大模型缓存技术工程指南(上):从价格信号到推理缓存机制
May 16, 2026笔记ai大模型缓存技术工程指南(上):从价格信号到推理缓存机制
版本说明:本文为“上篇”三次优化版,面向工程团队理解大模型缓存技术的底层机制、成本含义和系统设计边界。本文会少量出现 Prompt 组织示例,但仅用于解释缓存机制;系统化 Prompt / Agent 工程实践放在下篇展开。
时效性提示:本文涉及的模型厂商缓存价格、TTL、最低 token 门槛、支持模型范围、API 字段名称具有较强时效性(2026-05)。价格与 API 行为仅用于解释机制和工程决策,不应直接作为预算依据。正式成本测算请以调用时的官方 Pricing 页面、模型文档和 API 返回的
usage字段为准。
目录
- 为什么从“缓存价格”讲起
- 先澄清:价格表里的 Cache 通常是哪种 Cache
- 工程分层视角下的大模型缓存版图
- 大模型推理的两个阶段:Prefill 与 Decode
- KV Cache:单次生成内部的推理缓存
- PagedAttention:KV Cache 的显存管理机制
- Prefix Cache / Prompt Cache / Context Cache:跨请求复用的缓存
- 应用层缓存:Semantic Cache 与 Response Cache
- 缓存策略适用场景对比
- 与缓存相关但不等同于缓存的推理优化技术
- 工程观测指标与成本测算方式
- 常见误区
- 工程落地示例
- 附录:厂商缓存价格与产品形态示例
- 参考资料
TL;DR
一句话:大模型缓存分很多层:KV Cache 是模型内部加速生成,Prompt / Prefix / Context Cache 是跨请求复用稳定上下文,Semantic / Response Cache 是应用层复用答案。
核心要点:
- 价格表里的 cached input 通常不是 KV Cache
厂商说的 cached input / cache read 多数指 Prompt Cache、Prefix Cache 或 Context Cache。 - KV Cache 解决生成时的重复计算
Prefill 阶段生成并保存 K/V,Decode 阶段复用历史 K/V,避免每生成一个 token 都重算全部上下文。 - KV Cache 很吃显存
显存大致随这些因素线性增长:层数 × KV heads × head_dim × 上下文长度 × batch size。所以长上下文和高并发会显著增加 serving 成本。 - PagedAttention 是 KV Cache 的显存管理方案
它像操作系统分页一样,把 KV Cache 切成 block,减少显存碎片,并支持 prefix block 复用。 - Prompt / Prefix Cache 优化的是重复输入
如果多个请求有相同前缀,比如固定 system prompt、工具定义、代码规范,就可以复用这部分 prefill 结果。 - Context Cache 更像显式缓存对象
适合长文档、代码仓库、设计系统、固定知识库等反复使用的上下文。 - Semantic / Response Cache 是应用层缓存
FAQ、客服、知识库问答可以直接复用历史答案,但要注意时效、权限和误命中风险。
1. 为什么从“缓存价格”讲起
过去我们谈大模型成本时,常见口径是:
1 | 总成本 ≈ 输入 token 成本 + 输出 token 成本 |
但随着长上下文、Agent、多轮工具调用、RAG、代码仓库分析等场景变多,输入 token 中有大量内容是重复的:
1 | - system prompt |
于是模型厂商逐渐在价格表里显式区分:
1 | input tokens |
这件事本身是一个非常重要的信号:
缓存已经不是推理系统内部的“实现细节”,而是大模型 API 成本模型、Prompt 组织方式和 Agent 平台架构设计中的一等公民。
对于工程团队来说,这会带来三个直接问题:
- 为什么同样是输入 token,有些 token 会便宜很多?
- 价格表里的
cached input到底对应哪种缓存? - 我们在设计 Prompt、Agent、RAG、低代码生成平台时,应该如何让缓存更容易命中?
