3
| 请返回 JSON。
请以 JSON 格式返回。
输出格式必须是 JSON。
|
但对于缓存来说,这些就是不同文本。
如果平台允许每个业务方、每个开发者随意写一版 system prompt,那么缓存命中率会变差,Prompt 质量也难以治理。
推荐建立统一模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # Role
你是一个资深前端工程 Agent。
# Rules
- 修改代码前必须先分析影响范围。
- 不确定时必须先读取相关文件。
- 不允许编造不存在的 API。
# Output Format
返回 Markdown,包含:
1. 问题分析
2. 修改方案
3. 风险点
4. 验证方式
|
业务侧只填写动态变量:
1
2
3
4
5
| # User Task
{{user_task}}
# Runtime Context
{{runtime_context}}
|
这样可以把 Prompt 从“个人经验文本”变成“平台可治理模板”。
10. 哪些内容适合缓存
以下内容通常非常适合进入 Prompt Cache / Context Cache:
1
2
3
4
5
6
7
8
9
10
11
12
| - 公司前端代码规范
- 组件库使用说明
- 低代码 DSL Schema
- amis / KAmis 规则说明
- AGENTS.md
- 项目 README
- API 设计规范
- 安全门禁规则
- 测试用例生成规范
- UI 设计系统规范
- 固定业务背景说明
- 固定输出格式说明
|
这些内容有几个共同特点:
1
2
3
4
| - 比较长
- 经常重复出现
- 不会每次请求都变
- 对模型输出质量有稳定影响
|
不适合放进稳定前缀的内容:
1
2
3
4
5
6
7
8
9
| - 当前用户问题
- 当前 git diff
- 当前报错日志
- 当前接口返回值
- 当前用户权限
- 最新新闻
- 实时价格
- 当前库存
- 临时实验参数
|
这些内容应该作为动态上下文放在 Prompt 后半部分,并且每次请求重新注入。
一个简单判断标准:
1
2
| 如果这段内容在 10 分钟后仍然大概率正确,可以考虑缓存;
如果这段内容每次任务、每个用户、每个环境都可能不同,不要放进稳定前缀。
|
11. RAG 场景的缓存实践
RAG 场景里,最容易出现一个误区:把每次检索出来的结果都放在最前面。
不推荐:
1
2
3
4
5
6
7
| [本次检索结果]
chunk 1...
chunk 2...
chunk 3...
[固定系统规则]
你是一个知识库问答 Agent...
|
因为检索结果通常每次都不同,会破坏后面固定规则的前缀稳定性。
推荐:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| [固定系统规则]
你是一个知识库问答 Agent...
[固定回答规范]
你必须基于资料回答,不能编造...
[固定产品背景 / 可缓存]
以下是产品 A 的稳定背景资料...
[本次动态检索结果]
chunk 1...
chunk 2...
chunk 3...
[用户问题]
...