本文上篇重点回答前两个问题:缓存机制是什么、它们分别解决什么问题、工程上该如何区分。
下篇再重点讨论:如何组织 Prompt 和 Agent 上下文,让缓存真正命中。
2. 先澄清:价格表里的 Cache 通常是哪种 Cache
大模型技术里有很多“缓存”概念:
1 | KV Cache |
这些名字很容易混在一起。尤其是很多工程同学第一次看到 OpenAI、Anthropic、Gemini 价格表里的 cached input、cache read、context caching price 时,会自然以为它们指的都是同一种技术。
实际上需要先区分:
| 问题 | 答案 |
|---|---|
| 单次生成过程中,模型为了避免重复计算历史 token 的缓存是什么? | KV Cache |
| 多个请求之间,如果 prompt 前缀相同,复用已经计算过的前缀状态是什么? | Prefix Cache / Prompt Cache |
| 厂商 API 中显式创建、后续引用的大上下文缓存是什么? | Context Cache |
| 应用层根据问题相似度直接复用答案是什么? | Semantic Cache / Response Cache |
价格表中的 cached input、cache read、context cache,通常指的是:
1 | 跨请求复用稳定输入上下文的缓存 |
也就是 Prompt Cache、Prefix Cache 或 Context Cache 这一类,而不是单次请求内部的 KV Cache。
2.1 KV Cache 与 Prompt Cache 的关系
可以这样理解:
1 | KV Cache: |
它们并不是完全割裂的。很多 Prompt Cache / Prefix Cache 的底层实现,本质上仍然在复用已经计算好的 KV 状态。区别在于:
1 | KV Cache 更偏模型推理过程; |
3. 工程分层视角下的大模型缓存版图
本文不再使用“严格 MECE 分类”这个表述。原因是 Prompt Cache、Prefix Cache、Context Cache 在机制和产品形态上高度重叠,Semantic Cache 和 Response Cache 也可能重叠。
更准确的说法是:
本文采用工程分层分类:从模型推理层、推理服务层、API 产品层、应用层四个层级理解缓存。不同缓存策略之间可能重叠,但分层有助于工程决策。
| 层级 | 典型缓存 | 主要解决的问题 | 工程关注点 |
|---|---|---|---|
| 模型推理层 | KV Cache | 单次生成内部避免重复计算历史 token | 显存占用、长上下文、batch size、decode 延迟 |
| 推理服务层 | PagedAttention、Prefix Cache、RadixAttention | 多请求复用、显存碎片、并发调度 | block 管理、LRU、ref count、prefix 命中 |
| API 产品层 | Prompt Cache、Context Cache | 降低重复输入成本和首 token 延迟 | prompt 顺序、TTL、cache read/write、usage 统计 |
| 应用层 | Semantic Cache、Response Cache | 直接减少模型调用 | 相似度阈值、失效策略、正确性风险 |
从工程视角看,这四层分别对应不同问题:
1 | 模型推理层:模型怎么少算? |
4. 大模型推理的两个阶段:Prefill 与 Decode
理解缓存前,必须先理解大模型生成的两个阶段。
4.1 Prefill:处理输入 prompt
当用户发送一个 prompt,例如:
1 | 你是一个前端专家,请根据以下设计规范生成 React 组件…… |
模型需要一次性处理整段输入,计算每个输入 token 的中间状态,并为后续生成准备 Key / Value。
这个阶段通常称为 Prefill。
Prefill 的特点:
1 | - 和输入 prompt 长度强相关 |
4.2 Decode:逐 token 生成输出
Prefill 完成后,模型开始一个 token 一个 token 生成答案。
例如:
1 | 第 1 步生成:我 |
这个阶段称为 Decode。
Decode 的特点:
1 | - 和输出长度强相关 |
4.3 缓存分别作用在哪里
| 缓存 | 主要作用阶段 | 解决的问题 |
|---|---|---|
| KV Cache | Prefill + Decode | Prefill 阶段生成并保存输入 token 的 K/V;Decode 阶段复用历史 K/V 并追加新 token 的 K/V |
| Prefix / Prompt Cache | Prefill | 多请求之间复用相同 prompt 前缀 |
| Context Cache | Prefill | 显式复用长文档、长上下文 |
| Semantic / Response Cache | 模型调用前 | 直接跳过或减少模型调用 |
需要特别注意:KV Cache 不是只在 Decode 阶段才存在。更准确地说:
1 | Prefill 阶段: |
因此,工程上常说“KV Cache 优化 Decode”,主要是因为它最直观地避免了 decode 每一步重算历史 token;但从生命周期看,KV Cache 贯穿 Prefill 和 Decode 两个阶段。
一个简化链路:
1 | 用户请求 |
5. KV Cache:单次生成内部的推理缓存
5.1 基本原理
Transformer 自回归生成时,每生成一个新 token,都需要关注前面已经出现过的 token。
如果没有 KV Cache,模型生成第 N 个 token 时,可能需要反复计算前面 1 到 N-1 个 token 的 Key / Value。这样历史越长,重复计算越多。
KV Cache 的核心思想是:
1 | 历史 token 的 Key / Value 一旦计算出来,就缓存下来。 |
类比前端工程:
1 | 没有 KV Cache: |
当然这个类比只是帮助理解,真实模型中缓存的是注意力层中的张量,不是组件树。
5.2 KV Cache 解决什么问题
KV Cache 的生命周期贯穿 prefill 和 decode:prefill 阶段生成并保存输入 token 的 K/V,decode 阶段复用这些历史 K/V 来避免重复计算。因此它最直接解决的是 decode 阶段的历史 token 重算问题,同时也是 Prompt / Prefix Cache 能跨请求复用前缀状态的底层基础之一。
适合场景:
1 | - 所有自回归生成场景 |
不适合把它理解成:
1 | - 降低 API 价格表中 cached input 的唯一原因 |
KV Cache 通常由模型推理框架、模型服务或厂商后端管理,普通 API 调用者很少直接操作它。
5.3 KV Cache 显存占用如何估算
KV Cache 最大的问题不是“是否能缓存”,而是“缓存太占显存”。
工程上可以用一个近似公式估算:
1 | KV Cache Memory |
其中:
| 参数 | 含义 |
|---|---|
2 |
Key 和 Value 两份缓存 |
num_layers |
Transformer 层数 |
num_kv_heads |
K/V head 数 |
head_dim |
每个 head 的维度 |
seq_len |
上下文长度 |
batch_size |
并发序列数 |
bytes_per_element |
数据类型占用字节数,如 FP16/BF16 通常为 2 |
这个公式解释了为什么长上下文和高并发会快速吃掉显存:
1 | seq_len 增加 2 倍 → KV Cache 近似增加 2 倍 |
一个速查示例:
1 | 假设某 7B 级模型: |
这只是单个 batch、4K 上下文下的 KV Cache 量级。如果上下文扩展到 32K,或者 batch size 从 1 提升到 16,KV Cache 会线性放大。实际 serving 中还要叠加模型权重、激活、中间 buffer、调度开销和框架预留显存,因此长上下文并发能力经常首先受限于 KV Cache。
5.4 MHA / MQA / GQA / MLA 对 KV Cache 的影响
注意公式里用的是 num_kv_heads,而不是简单的 num_heads。这是因为不同 attention 架构对 K/V head 的设计不同。
| 架构 | 简化理解 | 对 KV Cache 的影响 |
|---|---|---|
| MHA,Multi-Head Attention | 每个 Q head 都有独立 K/V | KV Cache 最大 |
| MQA,Multi-Query Attention | 多个 Q head 共享一组 K/V | 显著降低 KV Cache |
| GQA,Grouped-Query Attention | 多组 Q head 共享少量 K/V | 在效果和显存间折中 |
| MLA,Multi-head Latent Attention | 用 latent 表示压缩 K/V 信息 | 进一步降低缓存压力 |
对工程人员来说,这个点很重要。两个模型参数量接近,但如果 attention 结构不同,在长上下文和高并发 serving 下的显存压力可能完全不同。