|
RAG 中适合缓存的内容:
1
2
3
4
5
6
| - 固定产品手册
- 固定 API 文档
- 固定投研方法论
- 固定合规规则
- 固定项目知识库摘要
- 同一批用户反复查询的大型文档
|
不一定适合缓存的内容:
1
2
3
4
| - 每次 query 检索出来都不同的 topK chunks
- 带实时排序分数的检索结果
- 带时间戳的搜索结果
- 带用户个性化过滤条件的片段
|
除了“前后顺序”,RAG 还要控制动态区长度。检索结果即使放在后面,如果每次都拼入 8K、16K 甚至更长的 chunks,也会让不可缓存输入快速膨胀,稀释缓存收益,并拉高 prefill 延迟。
建议给动态检索区设置明确 token 预算,例如:
1
2
3
4
5
6
| 总上下文预算:32K tokens
稳定前缀预算:8K tokens
最近对话预算:4K tokens
动态 RAG 预算:4K~8K tokens
输出预留预算:4K tokens
安全余量:剩余部分
|
动态 RAG 区可以按以下方式控制:
1
2
3
4
5
6
7
| - topK 限制:不要盲目把 top20 / top50 全部塞入 prompt
- chunk 大小控制:避免单个 chunk 过大
- rerank 后截断:优先保留高相关片段
- 去重合并:合并高度相似或来自同一段落的片段
- 字段裁剪:只保留标题、正文关键段、来源,不带无关 metadata
- 摘要后注入:长片段先压缩成 query-focused summary
- 按优先级排序:强相关 > 权威来源 > 新鲜度 > 长度
|
可以用一个简单策略作为起点:
1
2
3
4
5
| 1. 检索 topK=20
2. rerank 到 top5
3. 每个 chunk 最多保留 600~1000 tokens
4. 总动态 RAG 区不超过当前上下文窗口的 20%~30%
5. 超出预算时优先截断低相关片段
|
这些数字不是固定标准,需要结合模型上下文窗口、业务准确性要求和成本目标调整。核心原则是:动态区要小而准,稳定前缀才有持续复用价值。
如果使用支持显式 Context Cache 的模型 API,可以把稳定大文档提前创建为 cache,然后后续请求只引用 cache id,再追加本次用户问题和动态检索结果。
12. 多轮对话中的缓存实践
多轮 Agent 对话常见结构是:
1
2
3
4
5
| system prompt
历史消息 1
历史消息 2
历史消息 3
当前用户问题
|
这类结构的问题不在于历史消息本身,而在于很多系统会不断改写 system prompt 或在最前面插入新的上下文。
更推荐的结构是:
1
2
3
4
5
6
| [固定 system prompt]
[固定工具定义]
[固定项目规则]
[历史消息摘要]
[最近 N 轮对话]
[当前用户问题]
|
对于长对话,不建议无限追加历史原文。可以采用:
1
2
3
4
| - 最近 N 轮保留原文
- 更早历史压缩成 summary
- 长期知识沉淀到 memory / skill / 项目文档
- 当前任务状态单独结构化维护
|
这里的 N 不宜写死。可以按上下文窗口和任务类型动态决定:
1
2
3
4
5
6
7
8
9
| 短上下文模型 / 简单问答:
保留最近 3~5 轮原文即可。
中等上下文 / 常规 Agent 任务:
保留最近 5~10 轮原文,较早历史进入 running summary。
长上下文 / 复杂研发任务:
保留最近关键步骤原文,而不是机械保留最多轮数;
对工具调用结果、文件修改、用户确认结论做结构化状态记录。
|
summary 的生成方式通常有三类:
1
2
3
4
5
6
7
8
9
10
11
| 模型生成:
使用当前主模型或轻量模型定期生成 running summary。
适合语义复杂、需要保留决策过程的 Agent 任务。
规则抽取:
从结构化事件中提取已确认需求、修改文件、接口信息、错误日志、待办项。
成本低、稳定性好,适合研发平台。
混合方式:
规则先抽取事实,模型再压缩成自然语言摘要。
适合既要准确事实,又要方便模型理解的场景。
|
摘要触发策略可以按 token 阈值而不是只按轮数:
1
2
3
| if history_tokens > max_history_budget:
summarize(older_messages)
keep_recent_messages_within(recent_window_budget)
|
例如:
1
2
3
4
5
6
7
8
| 上下文窗口:32K
稳定前缀:8K
动态 RAG:6K
输出预留:4K
历史消息预算:8K
最近原文窗口:4K
running summary:2K
安全余量:4K
|
summary 生成本身也有成本,应该纳入平台成本模型:
1
2
3
4
5
6
| 总成本 =
主请求成本
+ summary 生成成本
+ summary 更新频率带来的额外成本
- 历史压缩节省的重复输入成本
- 缓存命中提升带来的成本节省
|
工程实践中,summary 不一定每轮都更新。常见做法是“超过 token 阈值再更新”或“关键状态变化后更新”。如果 summary 内容在多轮内保持稳定,可以作为相对稳定的上下文块,放在最近消息之前;如果 summary 每轮都会变化,则不要放到最前面的稳定缓存前缀中,否则会破坏后续固定内容的缓存命中。
可以用以下标准判断 summary 是否“稳定”:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 内容 hash:
对 summary 文本或结构化 summary 做 hash。
如果连续多轮 hash 不变,可以认为它在当前阶段相对稳定。
版本字段:
给 summary 维护 summary_version。
只有关键事实变化、用户确认新约束、任务状态变化时才递增版本。
事件触发:
仅在需求变更、文件修改完成、接口约定变化、错误根因确认等关键事件后更新 summary。
人工/规则标记:
对研发 Agent,可以把“已确认需求”“已修改文件”“待办事项”等结构化字段单独维护。
只有这些字段变化时才认为 summary 需要更新。
|
一个实用策略是:把 summary 拆成两层。
1
2
3
4
5
6
7
| stable_summary:
较少变化的任务背景、已确认需求、项目约束。
可以放在相对靠前的位置。
volatile_state:
当前轮错误、最新工具调用结果、临时推理过程。
应放在动态区,不参与稳定前缀。
|
这样有三个好处:
1
2
3
| 1. 控制上下文长度
2. 提高稳定前缀复用概率
3. 避免历史噪声干扰当前任务
|
13. 显式 Context Cache 的工程管理
有些模型厂商支持显式 Context Cache,即先创建缓存,再在后续请求中引用。
这种模式更像传统后端里的缓存对象:
1
| 创建 cache -> 保存 cache id -> 后续请求引用 cache id -> 过期或版本变化后重建
|
适合场景:
1
2
3
4
5
| - 针对一本长文档持续问答
- 针对一个代码仓库持续分析
- 针对一份产品手册持续生成客服回复
- 针对一个设计系统持续生成页面
- 针对一批合规规则持续做审核
|
不适合场景:
1
2
3
4
| - 一次性请求
- 上下文每次都不同
- 文档经常变化
- 用户隔离要求强但缓存隔离设计不清晰
|
13.1 缓存元数据不要只存 cacheId
推荐维护更完整的缓存元数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| export type AccessScope = "private" | "project" | "tenant" | "public";
export type ContextCacheRecord = {
cacheId: string;
provider: "openai" | "anthropic" | "gemini" | "vertex" | string;
model: string;
sourceType: "document" | "codebase" | "rules" | "design-system";
sourceId: string;
sourceVersion: string;
tenantId: string;
projectId?: string;
owner: string;
accessScope: AccessScope;
accessControl: {
allowedTenantIds?: string[];
allowedProjectIds?: string[];
allowedUserIds?: string[];
allowCrossTenantReuse: boolean;
};
contentSensitivity: "public" | "internal" | "confidential" | "restricted";
cachePolicy: {
ttlSeconds: number;
allowReuse: boolean;
allowCrossProjectReuse: boolean;
};
createdAt: string;
expiresAt: string;
};
|
关键是不要只保存一个 cache id,而要保存:
1
2
3
4
5
6
7
8
| - 这个 cache 对应哪份文档
- 文档版本是什么
- 使用哪个 provider / model 创建
- 什么时候过期
- 属于哪个 tenant / project
- 创建人是谁
- 敏感级别是什么
- 是否允许跨用户、跨项目、跨租户复用
|
其中 owner 只能表示“谁创建或维护了这个 cache”,不应该承担权限隔离语义。多租户场景下,更明确的权限字段应该是 tenantId、projectId、accessScope 和 accessControl。
contentSensitivity 的语义也要提前定义清楚,尤其是 internal:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public:
可公开内容,原则上允许跨租户复用,但仍需检查 model、sourceVersion、TTL 和 allowCrossTenantReuse。
internal:
内部内容,但“内部”的边界必须明确。
在公司级平台中,它可能表示公司内部;
在多租户平台中,它更应该表示当前 tenant 内部;
在 BU / 项目隔离场景中,它可能只能在当前 project 内部复用。
confidential:
机密内容,默认不允许跨租户、跨项目复用。
restricted:
高敏内容,默认只允许创建者或明确授权对象使用。
|
因此,internal 不应天然等同于“全平台可复用”。如果平台存在租户隔离,建议默认把 internal 限制在同一 tenantId 内;只有明确标记为 public 且通过跨租户复用审核的内容,才允许跨租户共享。
13.2 cacheKey 设计建议
如果平台自己管理 cache registry,可以用类似下面的 key 结构:
1
2
3
4
5
6
7
8
9
10
| cacheKey =
provider
+ model
+ sourceType
+ sourceId
+ sourceVersion
+ tenantId
+ projectId?