这里尤其要避免两个误解:
1 | 1. MQA 和 GQA 不是完全并列、互不相关的设计。 |
5.5 KV Cache 的工程挑战
KV Cache 带来的挑战包括:
1 | 1. 显存占用巨大 |
因此推理框架不仅要“有 KV Cache”,还要有高效的 KV Cache 管理机制。这就是 PagedAttention、Prefix Cache、RadixAttention 等技术出现的背景。
6. PagedAttention:KV Cache 的显存管理机制
6.1 为什么需要 PagedAttention
如果把每个请求的 KV Cache 都当作一段连续显存来分配,会遇到类似操作系统内存管理中的问题:
1 | - 请求长度不同 |
vLLM 的 PagedAttention 借鉴了操作系统分页思想,把 KV Cache 切成固定大小的 block。逻辑上一个请求的上下文是连续 token 序列,但物理上它的 KV Cache block 可以分散在不同显存位置。
6.2 核心概念
| 概念 | 含义 |
|---|---|
| block / page | 固定大小的 KV Cache 存储单元,通常容纳若干 token 的 K/V |
| block table | 记录逻辑 token 位置到物理 KV block 的映射 |
| non-contiguous memory | 逻辑连续,物理不要求连续 |
| reference count | 记录某个 block 被多少请求引用 |
| copy-on-write | 多请求共享前缀时,只有发生分叉才复制或追加 |
| LRU eviction | 显存不足时按策略淘汰较少复用的 block |
类比操作系统:
1 | 虚拟内存: |
6.3 PagedAttention 解决什么问题
PagedAttention 的价值不是改变模型输出,而是提升 serving 效率:
1 | 1. 降低显存碎片 |
vLLM 官方文档中,Automatic Prefix Caching 的设计也建立在 KV cache blocks 的复用之上:已经处理过的请求会留下 KV cache blocks,新请求如果有相同 prefix,就可以复用这些 blocks。
6.4 一个简化例子
假设 block size = 4 tokens。
请求 A:
1 | Prompt A: [A, B, C, D, E, F] |
可以拆成:
1 | Block 1: [A, B, C, D] |
请求 B:
1 | Prompt B: [A, B, C, D, E, G] |
它与请求 A 的前 5 个 token 相同,但如果只缓存完整 block,那么至少:
1 | Block 1: [A, B, C, D] 可以复用 |
这也说明了一个工程事实:
Prefix Cache 往往不是“相同多少字符就能全部命中”,实际命中粒度可能受 block size、tokenization、hash 规则、cache eviction 等因素影响。
7. Prefix Cache / Prompt Cache / Context Cache:跨请求复用的缓存
7.1 Prefix Cache 的基本原理
Prefix Cache 的核心是:
1 | 如果新请求和历史请求拥有相同前缀, |
例如:
请求 1:
1 | [固定 system prompt] |
请求 2:
1 | [固定 system prompt] |
两者前面三段完全一致。Prefix Cache 可以复用这部分已经计算好的结果,只处理用户问题 A/B 的差异部分。
7.2 Prompt Cache 与 Prefix Cache 的关系
在很多厂商 API 中,Prompt Cache 是 Prefix Cache 的产品化表达。
OpenAI 文档明确建议:把静态或重复内容放在 prompt 开头,把变量内容放在结尾;缓存命中依赖 exact prefix match。OpenAI 当前 Prompt Caching 文档说明,缓存对 1024 tokens 及以上的 prompt 可用,低于该长度的请求也会返回 cached_tokens 字段但通常为 0;不过具体模型、平台和供应商网关可能存在差异,正式实现仍应以当前文档和实际 usage 为准。
从工程角度看:
1 | Prefix Cache: |
7.3 Context Cache 的产品化形态
Gemini / Vertex AI 这类产品中,Context Cache 更像是显式上下文资产:
1 | 1. 先把长文档、长背景、视频、代码等上下文创建成 cache |
这类方式适合:
1 | - 针对同一份长文档反复问答 |
它和 OpenAI 自动 Prompt Cache 的区别主要是:
| 维度 | 自动 Prompt Cache | 显式 Context Cache |
|---|---|---|
| 开发者是否显式创建 cache | 通常不需要 | 需要 |
| 是否有 cache ID | 通常没有或弱化 | 通常有 |
| 是否关注 exact prefix | 是 | 也关注内容一致性,但产品抽象更强 |
| 适合场景 | 重复 prompt 前缀 | 大文档、多次引用、长上下文资产 |
7.4 Prompt Cache 主要优化 Prefill,不优化长输出 Decode
这是一个非常关键的边界。
如果你的请求是:
1 | 输入很长,输出较短 |
Prompt Cache 的收益通常明显,因为它减少了长输入的 prefill 成本。
如果你的请求是:
1 | 输入很短,输出很长 |
Prompt Cache 的收益会有限,因为主要耗时和成本在 decode / output tokens 上。
vLLM 文档也明确指出,Automatic Prefix Caching 主要减少 query processing / prefilling 阶段的时间,不会减少生成新 token 的 decode 时间。
8. 应用层缓存:Semantic Cache 与 Response Cache
前面几类缓存主要在模型或推理服务层。应用层也可以做缓存。
8.1 Response Cache
Response Cache 最像传统后端缓存:
1 | key = 完全相同请求 |
适合:
1 | - FAQ |
风险:
1 | - 用户上下文不同但请求文本相同,答案可能不应相同 |
8.2 Semantic Cache
Semantic Cache 不要求问题完全一致,而是基于 embedding 或语义相似度判断。
例如:
1 | 问题 A:如何配置 Codex 的 baseURL? |
语义相似,可以复用或半复用已有答案。
适合:
1 | - 客服 |
风险:
1 | - 相似不等于相同 |
8.3 Response Cache 与 Semantic Cache 的重叠
这两者不是互斥关系:
1 | 完全相同请求命中 Response Cache; |
因此更合理的理解是:
1 | Response Cache 是精确匹配缓存; |
9. 缓存策略适用场景对比
| 场景 | 最适合的缓存 | 原因 |
|---|---|---|
| 单次长输出生成 | KV Cache | Decode 阶段必须复用历史 K/V |
| 长 system prompt + 多个用户问题 | Prompt / Prefix Cache | 稳定前缀重复,prefill 可复用 |
| 同一长文档反复问答 | Context Cache / Prefix Cache | 长文档可以作为稳定上下文 |
| Agent 多轮工具调用 | Prompt Cache + KV Cache | system/tools/rules 稳定,历史上下文可部分复用 |
| 代码仓库分析 | Context Cache / Prefix Cache | README、规范、项目结构可复用 |
| FAQ 客服 | Semantic Cache / Response Cache | 可以直接减少模型调用 |
| 实时行情 / 最新新闻 | 不建议长期缓存答案 | 数据时效性强,容易过期 |
| 输出很长、输入很短 | KV Cache 更关键 | Prompt Cache 对成本帮助有限 |
| 多租户工具 schema 相同 | Prompt Cache | tools 可共享缓存,但要注意租户隔离 |
| 低代码 DSL 生成 | Prompt Cache / Context Cache | DSL schema、组件规范、设计规范稳定 |
10. 与缓存相关但不等同于缓存的推理优化技术
评估文章技术深度时,容易把很多 serving 优化都归为缓存。这里做一个边界说明。
| 技术 | 是否缓存策略 | 与缓存的关系 |
|---|---|---|
| FlashAttention | 不是缓存策略 | 优化 attention 计算和显存访问 |
| Chunked Prefill | 不是缓存本身 | 把长 prompt 的 prefill 分块调度,提高并发和吞吐 |
| Continuous Batching | 不是缓存本身 | 动态合批,提高 GPU 利用率 |
| Speculative Decoding | 不是缓存策略 | 用小模型草稿 + 大模型验证,加速 decode |