+ accessScope
+ cachePolicyHash
|
这样可以避免几个常见问题:
1
2
3
4
5
| - 同一文档不同版本误用同一个 cache
- 不同模型误用同一个 cache
- 不同租户误用同一个 cache
- TTL / cache policy 变化后仍复用旧 cache
- 项目私有文档被其他项目引用
|
13.3 跨租户共享前的检查逻辑
跨租户共享 Context Cache 要非常谨慎。一个保守判断流程可以是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| function canReuseContextCache(
record: ContextCacheRecord,
request: {
tenantId: string;
projectId?: string;
userId: string;
model: string;
now: string;
},
): boolean {
const notExpired =
new Date(record.expiresAt).getTime() > new Date(request.now).getTime();
const sameModel = record.model === request.model;
if (!sameModel || !notExpired) {
return false;
}
if (record.contentSensitivity === "confidential") return false;
if (record.contentSensitivity === "restricted") return false;
if (record.accessScope === "private") {
return record.accessControl.allowedUserIds?.includes(request.userId) ?? false;
}
if (record.accessScope === "project") {
return Boolean(
request.projectId &&
record.accessControl.allowedProjectIds?.includes(request.projectId),
);
}
if (record.accessScope === "tenant") {
return record.tenantId === request.tenantId;
}
if (record.accessScope === "public") {
const explicitlyShareable =
record.contentSensitivity === "public" &&
record.accessControl.allowCrossTenantReuse === true;
return sameModel && notExpired && explicitlyShareable;
}
return false;
}
|
跨租户共享缓存前,至少要确认:
1
2
3
4
5
6
| - 缓存内容不包含用户私有信息、未公开代码、敏感业务数据
- provider / 内部 serving 是否支持明确的租户隔离语义
- cache id 是否会在日志、usage、错误信息中泄露
- sourceVersion 变化后会重建或失效旧缓存
- TTL 合理,过期后不会继续引用
- 权限变更后能主动撤销或标记不可复用
|
需要强调的是:不同模型厂商对 cache 对象、cache id、组织隔离、项目隔离的抽象并不完全相同。平台侧不能假设“有 cache id 就天然安全隔离”,而应该在自己的缓存元数据和调用链路中补上权限判断。
如果团队对 internal 的边界没有统一定义,建议先按最保守策略处理:internal 仅在同一 tenant 内复用;跨 tenant 复用必须显式升级为 public,并通过敏感信息检查和审批。
否则后续很容易出现缓存污染、版本错乱和权限问题。
14. 建设 Prompt Block Registry
对于公司级 AIGC 平台,不建议让每个业务方自己手写完整 Prompt。更好的方式是建设 Prompt Block Registry。
示例结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| export type CachePolicy = "stable-prefix" | "explicit-cache" | "dynamic";
export type PromptBlockDefinition = {
id: string;
name: string;
version: string;
content: string;
cachePolicy: CachePolicy;
owner: string;
updatedAt: string;
};
const promptBlocks: PromptBlockDefinition[] = [
{
id: "platform-agent-role",