| StreamingLLM | 不是通用缓存策略 | 面向长序列流式推理,通过 attention sink 等机制保留少量关键历史状态,与 KV Cache 管理相关但不等同于 Prompt/Prefix Cache |
| H2O / KV Cache 压缩 | 是 KV Cache 优化 | 选择性保留重要 token 的 KV,降低显存占用 |
| KV Cache Quantization | 是 KV Cache 优化 | 用更低精度存储 K/V,降低显存占用 |
| Prefix Cache | 是缓存策略 | 多请求复用前缀 KV blocks |
| PagedAttention | 是缓存管理机制 | 管理 KV Cache block,降低碎片,提高复用 |
10.1 为什么要提这些技术
因为真实推理系统的延迟和成本不是单一缓存决定的。
一个线上 LLM serving 系统通常同时依赖:
1 | KV Cache |
因此,Prompt Cache 命中率高不代表整体延迟一定最低;如果输出很长,decode 仍然是瓶颈。如果显存紧张,KV Cache 淘汰频繁,prefix 命中也可能不稳定。
10.2 Chunked Prefill 与 Prefix Cache 的协作关系
Chunked Prefill 和 Prefix Cache 经常同时出现在推理服务中,但它们解决的问题不同。
1 | Prefix Cache: |
两者同时开启时,可以理解为:
1 | 原始长 prompt |
这也解释了一个常见现象:
即使开启了 Prefix Cache,TTFT 仍然可能不稳定。
原因可能包括:
1 | - 只有部分前缀命中,剩余未命中部分仍然较长 |
所以工程上观察缓存效果时,不应只看 cache_hit_rate,还要结合 prefill_latency、queue_time、TTFT、num_cached_blocks、kv_cache_eviction_count 等指标一起判断。
11. 工程观测指标与成本测算方式
缓存优化不能只靠“感觉”。需要可观测。
11.1 API 层指标
建议记录:
1 | model |
不同厂商字段名不同,但核心关注点类似:
1 | 输入 token 中有多少被缓存命中? |
11.2 推理服务层指标
如果你自建 vLLM / SGLang / TensorRT-LLM 这类 serving,需要关注:
1 | prefix_cache_hit_rate |
11.3 成本测算口径
一个更合理的成本模型:
1 | 总成本 = |
不要只看 total_tokens。在启用缓存后,同样数量的 input tokens,可能对应不同价格:
1 | input tokens: 1.0x |
11.4 Break-even 思维
以一个抽象模型说明:
1 | 普通输入价格 = 1.0x |
不用缓存:
1 | 成本 = N × 1.0 |
使用缓存:
1 | 成本 = W + (N - 1) × R |
缓存划算的条件:
1 | W + (N - 1) × R < N |
这个公式比记厂商价格更重要。因为厂商价格会变,但判断逻辑不变。
12. 常见误区
误区 1:只要有 cached input,最终答案就是缓存答案
不是。
Prompt Cache 通常缓存的是输入前缀的中间状态,不是最终回答。模型仍然会根据当前动态输入生成新的输出。
误区 2:Prompt Cache 能降低所有成本
不是。
Prompt Cache 主要降低重复输入部分的成本和 prefill 延迟。输出 token 成本仍然存在,长输出任务收益可能有限。
误区 3:KV Cache 和 Prompt Cache 是同一个东西
不是同一层概念。
1 | KV Cache:单次生成内部复用历史 K/V。 |
但 Prompt Cache 的底层可能复用 KV cache blocks。
误区 4:应用层可以直接控制模型内部 KV Cache
通常不行。
使用厂商 API 时,开发者通常只能通过 prompt 组织、cache_control、context cache、retention policy 等产品接口间接影响缓存命中。
误区 5:缓存一定安全无风险
缓存也有风险:
1 | - 过期内容被复用 |
误区 6:分类必须严格互斥
不需要。工程上更有价值的是知道每类缓存在哪一层、解决什么问题、由谁控制、如何观测。
13. 工程落地示例
本节不再放复杂的“自制 KV Cache 模拟代码”。因为真实 KV Cache 涉及张量、显存布局、attention kernel、block table、调度器等,简单 TypeScript Map 难以提供工程价值。
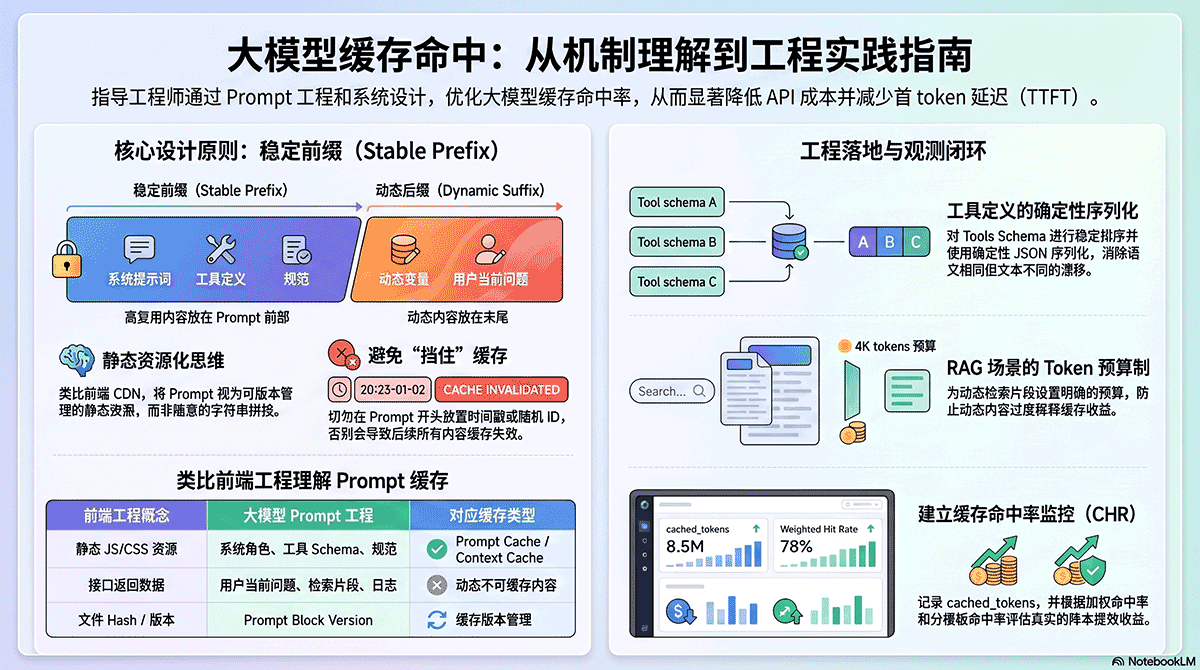
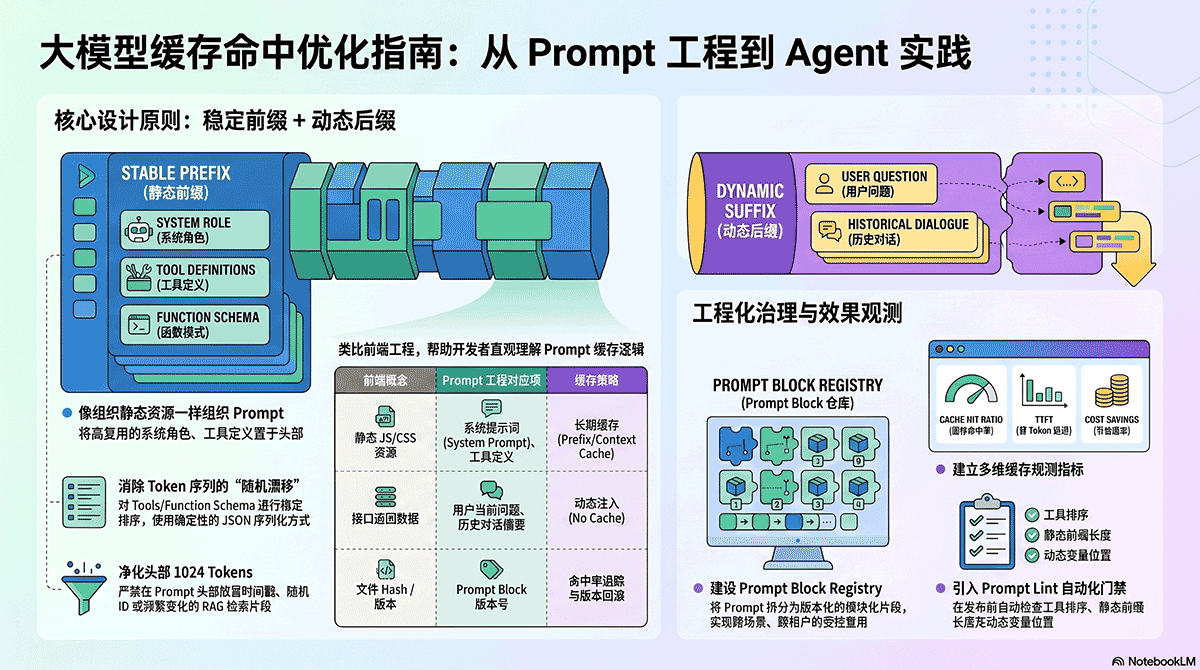
这里改为提供更贴近实际落地的示例。注意,本章示例只用于说明“缓存如何在工程系统中被启用和观测”,不会系统展开 Prompt 组织方法;稳定前缀、动态后缀、模板治理、Prompt Lint 等内容放到下篇讨论。
13.1 OpenAI:观测 cached_tokens
注意:具体 SDK 字段、模型名、缓存 retention 参数可能随版本变化,请以当前 SDK 和 API 文档为准。下面的模型名仅为示例占位符。OpenAI 当前文档同时提到 Responses API 和 Chat Completions 都可以返回缓存命中信息;新项目可优先参考 Responses API,存量项目如果仍在使用 Chat Completions,可以沿用
messages结构。
Responses API 示例:
1 | import OpenAI from "openai"; |
Chat Completions 风格示例:
1 | const chat = await client.chat.completions.create({ |
工程上要重点记录:
1 | usage.input_tokens / usage.prompt_tokens |
13.2 Anthropic:显式 cache_control
注意:以下示例展示结构思路。具体模型名、SDK 字段和 TTL 选项请以 Anthropic 当前文档为准。下面的模型名仅为示例占位符。
1 | import Anthropic from "@anthropic-ai/sdk"; |
工程要点:
1 | - 把稳定长上下文放在 cache_control 之前 |
13.3 vLLM:开启 Automatic Prefix Caching
1 | vllm serve Qwen/Qwen2.5-7B-Instruct \ |
或者在 Python 中:
1 | from vllm import LLM, SamplingParams |
适合测试:
1 | - 开启/关闭 prefix caching 的 TTFT 差异 |
13.4 应用层 Semantic Cache 示例结构
下面的代码只展示语义缓存的决策流程,不代表生产级实现。生产环境通常不应该对全量缓存记录逐条遍历计算相似度,而应先通过向量数据库或 ANN 索引召回 TopK 候选,再对候选做 TTL、权限、相似度阈值和业务约束校验。
1 | type CachedAnswer = { |
注意:这类缓存不能用于高风险、强时效、强权限隔离的问题,除非有非常严格的校验。即使语义相似度很高,也建议在关键场景增加二次校验,例如权限校验、文档版本校验、数据更新时间校验、答案引用来源校验等。
14. 附录:厂商缓存价格与产品形态示例
本节仅作为机制说明,不作为预算依据。
大模型厂商价格、模型名、TTL、缓存门槛、支持范围变化很快,请以调用时官方文档为准。
14.1 OpenAI Prompt Caching
OpenAI 当前 Prompt Caching 文档的关键点包括:
1 | - 自动启用,无需额外代码 |
工程含义:
1 | OpenAI 更偏“自动缓存 + 开发者优化 prompt 结构 + 观测 cached_tokens”。 |
14.2 Anthropic / Claude Prompt Caching
Anthropic 当前 Claude API Pricing 文档中,Prompt Caching 价格倍率示例包括:
| 操作 | 当前官方文档示例倍率 |
|---|---|
| 5-minute cache write | 1.25× base input price |
| 1-hour cache write | 2× base input price |
| Cache read / hit | 0.1× base input price |
这说明在当前 Anthropic 官方文档口径下,“5 分钟写入 1.25 倍、1 小时写入 2 倍、cache read 0.1 倍”这一描述是成立的。但需要明确:
1 | - 这是 Anthropic 当前产品规则,不是所有厂商通用规则 |
工程含义:
1 | Anthropic 更偏“显式 cache_control + TTL 选择 + cache write/read 分开计费”。 |
14.3 Gemini / Vertex AI Context Caching
Gemini / Vertex AI 的 Context Caching 更偏显式缓存大上下文:
1 | - 先创建 cached content |
工程含义:
1 | Gemini / Vertex AI 更偏“把长上下文作为可管理资产”。 |
14.4 不同产品形态的工程差异
| 厂商形态 | 典型特征 | 工程关注点 |
|---|---|---|
| 自动 Prompt Cache | 无需显式创建 cache | prompt 前缀稳定、cached_tokens 观测 |
| 显式 cache_control | 开发者标记缓存断点 | cache block 切分、TTL、write/read 成本 |
| 显式 Context Cache | 创建并引用 cache 对象 | cache 生命周期、版本、权限、存储成本 |
| 自建 Prefix Cache | serving 框架管理 KV blocks | block size、LRU、ref count、显存 |
15. 参考资料
官方文档
OpenAI Prompt Caching
https://developers.openai.com/api/docs/guides/prompt-cachingOpenAI API Pricing
https://openai.com/api/pricing/Anthropic Claude API Pricing
https://docs.anthropic.com/en/docs/about-claude/pricingAnthropic Prompt Caching
https://docs.anthropic.com/en/docs/build-with-claude/prompt-cachingGemini API Context Caching
https://ai.google.dev/gemini-api/docs/cachingVertex AI Context Cache Overview
https://cloud.google.com/vertex-ai/generative-ai/docs/context-cache/context-cache-overviewvLLM Automatic Prefix Caching
https://docs.vllm.ai/en/stable/features/automatic_prefix_caching/vLLM Automatic Prefix Caching Design
https://docs.vllm.ai/en/latest/design/prefix_caching/vLLM Paged Attention
https://docs.vllm.ai/en/latest/design/paged_attention/Hugging Face Transformers Cache Explanation
https://huggingface.co/docs/transformers/cache_explanationHugging Face Transformers KV Cache Strategies
https://huggingface.co/docs/transformers/en/kv_cache
延伸资料
Hugging Face: KV Cache Quantization
https://huggingface.co/blog/kv-cache-quantizationSGLang Documentation
https://docs.sglang.ai/SGLang RadixAttention
https://docs.sglang.ai/basic_usage/radix_attention.htmlLMSYS Blog: Fast and Expressive LLM Inference with RadixAttention
https://lmsys.org/blog/2024-01-17-sglang/
结语
大模型缓存不是单一技术,而是一组跨层优化:
1 | 模型推理层:KV Cache 解决单次生成内部重复计算 |
上篇的重点是理解这些缓存分别位于哪一层、解决什么问题、有什么边界。文中少量 Prompt 示例只服务于解释缓存机制,不展开治理方法。
下篇的重点则是:如何在 Prompt、Agent、RAG、低代码生成平台中组织稳定上下文,让缓存真正命中,并把命中率、成本节省和延迟收益纳入平台治理。
Author
My name is Micheal Wayne and this is my blog.
I am a front-end software engineer.
Contact: michealwayne@163.com