name: "平台 Agent 角色定义",
version: "1.0.0",
content: "...",
cachePolicy: "stable-prefix",
owner: "aigc-platform",
updatedAt: "2026-05-18",
},
{
id: "frontend-code-rules",
name: "前端代码规范",
version: "2.3.1",
content: "...",
cachePolicy: "stable-prefix",
owner: "frontend-platform",
updatedAt: "2026-05-18",
},
{
id: "current-user-task",
name: "当前用户任务",
version: "runtime",
content: "{{user_task}}",
cachePolicy: "dynamic",
owner: "runtime",
updatedAt: "runtime",
},
];
|
Prompt Block Registry 可以承担以下能力:
1
2
3
4
5
6
7
8
| - prompt 拼接顺序控制
- 缓存策略标记
- 版本管理
- 命中率统计
- 成本分析
- 灰度实验
- prompt 变更审计
- 多业务复用
|
这会把 Prompt 从“散落在代码里的字符串”升级为“平台级上下文资产”。
15. 建立缓存命中率和成本观测
如果只是调整 Prompt,但没有观测,很难证明收益。
建议每次模型调用记录以下字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| request_id
provider
model
prompt_template_id
prompt_template_version
input_tokens
cached_input_tokens
cache_hit_ratio
output_tokens
time_to_first_token
end_to_end_latency
estimated_input_cost
estimated_cached_input_cost
estimated_saving
cacheable_block_ids
dynamic_block_tokens
|
其中,cache_hit_ratio 建议区分三个统计口径:
1
2
3
4
5
6
7
8
| 单请求命中率:
cached_input_tokens / input_tokens
平台级加权命中率:
sum(cached_input_tokens) / sum(input_tokens)
模板级命中率:
按 prompt_template_id / prompt_template_version 分组后分别统计
|
不要简单对请求命中率做算术平均。不同模板的输入长度和调用频率差异很大,算术平均可能掩盖真实成本结构;平台级成本分析应优先看加权命中率和分模板命中率。
核心看板可以包括:
| 指标 |
说明 |
| Cache Hit Ratio |
单请求:cached_input_tokens / input_tokens;平台级:sum(cached_input_tokens) / sum(input_tokens) |
| Cached Input Tokens |
命中的缓存输入 token 数 |
| TTFT |
Time To First Token,首 token 延迟 |
| Prefill Latency |
长 Prompt 处理耗时 |
| Cost Saving |
缓存命中带来的成本节省 |
| Template Version |
哪个 Prompt 模板版本命中率更高 |
| Dynamic Token Ratio |
动态内容占比,过高会影响缓存收益 |
对于 Agent 平台,可以按场景拆分观察:
1
2
3
4
5
6
7
| - 代码生成 Agent
- Code Review Agent
- 测试用例生成 Agent
- 需求分析 Agent
- 竞品分析 Agent
- 低代码 DSL 生成 Agent
- 运营页面生成 Agent
|
不同场景的缓存收益差异会很大。比如:
1
2
3
| 代码生成 Agent:工具定义、代码规范、项目规则复用率高,缓存收益通常较好。
竞品分析 Agent:每次检索网页内容不同,缓存收益可能较弱。
低代码 DSL 生成 Agent:DSL schema 和组件规范稳定,缓存收益通常较好。
|
16. Prompt Lint:把缓存实践变成工程门禁
为了避免缓存优化只停留在口头规范,可以在平台里加入 Prompt Lint。
示例检查规则:
1
2
3
4
5
6
7
8
9
10
| 1. 禁止在稳定前缀 token 窗口内出现 current_time / request_id 等动态变量
2. 检测稳定前缀中的疑似硬编码时间戳、trace id、uuid、随机 nonce
3. tools schema 必须按 name 排序
4. JSON schema 必须稳定序列化
5. system prompt 必须引用版本化 block
6. RAG dynamic chunks 不允许出现在 stable prefix 前
7. 固定规范类 block 必须标记 cacheable
8. dynamic block 不允许标记 cacheable
9. prompt_template_version 必须存在
10. 每次请求必须记录 cached_input_tokens
|
需要注意,Prompt Lint 里说的“前 1024 tokens”必须基于 tokenizer 计算,不能用字符数近似。中文、英文、代码、JSON schema 的 token 密度差异很大,slice(0, 8000) 这类字符截断只能作为调试预览,不能作为 token 边界判断。
renderPreview() 也需要有最低实现要求,否则 Lint 很容易漏检。建议它至少满足:
1
2
3
4
5
6
7
| 1. 使用与线上一致的 block 拼接顺序。
2. 展开所有静态 block 和工具 schema。
3. 对动态变量使用带语义的占位符,而不是空字符串。
例如用 {{current_time}}、{{request_id}}、{{user_task}}。
4. 对高风险动态变量提供测试样例值。
例如 current_time = 2026-05-18 10:23:00,request_id = req_xxx。
5. 输出应尽量接近真实请求形态,包括 role、tools、system、user 等结构。
|
不推荐:
1
| renderPreview 时把所有动态字段替换为空字符串。
|
这样会让 Lint 无法发现动态字段出现在稳定前缀的问题。更好的做法是给每类变量一个可识别的占位符或样例值,让 Lint 能同时检测模板变量和疑似硬编码动态值。
示例伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| function lintPromptTemplate(
template: PromptTemplate,
tokenizer: { encode(input: string): number[]; decode(tokens: number[]): string },
): string[] {
const errors: string[] = [];
const renderedPrompt = template.renderPreview();
const tokens = tokenizer.encode(renderedPrompt);
const stablePrefixTokens = tokens.slice(0, 1024);
const stablePrefixText = tokenizer.decode(stablePrefixTokens);
const dynamicPlaceholders = [
"{{current_time}}",
"{{request_id}}",
"{{trace_id}}",
"{{session_id}}",
"{{nonce}}",
];
for (const placeholder of dynamicPlaceholders) {
if (stablePrefixText.includes(placeholder)) {
errors.push(`${placeholder} 不应出现在稳定前缀 token 窗口中`);
}
}
const suspiciousRuntimePatterns = [
/\b\d{4}-\d{2}-\d{2}[ T]\d{2}:\d{2}/,
/\b[0-9a-f]{8}-[0-9a-f]{4}-[1-5][0-9a-f]{3}-[89ab][0-9a-f]{3}-[0-9a-f]{12}\b/i,
/\b(trace|request|session)[_-]?(id)?[:=][\w-]{8,}\b/i,
];
for (const pattern of suspiciousRuntimePatterns) {
if (pattern.test(stablePrefixText)) {
errors.push("稳定前缀中疑似包含硬编码时间戳、trace id 或随机标识");
break;
}
}
if (!template.version) {
errors.push("prompt template 必须声明 version");
}
if (!isToolsSorted(template.tools)) {
errors.push("tools 必须按 name 稳定排序");
}
if (template.blocks.some(block => block.cacheable && block.type === "dynamic")) {
errors.push("dynamic block 不应标记为 cacheable");
}
return errors;
}
|
这段代码仍然只是示例,不是完整的静态分析器。它有几个天然局限:
1
2
3
4
5
| - 只能检测已知模板变量名,无法覆盖所有自定义变量
- 硬编码时间戳、trace id、uuid 只能用启发式正则发现,可能误报或漏报
- token 边界必须依赖目标模型 tokenizer,不同模型 tokenizer 可能不同
- renderPreview 如果没有按线上拼接顺序展开静态 block、工具 schema 和动态变量占位符,也可能漏掉运行时注入内容
- 多语言、转义、JSON schema、工具描述文本会增加检测难度
|
因此,Prompt Lint 更适合作为“工程门禁 + 风险提示”,而不是绝对正确的安全证明。生产环境建议结合:
1
2
3
4
5
| - 模板变量白名单 / 黑名单
- Prompt Block 类型系统
- 运行时采样审计
- usage 指标异常检测
- 代码评审或配置审核
|
这些规则可以集成到:
1
2
3
4
5
| - Agent 平台发布流程
- Prompt 模板变更审核
- CI 检查
- 管理后台配置校验
- 运行时告警
|
17. 常见反模式清单
| 反模式 |
问题 |
推荐修正 |
| 每次把当前时间放在 Prompt 开头 |
破坏前缀一致性 |
放到 Runtime Context 后面 |
| tools 数组顺序随机 |
token 序列不稳定 |
按工具名稳定排序 |
| JSON schema 字段顺序不稳定 |
内容语义相同但文本不同 |
使用 stable stringify |
| system prompt 每个业务方随意改 |
模板不可控,缓存命中低 |
建立版本化模板 |
| RAG 片段放在最前面 |
检索结果每次变,破坏稳定前缀 |
固定规则前置,检索结果后置 |
| 把请求 ID、trace ID 放进 Prompt |
对模型无帮助,还破坏缓存 |
放入日志 metadata |
| 长文档每次重复传但不做缓存管理 |
成本高、延迟高 |
显式 context cache 或稳定前缀 |
| 历史对话无限追加 |
成本越来越高,缓存收益下降 |
摘要压缩 + 最近 N 轮原文 |
| 为了缓存复用过期事实 |
可能导致错误答案 |
易变事实动态注入 |
| Prompt 模板没有版本 |
无法做命中率对比和问题回滚 |
引入 prompt_template_version |
18. 面向 Agent 平台的落地路线
对于 Agent 平台,缓存优化可以分三步推进。
18.1 第一阶段:规范 Prompt 结构
目标是先减少明显破坏缓存的写法。
重点动作:
1
2
3
4
5
| - 固定 system prompt 前置
- 动态任务信息后置
- 移除前缀中的时间戳、request id
- tools schema 稳定排序
- 建立统一输出格式模板
|
这个阶段投入较小,适合作为快速治理动作。
18.2 第二阶段:建设 Prompt Block Registry
目标是把 Prompt 变成平台资产。
重点动作:
1
2
3
4
5
| - 将角色定义、工具定义、代码规范、DSL schema 拆成 block
- 每个 block 有 id、version、owner、cachePolicy
- 统一拼接顺序
- 支持模板版本发布和回滚
- 支持不同业务场景复用
|
这个阶段可以显著提升 Prompt 管理能力。
18.3 第三阶段:建立观测和优化闭环
目标是让缓存收益可量化。
重点动作:
1
2
3
4
5
| - 记录 cached_input_tokens
- 记录 cache_hit_ratio
- 记录 TTFT 和端到端延迟
- 按模型、模板、业务场景统计成本节省
- 对命中率低的模板做 Prompt Lint 和优化建议
|
这个阶段可以把缓存优化和平台成本治理结合起来。
19. 推荐实践总结
可以把本文实践压缩成一句话:
进一步展开:
1
2
3
4
5
6
7
| Prompt 模板稳定化
→ Prompt Block 版本化
→ Tools Schema 稳定化
→ 长文档 Context Cache 化
→ 动态上下文后置化
→ 缓存命中率可观测化
→ 成本和延迟收益可量化
|
最终目标不是“所有内容都缓存”,而是构建一套面向大模型调用的上下文工程体系:
| 层级 |
建设内容 |
| 规范层 |
Prompt 编写规范、稳定前缀规则、动态上下文规则 |
| 平台层 |
Prompt Block Registry、模板版本管理、Context Cache 管理 |
| 观测层 |
cached tokens、命中率、TTFT、成本节省、模板对比 |
| 治理层 |
Prompt Lint、变更审计、灰度实验、回滚机制 |
缓存优化并不是一个孤立的性能技巧,而是大模型工程化的重要组成部分。对于 Agent 平台、AIGC 研发平台、低代码生成平台来说,它会直接影响三件事:
1
2
3
| 1. 成本:相同上下文不必反复付全价。
2. 延迟:长 Prompt 的 prefill 成本可以被部分复用。
3. 稳定性:Prompt 模板版本化后,更容易治理和复盘。
|
当模型厂商已经把缓存命中写进价格表,工程团队也应该把缓存命中写进 Prompt 规范、平台能力和观测体系里。
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com